За последние несколько месяцев я заметил одну черту каждой новой концепции, которую я изучаю в информатике: у всего есть свои недостатки.
На самом деле, я полагаю, что это на самом деле черта программного обеспечения в целом и, честно говоря, любого творческого и технического ремесла. Пишем ли мы совсем немного кода или проектируем большую и сложную систему, у нас всегда есть из чего выбрать. Уловка, конечно же, заключается в том, чтобы знать, какой инструмент подходит для работы. И чтобы действительно хорошо разбираться в процессе принятия решений по выбору правильного инструмента, мы должны знать, каковы его преимущества и недостатки, чтобы дать справедливую оценку.
Хеш-таблицы, которые мы недавно обнаружили, действительно являются отличным вариантом для быстрого хранения и извлечения определенных данных. Они не всегда лучший инструмент для работы - например, они не подходят для поиска упорядоченных данных - но иногда они могут значительно облегчить нашу жизнь. Мы уже знаем, что хеш-таблица состоит из двух частей: массива, в котором хранятся все данные, которые мы хэшируем, и хеш-функции, которая решает, куда будут отправляться все эти данные. Однако хеш-таблицы по сути имеют некоторые собственные проблемы, и полезность хеш-таблицы напрямую связана с ее хеш-функцией. Хеш-функции могут быть несколько сложными, особенно если вы не знакомы с различными типами функций, которые существуют.
Итак, давайте узнаем больше о хэш-функциях, о том, как они работают, а также об их сильных и слабых сторонах. Надеюсь, это поможет нам понять, когда именно они могут нам помочь!
Хеш-таблица, хеш-таблица, у вас все хорошо?
Лучший способ решить, является ли что-то решением вашей проблемы, - это сначала понять, что это за штука хорошо работает. Другими словами, чтобы мы могли решить, когда хэш-таблицы желательны (и, конечно, когда это не так), нам нужно посмотреть, что делает хорошую хеш-таблицу, а затем использовать чтобы помочь нам решить, на правильном ли мы пути.
Итак, мы должны ответить на один вопрос: что делает хеш-таблицу хорошей? К счастью, ответ на этот вопрос по большей части довольно прост.

В конечном счете, удобство использования хеш-таблицы для решения проблемы с хранилищем и последующим поиском по всем этим данным зависит от того, насколько хороша хеш-функция в хеш-таблице.
Давайте разберем это утверждение еще дальше. Хорошая хеш-таблица всегда должна:
- иметь хэш-функцию, которую легко вычислить
- иметь хеш-функцию, которая избегает коллизий
- иметь хэш-функцию, которая каждый раз возвращает один и тот же ключ, когда ему задано значение, и иметь возможность использовать все входные данные
Итак, мы можем принять это за чистую монету ... но я думаю, что лучше спросить, почему.
Что ж, у хеш-таблицы должна быть простая для вычисления функция, потому что все, что слишком сложно вычислить, займет слишком много времени и места! Дорогостоящая функция не позволяет найти эффективную структуру данных, так что это действительно имеет смысл. Хеш-функция должна иметь возможность обрабатывать все данные и хранить их все, когда они вводятся, потому что, если это не так ... ну, это также нарушит цель структуры данных, которая может очень быстро хранить большие объемы данных! А если хеш-функция не возвращала каждый раз один и тот же ключ? Что ж, это было бы очень плохо, потому что мы никогда не сможем получить данные после того, как мы их сохранили, потому что мы никогда не могли быть уверены, где они находятся!
Хорошо, остается только столкновение. Возможно, вы помните с прошлой недели, что столкновение происходит, когда два элемента должны быть вставлены в одно и то же место в массиве.
В приведенном ниже примере хеш-функция довольно проста: она берет количество символов в слове, суммирует их, а затем делит общее количество символов на размер хеш-таблицы (который равен 10). Используя оператор по модулю, он использует остаток от этого деления, чтобы найти правильный хеш-сегмент для элемента, который мы пытаемся сохранить. Обратите внимание, что мы сталкиваемся с двумя последними элементами, так как мы не можем хранить два из них в одном месте!

Почти все хэш-функции в какой-то момент столкнутся с конфликтом. Единственная ситуация, когда это не так, - это идеальная хэш-функция, где каждое отдельное входное значение отображается в уникальное хеш-ведро, и никакие два значения не попадают в тот же ключ в хэше. Но идеальные хеш-функции встречаются редко, потому что мы обычно не знаем, насколько большой будет наш набор данных, прежде чем напишем хеш-функцию!
Суть в том, что мы должны понимать, как обрабатывать столкновения, потому что они почти наверняка произойдут. Это, вероятно, самая важная вещь, которую нужно понимать о хэш-функциях, потому что каждая из них должна учитывать коллизии.
