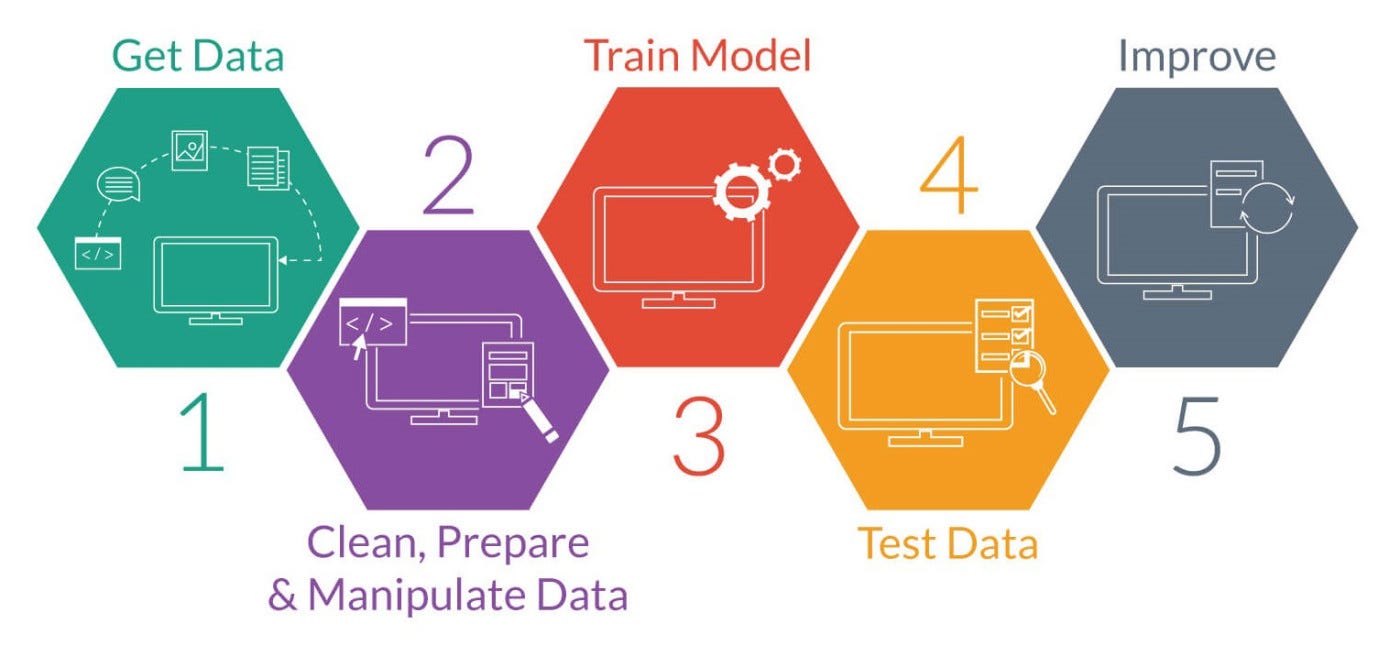
Прогнозирование финансовых показателей — одно из приложений машинного обучения. Следуя моей предыдущей статье об основах машинного обучения Введение в машинное обучение, в этой статье мы рассмотрим фрагмент кода, демонстрирующий процесс обучения модели для прогнозирования цен на кофе с использованием исторических данных. Данные взяты с Kaggle. Мы рассмотрим основные концепции кода, включая предварительную обработку данных, выбор модели, обучение и оценку.
1. Импорт библиотек и загрузка данных
Код начинается с импорта необходимых библиотек: «pandas» для манипулирования данными, «numpy» для числовых операций и различных модулей из библиотеки «sklearn» для задач машинного обучения. Исторические данные о ценах на кофе загружаются из файла CSV с помощью функции pd.read_csv().

2. Исследование и предварительная обработка данных
Набор данных отображается для понимания его структуры. Он состоит из двух столбцов: «дата» и «значение», где «дата» представляет дату точки данных, а «значение» представляет собой цену кофе. Однако в столбце «значение» отсутствуют значения (NaN).
Затем отсутствующие значения в столбце «значение» заменяются средним значением столбца с помощью функции «fillna()». Это гарантирует, что пропущенные значения будут заполнены разумной оценкой, которая не вносит смещения в набор данных.

3. Разделение данных
Набор данных разделен на функции (X) и целевые (Y) переменные. Столбец «дата» удаляется из функций, а столбец «значение» становится целевой переменной. Затем набор данных разделяется на наборы для обучения и тестирования с помощью функции «train_test_split()». Разделение выполняется с размером теста 20%, и для воспроизводимости устанавливается случайное начальное число (random_state).

4. Выбор модели и обучение
В качестве прогностической модели в этом примере выбрана модель линейной регрессии. Линейная регрессия — это простая и интерпретируемая модель, которая может отображать линейные отношения между функциями и целевой переменной. Класс «LinearRegression()» из «sklearn» создается как «модель» и обучается на обучающих данных с использованием метода «fit()».
Однако в данном наборе данных лучше подошла бы модель ARIMA, но для объяснения линейной регрессии она не используется.
5. Прогнозы
Используя обученную модель, делаются прогнозы на тестовом наборе данных с использованием метода predict(). Прогнозируемые значения хранятся в переменной «y_pred».
6. Визуализация и оценка
Затем в статье демонстрируются два типа визуализации для оценки производительности модели.
6.1 Линейный график фактических и прогнозируемых значений
Линейный график создается для визуализации фактических и прогнозируемых значений цен на кофе по индексам тестового набора. Фактические значения представлены сплошной линией, а прогнозируемые значения показаны пунктирной линией.


6.2 Точечная диаграмма для оценки
Диаграмма рассеивания создается для оценки корреляции между фактическими и прогнозируемыми значениями. Каждая точка на графике представляет точку данных из тестового набора. Прогнозируемые значения откладываются по оси x, а фактические значения откладываются по оси y. Хорошо работающая модель будет иметь точки, близко расположенные к диагональной линии, что указывает на высокую точность прогнозирования. В текущем сценарии очевидно, что модель переобучена.


7. Оценка модели — R-квадрат (R2)
Коэффициент детерминации (R-квадрат или R2) рассчитывается с использованием функции «r2_score()» из «sklearn.metrics». R2 измеряет долю дисперсии зависимой переменной (цели), которую можно предсказать на основе независимых переменных (признаков). Значение R2, равное 1,0, указывает на идеальное соответствие модели данным, подразумевая, что модель объясняет всю изменчивость целевой переменной.

8. Заключение
В этом фрагменте кода мы увидели, как выполнить базовый процесс обучения модели для прогнозирования цен на кофе с использованием исторических данных. Мы начали с загрузки и предварительной обработки данных, после чего последовало разделение данных, выбор модели (линейная регрессия), обучение, прогнозирование и оценка. Методы визуализации использовались, чтобы получить представление о производительности модели, а оценка R2 обеспечила количественную меру точности модели.
В приведенном выше примере видно, что модель переоснащается. Важно отметить, что этот пример демонстрирует простую модель линейной регрессии. В реальных сценариях могут потребоваться более сложные модели и дополнительные функции для получения точных прогнозов финансовых показателей. Тем не менее, этот код обеспечивает основу для понимания основных этапов обучения прогностической модели для финансовых данных.
Полный код доступен на GitHub.