
Эй, ребята, надеюсь, у вас все хорошо. Сегодня я расскажу вам историю. Моя личная история. Итак, если вы хотите стать специалистом по данным, мечтаете изо дня в день стать специалистом по данным, хотите работать над хорошими проектами, этот блог, мой друг, для вас.
Иногда жизнь учит тебя чему-то сотнями разных способов. Позвольте мне поделиться с вами своей частью обучения!!!
Итак, это были дни, когда я готовился к своей первой работе, я много программировал, много практиковался, потому что хотел получить роль Data Scientist, а будучи новичком, мне было трудно взломать роль Data Scientist. Я тратил 10 часов в день, чтобы понять тему, а затем кодировал ее с нуля.
Однажды я готовился к предстоящей поездке в университетский городок моего колледжа, и мой младший брат спросил меня: «Что такое наука о данных?»
Я сказал ему: «Наука о данных — это область, в которой компании и организации хотят понять закономерности в своих существующих данных и хотят получить значимую информацию из данных, чтобы они могли использовать эту информацию в своем бизнесе»
Он странно посмотрел на меня: «Это звучит так скучно», я думал заняться наукой о данных, потому что все об этом говорят, но это звучало слишком скучно для меня».
Я был буквально в шоке, потому что не мог найти ничего интересного, кроме науки о данных, тогда я спросил младшего брата: «Почему ты думаешь, что это скучно»?
Он ответил: «В нем так много сложных терминов, я не хочу это изучать».
Я сказал, что, если я скажу: «Всякий раз, когда вы берете такси, вы автоматически узнаете, сколько времени потребуется, чтобы добраться до места назначения, или когда вы заказываете еду, вы точно знаете, когда водитель приедет к вам домой, или автоматически в вашем gmail, Спам-почта попадает в папку со спамом, а обычная почта приходит в папку «Входящие». Все это Data Science».
Он ответил: «Ооо!!!!, это так круто, теперь это звучит интересно».
В тот день я понял одну простую вещь: ИНТЕРПРЕТИМОСТЬ, означающая, что не важно, что вы знаете, важно то, насколько легко это будет истолковано другим человеком.
"Наше восприятие меняется, если мы лучше интерпретируем вещи!!"
Я решил изучать вещи таким образом, что если мне нужно будет объяснить какую-то тему моему младшему брату, как я это сделаю? Поначалу было сложно, потому что мне нужно было разбить каждую тему на ее основы, но я продолжал учиться в том же духе…
ДЕНЬ ИНТЕРВЬЮ!!!
Итак, это был день, когда у меня появился шанс стать Data Scientist, я готовился к этому дню последние 2 месяца.
Первый раунд был простым раундом кодирования, где мне нужно было написать простые программы на Python, я с этим справлялся.
Второй раунд был техническим, технический менеджер представил себя и других товарищей по команде. Теперь поворот в игре заключался в том, что управляющий директор компании был школьным другом директора нашего колледжа. Так что он тоже приехал посетить кампус и встретил своего друга.
И он также хотел принять участие в раунде личного интервью. Он также сидел с техническим менеджером и другими интервьюерами.
Интервью должно было начаться, когда директор компании очень дружелюбно спросил меня: «Пожалуйста, объясните ответы так, как вы объяснили бы 10-летнему ребенку, я ничего не знаю о DataScience».
Слушая это, я знал это, это была моя игра!!!
Прежде чем это началось, я спросил, могу ли я использовать простой лист бумаги, чтобы объяснить темы, они согласились.
И тут началось интервью…
Вопрос-1-› Что такое контролируемое обучение и что такое неконтролируемое обучение?

Ответ-1 Допустим, я играю с маленьким ребенком 3 лет. Я взяла поднос и положила перед ним три фрукта. Первым фруктом были красные яблоки, Вторым фруктом были розовые вишни, Третьим фруктом были бананы.
Я предполагаю, что малыш никогда не видел этих фруктов, никогда их не ел, он ничего не знал об этих плодах.
Затем я сказал ему 100 раз, что этот красный фрукт называется «яблоки», этот розовый фрукт называется «вишня», этот желтый фрукт называется «банан». Я повторяю и повторяю.
Здесь я предоставляю своему ребенку вход, который является фруктом, и выход, который называется «Яблоко». Ребенок может узнать, что этот красный фрукт круглой формы называется «Яблоко».
Это то, что мы назвали контролируемым обучением, когда вы одновременно вводите и выдаете данные, а машина должна изучить, как конкретный ввод сопоставляется с конкретным выходом.
Например, Gmail Spam/NotSpam Classifier.
