Одна из самых важных идей в вероятности и статистике - это концепция распределений. Прежде чем приступить к изучению каждого из известных дистрибутивов, давайте взглянем на основную терминологию.

Терминология:
1. Население и образец:
Проблема: предположим, что население Индии составляет почти 2 миллиарда, и я хочу найти средний рост. Физически и вычислительно сложно найти средний рост.
Решение: Итак, мы берем образец (random_sample) из генеральной совокупности. Как легко вычислить среднюю высоту случайной выборки.
Выборка - это подмножество генеральной совокупности. По мере увеличения размера выборки среднее значение нашей выборки становится равным среднему значению по генеральной совокупности.
2. Среднее: измеряет центральную тенденцию.

3.Разброс: в основном показывает, насколько обычно точки отклонялись от среднего значения.
4. Вариант: в основном он говорит: «Какое среднее значение квадрата расстояния каждой точки от среднего значения».

5.Стандартное отклонение: квадратный корень из дисперсии. В нем говорится: «Каково среднее отклонение баллов от среднего значения? ».

Если стандартное отклонение низкое, значит спред низкий.
Проблема со всеми этими тремя: «Один выброс или ошибка могут повредить все данные». Чтобы избежать проблемы с выбросами, мы предпочитаем медиану.
6.Средний: медиана - это среднее значение отсортированных данных, если общее количество точек было нечетным.
Выбросы не так сильно влияют на медианное значение, как среднее значение.
Если бы общее количество очков было четным,

7) Абсолютное отклонение среднего значения:
Он имеет то же понятие, что и стандартное отклонение. Он измеряет, насколько далеко мои точки от центральной тенденции, которая в данном случае является медианной.

Распределение Гаусса - N (μ, σ):
Также известно как нормальное распределение и зависит исключительно от двух параметров, а именно среднего (μ), стремящегося к нулю и стандартного отклонения (σ), стремящегося к единице.

В задачах и статистике большинство кривых имеют форму колокола. Эти колоколообразные кривые представляют собой функцию плотности вероятности (PDF) распределенной по Гауссу случайной величины.
Что означает функция плотности вероятности?
Он определяет вероятность того, что случайная величина попадает в определенный диапазон значений, а не принимает какое-либо отдельное значение.
Если 'X' является непрерывной случайной величиной и у нее есть PDF-файл, который выглядит как приведенная выше колоколообразная кривая, тогда мы можем сказать, что 'X' имеет распределение, то есть распределение Гаусса (X ~ N (0 , 1)).
Гауссова функция задается следующим образом:

Зачем изучать гауссово распределение?
Потому что он идеально подходит для любого природного явления, например
- Бросок кубика
-Бросать монету
- баллы IQ, результаты тестов, вес, рост, возраст
Вот почему это распределение больше всего нравится статистикам, инженерам по машинному обучению и глубокому обучению.
Кроме того, это легко пояснить, поскольку среднее значение, медиана и способ распределения равны.
Правило 68–95–99,7:

В статистике также называется эмпирическим правилом или правилом 3-σ, согласно которому 68,2% данных находятся в пределах 1-е стандартное отклонение (между μ-1σ и μ + 1σ), 95,4% данных находится в пределах 2 ое стандартное отклонение (между μ-2σ и μ + 2σ) и 99,7% данных находится в пределах 3-е стандартное отклонение (от μ-3σ до μ + 3σ). Редко значения наблюдений превышают стандартное отклонение 4,5.
Симметричное распределение:
Это распределение, в котором мы можем найти точку «x», такую, что с одной стороны у нас 50% точек, с другой стороны у нас есть оставшиеся 50% точек. Гауссово распределение является одним из таких распределений.

Несимметричное распределение:
i) Отрицательный перекос: слева у нас длинный хвост, а масса распределения сосредоточена вправо.

ii) Положительный перекос: справа у нас длинный хвост, а масса распределения сосредоточена слева.

Эксцесс:
Это говорит о пике кривой. Существует три типа эксцесса: мезокуртический (кривая со средним острием), лептокуртический (кривая с острым пиком) и платикуртический (кривая с плоским пиком).

Зачем узнавать о Куртоосисе?
Эксцесс - полезная мера того, есть ли проблема с выбросами в наборе данных. Больший эксцесс указывает на более серьезные проблемы с выбросами, поэтому исследователь должен выбрать альтернативные статистические методы.
Стандартное нормальное распределение:

Стандартизация - хороший метод, с помощью которого мы можем преобразовать переменную с любыми μ, σ2 в стандартную форму, которая имеет среднее значение (μ) = 0 и дисперсию (σ2) = 1.
Оценка плотности ядра:
Оценки плотности ядра тесно связаны с гистограммами. По гистограммам мы вычисляем функцию плотности вероятности путем сглаживания, и это сглаживание выполняется точно с использованием оценки плотности ядра.
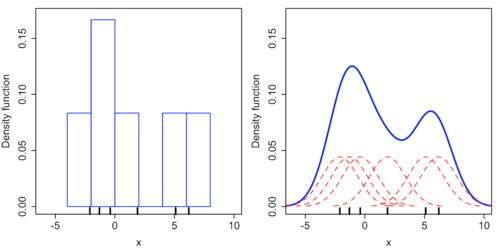
На гистограмме выше горизонтальная ось разделена на подинтервалы или интервалы шириной 2 (всего 6 интервалов).
Всякий раз, когда точка данных попадает в этот интервал, там помещается прямоугольник. Если в одну ячейку попадает более одной точки данных, ящики складываются друг на друга.
Для оценки плотности ядра нормальное ядро (красные пунктирные линии) со стандартным отклонением (σ) помещается в каждую точку данных. В каждой точке ядра суммируются, чтобы получить оценку плотности ядра (сплошная синяя кривая).
Чем полезны эти раздачи?
Вкратце, мы можем сказать, что все эти концепции, которые мы изучили, включая вероятность, полезны в исследовательском анализе данных (EDA). Речь идет об ответах на вопросы к нашим данным.
Рассмотрим реальный сценарий,

В институте под названием ABC обучается 10 тысяч студентов, и нам нужно заказывать футболки студентам на ежегодные празднования дня. Футболки бывают разных размеров: Medium, Large и XL. У нас есть следующие вопросы:
I. Сколько нужно рубашек XL?
Предположения:
- Получение измерений у 10 тыс. Студентов - дело затратное и трудоемкое. Итак, мы берем случайную выборку размером 500 из всей совокупности (10 тыс.). На основе этих 500 наблюдений мы пытаемся оценить выборочное среднее и стандартное отклонение выборки, приближенное к среднему значению и стандартному отклонению генеральной совокупности.
- Обычно люди ростом ≥ 1,8 метра носят рубашку размера XL, а люди ростом от 1,6 до 1,8 метра, как правило, носят футболку размера «L».

Как я упоминал ранее, высоты распределены нормально. Теперь мы уже вычислили среднее значение и стандартное отклонение. К тому моменту, когда мы узнали о распределении, среднем и стандартном отклонении, достаточно вычислить PDF и CDF (кумулятивная функция распределения). В CDF мы следим за ростом 1,8 метра, каков процент людей, рост которых превышает 1,8 метра. Предположим, что 1% людей ростом выше 1,8 метра, тогда мы можем сказать, что почти 100 человек (1% из 10 тысяч) нуждаются в рубашке XL.
Ссылки:
- Википедия
- Прикладной курс от Srikanth Verma and Khan Academy
- Машинное обучение Coursera, Эндрю Нг
Https://medium.com/analytics-vidhya/google-page-rank-and-markov-chains-d65717b98f9c