Тактика разрешения столкновений
Существует несколько способов обработки коллизий в хэш-функции, и важно помнить, что ни один из них не обязательно является «правильной тактикой» для использования. Все зависит от вашего набора данных, размера вашей хеш-таблицы и от того, какие операции, как вы знаете, вы захотите выполнить с таблицей позже.
Давайте рассмотрим две наиболее распространенные тактики разрешения конфликтов, используемые в функциях хеширования.
Линейное зондирование
Один из способов обработки коллизий в хэш-функции - просто поиск следующего пустого хеш-ведра поблизости! Если это звучит просто ... ну, это потому, что это так! Не волнуйтесь, через минуту я немного усложню.
Идея здесь заключается в том, что если возникает коллизия и два элемента определены как находящиеся в одном месте в хеш-таблице, хеш-функция может просто перейти к следующему пустому ведру и добавить элемент там. Это своего рода перефразирование, и этот метод известен как линейное зондирование.
В линейном зондировании интересно то, что если следующее хеш-ведро также заполнено элементом, хеш-функция просто продолжит сканирование хеш-таблицы, пока не найдет пустое ведро, возвращаясь при необходимости.
Это означает, что если мы находимся в конце хеш-таблицы и ни одна корзина не пуста, функция просто возвращается к началу таблицы, эффективно исследуя таблицу, пока не найдет в наличии ведро для стихии!

Однако у линейного зондирования есть обратная сторона. (Я сказал, что собираюсь все усложнить, не так ли ?!). Проблема с этим конкретным методом заключается в том, что простой переход к следующему доступному хэш-сегменту и вставка элемента в «следующее свободное пространство» приводит к так называемой кластеризации.
Мы еще не говорили о том, что такое кластеризация, так что давайте сначала разберемся с этим!
Самый простой способ думать о кластеризации - это оценить, где находятся все данные в хеш-таблице.

Если все наши данные помещены в одну область хеш-таблицы, мы можем сказать, что наши данные сгруппированы в одной области или все сгруппированы вместе в одном месте.
С другой стороны, если наши данные распределены по таблице, по множеству различных хэш-сегментов и охватывают весь диапазон таблицы, мы можем сказать, что наша хеш-таблица хорошо разнесена.
Кластеризация - вредная вещь для хеш-таблиц. Фактически, если таблица сгруппирована, это означает, что она плохо спроектирована по определению. И обычно это признак того, что у нашей хеш-функции есть внутренняя проблема. Как правило, в хэш-функции есть две проблемы, которые приводят к кластеризации: либо наша хеш-функция не использует весь диапазон хеш-таблицы, либо она не распределяет данные равномерно по хэш-сегментам нашей хеш-таблицы. Обе эти две вещи приведут к кластеризации, и, как оказалось, использование линейного зондирования в качестве метода разрешения коллизий может иногда вызывать оба этих явления, что приводит к кластеризованной таблице.
Конечно, это опять же зависит от нашего набора данных. Если у нас есть много элементов, которые попадают в один хэш-бакет, и мы используем линейное зондирование для решения проблемы коллизии, все блоки вокруг того, который был заполнен с самого начала, начнут заполняться очень быстро. , и мы получим кластерную таблицу! Однако, если мы разработали хорошую функцию хеширования, а наша таблица достаточно велика, чтобы вместить наш набор данных, то линейное зондирование может стать отличным решением для обработки коллизий.
Цепочка
Вторая форма реализации разрешения коллизий в хэш-функции включает изменение структуры самой хеш-функции! Но не волнуйтесь - мы уже знакомы с тем, о чем собираемся поговорить, поэтому будем полностью профи.
Вместо того, чтобы иметь дело с недостатками линейного зондирования и решать проблему кластеризации, было бы здорово, если бы мы могли просто хранить несколько вещей в одной хэш-корзине. И это именно то, что мы можем сделать с помощью процесса цепочки!
Чтобы реализовать цепочку, хеш-таблица должна быть реструктурирована так, чтобы несколько элементов могли храниться под одним ключом. Надеюсь, у вас уже есть идея, что мы могли бы использовать здесь: удобный денди связанный список!
Вместо того, чтобы хранить один элемент в каждом хеш-ведре, мы можем связать несколько элементов вместе, чтобы каждый ключ таблицы имел указатель, который ссылается на связанный список.
Это упрощает добавление одного элемента - даже в случае столкновения (что больше не будет проблемой)! Нам просто нужно добавить его в начало связанного списка в соответствующем хеш-ведре.