Тогда что такое неконтролируемое обучение?
Допустим, у меня появился еще один ребенок, я просто показал ему 3 фрукта, но не сказал, какой фрукт как называется. Я уверен, что, посмотрев на поднос несколько раз, ребенок сможет отличить, что все красные фрукты выглядят одинаково, все желтые фрукты выглядят одинаково и так далее. Он не сможет назвать имя, но сможет распределить их по разным категориям в зависимости от цвета.
Это неконтролируемое обучение, когда мы даем машине только входные данные, из которых она должна понять, к какой группе или кластеру принадлежит конкретный ввод.
Например, обнаружение мошенничества с кредитными картами.
Вопрос-2- › Можете ли вы сказать мне разницу между аналитиком данных и специалистом по данным?
Ans2- Допустим, я сотрудник Swiggy, и мой менеджер попросил меня
«указать 5 лучших городов, из которых мы получаем наименьшее количество заказов за последние 6 месяцев». Теперь предположим, что за последние 6 месяцев swiggy получил 10 000 000 000 000 000 000 000 000 000 000 заказов. Ответ на этот вопрос уже есть в моих данных, но вручную его очень сложно найти, поэтому здесь появляется роль аналитика данных, который использует такие библиотеки, как Numpy, Pandas, Matplotlib, и даже такие инструменты, как Power Bi, чтобы найти ответ.
Но допустим, мой менеджер сказал мне: «Укажите ориентировочную стоимость продажи нашей компании к концу этого года». Теперь моя работа состоит в том, чтобы спрогнозировать стоимость продажи. Это наука о данных или машинное обучение.
Вы отправляетесь в прошлое в данные, их анализ данных.
Вы идете в будущее, его науку о данных.
Вопрос-3-> Тогда знаете ли вы, кто такой инженер данных?
Ответ-3 Допустим, я использую OLA и заказал такси, такси подъехало к моей двери, и я завершил свою поездку. Теперь, через 10 дней, если я хочу получить какую-либо информацию о поездке, которую я совершил, я могу просто пойти и проверить наше приложение OLA.
Теперь, как каждый мой щелчок сохраняется в виде данных: во сколько я взял такси, продолжительность поездки, цена и многое другое. Одной из задач Data Engineer является создание конвейеров данных и получение данных, хранящихся в облачной базе данных, такой как Mongodb.
Вопрос-4- › Дайте определение p-значению и скажите, почему оно важно?
Ответ-4 - Когда ученые проводят эксперименты, они хотят знать, действительно ли их результаты имеют значение или это просто совпадение. Значение p помогает им сделать это определение.
Р-значение — это число, которое говорит нам о вероятности того, что результаты, которые мы видим в эксперименте, обусловлены случайностью. Чем ниже p-значение, тем меньше вероятность того, что результаты являются простым совпадением.
Например, допустим, группа ученых тестирует новое лекарство. Они дают лекарство одной группе людей и плацебо (поддельное лекарство) другой группе. Затем они измеряют, сколько людей в каждой группе выздоравливают. Если группа, получившая лекарство, имеет гораздо более высокий процент людей, которым стало лучше, ученые могут рассчитать p-значение, чтобы увидеть, является ли это различие случайным или статистически значимым.
В целом ученые считают значение р 0,05 или ниже статистически значимым. Это означает, что вероятность того, что результаты случайны и, вероятно, имеют смысл, составляет менее 5 %.
Вопрос-5- › Что такое PDF и CDF и почему вы считаете, что это важно в машинном обучении?

Ans-5 PDF означает функцию плотности вероятности. В теории вероятностей PDF — это функция, описывающая относительную вероятность того, что случайная величина примет определенное значение или набор значений.
CDF означает кумулятивную функцию распределения. Это функция, которая дает вероятность того, что случайная величина меньше или равна определенному значению.
PDF и CDF важны, потому что они позволяют нам моделировать распределение данных. Понимая распределение данных, мы можем принимать более обоснованные решения о том, как их обрабатывать и анализировать. Например, если у нас есть набор данных изображений, мы можем захотеть узнать, как выглядит распределение значений пикселей. Эта информация может помочь нам выбрать подходящие методы или модели предварительной обработки, учитывающие структуру данных.
Вопрос-6- › Можете ли вы объяснить Центральную предельную теорему?

Центральная предельная теорема — это статистическая концепция, которая помогает нам понять, как распределяются средние значения случайных величин. В нем говорится, что если мы возьмем большое количество случайных выборок из совокупности и вычислим среднее значение каждой выборки, распределение этих средних значений будет приблизительно нормальным, независимо от формы исходной совокупности.