Вы готовы к небольшому осложнению? Оказывается, у цепочки есть и обратная сторона. И вы, возможно, уже заметили это: поиск в связанном списке занимает много времени. Фактически, это занимает ровно столько же времени, сколько и элементов, или, другими словами, требуется O (n) времени.
Опять же, вопрос о том, является ли цепочка хорошим подходом к разрешению конфликтов, все сводится к нашей хэш-функции. Если наша хеш-функция принимает слова, но помещает все 50% слов в одно хеш-ведро, мы действительно не решили нашу проблему. , потому что теперь у нас есть длинный связанный список, который нам придется искать, и у нас больше нет времени на быстрый доступ к хешу!

Однако, если наша хеш-функция хорошо распределяет элементы по хеш-таблице, все будет в порядке. Фактически, если наша хеш-функция распределяет любые конфликты равномерно по хеш-таблице, это означает, что мы никогда не получим один длинный связанный список, который больше всего остального. Вместо этого мы должны иметь примерно одинаковый размер связанных списков в любом хеш-ведре, где есть коллизия.
Самое замечательное в этом то, что при хорошей хэш-функции цепочка по-прежнему в среднем дает время поиска O (1) или постоянное время поиска.
По сравнению с линейным зондированием цепочка - это совершенно другой подход со своими преимуществами и недостатками. Однако один факт остается верным для обоих этих двух подходов: если наша хеш-функция хороша, оба они могут быть мощными методами. Но если это не так, что ж, в обоих случаях нам придется иметь дело с какими-то последствиями.
У каждого инструмента есть свои плюсы и минусы, и это, безусловно, тот случай, когда речь идет о разрешении столкновений!
Вся сила в функции
Хорошая хеш-функция - это действительно то, что делает сильную реализацию хеш-таблицы. Мне нравится, как профессор Ананда Гунавардена объясняет это в своей вводной лекции о хешировании:
Как выбрать хорошую хеш-функцию? Как мы справляемся с столкновениями?
Проблема хранения и извлечения данных за время O (1) сводится к ответу на вышеперечисленные вопросы. Выбор «хорошей» хеш-функции - ключ к успешной реализации хеш-таблицы. Под «хорошей» мы подразумеваем то, что функция должна быть простой для вычисления и по возможности избегать коллизий. Если функцию трудно вычислить, мы теряем преимущество, полученное при поиске в O (1). Даже если мы выберем очень хорошую хеш-функцию, нам все равно придется иметь дело с «некоторыми» коллизиями.
Если мы сможем вспомнить эти два правила, о которых мы говорили ранее и которые профессор Гунаварден снова подчеркивает здесь, будет намного легче решить, является ли хеш-таблица правильным инструментом для работы.
Иногда при работе с отсортированными данными или фрагментами данных, которые необходимо получить сразу, хеш-таблицы могут быть плохим выбором. Однако с хорошей хэш-функцией они могут оказаться невероятно мощными. Как мы видели в нашем примере на прошлой неделе, хеш-таблицы в реальном мире встречаются повсюду.
И, как оказалось, они есть даже в вашем компьютере - сюрприз! Операционные системы Unix и Linux используют внутреннюю хеш-таблицу для хранения содержимого всех каталогов, на которые ссылается переменная среды PATH . Если вы когда-либо использовали версию команды rehash, то, что вы на самом деле делали, когда запускали эту команду, - это пересчет и перехеширование внутренней хеш-таблицы системы!
Многие языки программирования низкого уровня уже имеют готовые реализации хэш-таблиц, которые поставляются с языком. Java, например, имеет свой собственный класс HashTable, который используется Java-программистами для решения множества сложных проблем.
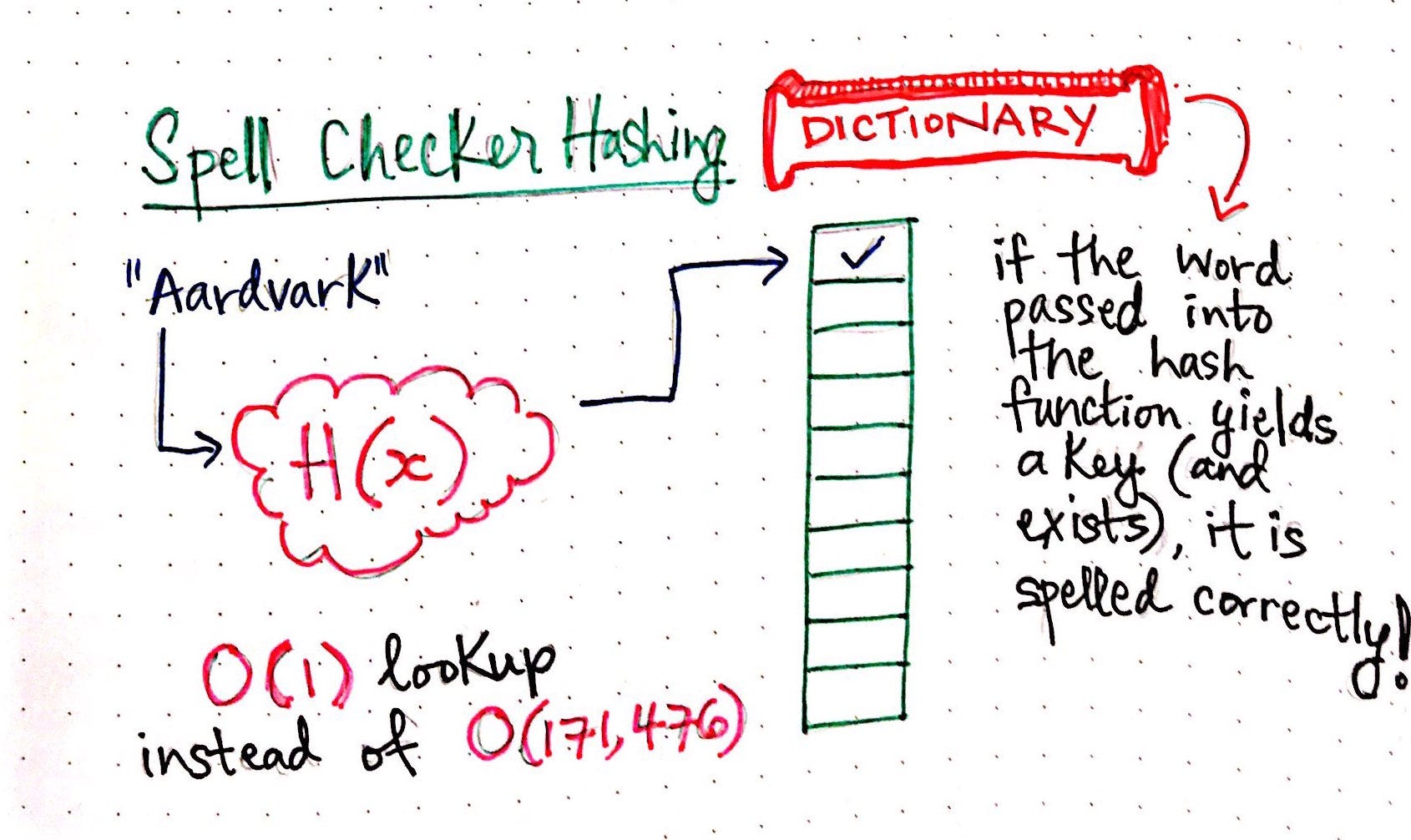
Мой любимый пример реализации структуры хеш-таблицы для решения задачи информатики - это проверка орфографии. Помните эти маленькие красные волнистые линии, которые раньше были так раздражающими (но полезными!) В MicrosoftWord? Мы могли бы легко реализовать это с помощью хеш-таблицы.
Во-первых, нам нужно передать все слова в словаре в хеш-функцию. После этого, когда кто-то заканчивает вводить слово, мы можем взять это слово и передать его нашей хэш-функции. Если функция вернула ключ хеш-сегмента, это означало бы, что слово существует в хеш-таблице, поэтому мы будем знать, что оно написано правильно. Если бы ключ не был возвращен, мы бы знали, что этого слова нет в словаре, либо оно не является словом, либо написано неправильно.
Но что лучше всего в этом? Проверка одного слова в словаре слов займет постоянное количество времени - независимо от того, насколько велик словарь! Ради интереса: Я посмотрел, сколько слов в Оксфордском словаре английского языка на данный момент: оказалось, что во втором издании 171 476 слов. Слава богу, за это O (1) время поиска!
Теперь, когда вы знаете все о хэш-таблицах и хороших хеш-функциях, вы полностью готовы к решению любых сложных хеш-задач, которые могут возникнуть перед вами. Удачного хеширования!
Ресурсы
Хеш-функции очень хорошо изучены, и вы можете углубиться в математику их работы. Если вы восхищены ими так же, как и я, то вам понравятся ресурсы, представленные ниже!
- Хеш-функция, Wolfram Mathworld
- Словари и хеш-таблицы, профессор Синиша Тодорович
- Хеш-таблицы линейного зондирования, факультет компьютерных наук, Университет РМИТ
- Решение проблем с помощью алгоритмов и структур данных: хеширование, Interactive Python
- Хеш-таблицы, профессора Роберт Седжвик и Кевин Уэйн
- Введение в хеширование, профессор Ананда Гунавардена