Например, представьте, что мы хотим узнать средний рост всех учеников в школе. Мы могли бы измерить рост каждого ученика, но это заняло бы очень много времени. Вместо этого мы могли бы взять случайную выборку студентов и измерить их рост. Затем мы могли бы взять средний рост этой выборки и повторить процесс много раз, каждый раз беря другую случайную выборку студентов. Согласно центральной предельной теореме, распределение этих средних было бы приблизительно нормальным, даже если бы распределение роста в исходной популяции не было нормальным.
Вопрос-7- › Что такое структуры данных и какие структуры данных у нас есть в python?
Структуры данных Ans-7 означают, как я могу хранить свои данные, но вопрос в том, почему мне нужны разные способы хранения данных.
Недостаточно ли хранить данные в одной структуре?
Так что да, мы не можем хранить данные только в одной структуре данных, потому что каждая структура данных имеет свои преимущества и недостатки.
Например, Python имеет 4 структуры данных.
- Список. Теперь список является изменяемой структурой данных, но имеет временную сложность o(n), что не очень хорошо, но имеет пространственно-временную сложность o(1).
- Кортеж. Кортеж неизменяем и имеет ту же сложность времени поиска, что и список.
- Словарь. Словарь является изменяемым, а также имеет o(1) временную сложность поиска, но o(n) пространственно-временную сложность.
- Set. Набор можно изменять, потому что мы можем вставлять новые элементы в список, набор также не допускает дублирования.
Вопрос-8- › Что такое CNN. Можете ли вы объяснить какие-либо известные архитектуры CNN?

Ans-8 CNN расшифровывается как Convolution Neural Network, где свертка означает поэлементное умножение и сложение. CNN обычно используются в задачах компьютерного зрения, где основная проблема заключается в создании векторов из изображений.
Как бы мы собирали информацию из изображения в математический вектор, чтобы мы могли использовать эту информацию для таких задач, как обнаружение объектов, распознавание лиц и т. д.
Вот некоторые известные архитектуры CNN:
- LeNET-LeNet (сокращение от LeNet-5) — это архитектура сверточной нейронной сети, разработанная Яном Лекуном, Леоном Ботту, Йошуа Бенжио и Патриком Хаффнером в 1998 году. нейронные сети для задач распознавания и классификации изображений.
- AlexNet. AlexNet — это архитектура сверточной нейронной сети, разработанная Алексом Крижевским, Ильей Суцкевером и Джеффри Хинтоном. В 2012 году он выиграл конкурс ImageNet Large Scale Visual Recognition Challenge и широко считается одним из прорывов, которые вызвали революцию в области глубокого обучения.
- VGG16-VGG16 — это архитектура сверточной нейронной сети, состоящая из 16 слоев, включая 13 сверточных слоев и 3 полносвязных слоя. Он был разработан группой Visual Geometry в Оксфордском университете и в 2014 году достиг самых современных результатов в наборе данных ImageNet.
Вопрос-9-› Что такое Max Pooling и зачем нам нужен Max Pooling?
Ans-9 Max Pooling включает в себя разделение входного изображения на набор непересекающихся прямоугольных областей, а затем получение максимального значения каждой области. В результате получается уменьшенная версия входного изображения с уменьшенными пространственными размерами.
Основная причина использования Max Pooling заключается в уменьшении размера карт объектов, созданных сверточными слоями в CNN, при сохранении наиболее важных функций. Это помогает снизить вычислительную сложность сети, упрощая обучение и ускоряя обработку новых входных изображений.
Вопрос-10-› Что такое НЛП?
НЛП расшифровывается как обработка естественного языка, это ветвь искусственного интеллекта, которая фокусируется на обучении машин тому, как понимать, интерпретировать и генерировать человеческий язык. Он включает в себя разработку алгоритмов и моделей, которые могут анализировать и обрабатывать текст, речь и другие формы данных естественного языка.
Он позволяет машинам выполнять такие задачи, как анализ настроений, языковой перевод, обобщение текста, общение с чат-ботами и многое другое. NLP используется в самых разных приложениях, от виртуальных помощников, таких как Siri и Alexa, до спам-фильтров в электронной почте и даже в здравоохранении для медицинской диагностики и планирования лечения.
Вопрос-11- › Какие существуют алгоритмы для встраивания предложения в вектор?
Ответ-11 Некоторые из алгоритмов, которые используются для встраивания предложения в вектор:
- Мешок слов
- TF-IDF
- Word2Вектор
- БЕРТ(Трансфер)
- Модели GPT
Вопрос-12- › Какой ваш любимый алгоритм?
Ans-12 Мой любимый алгоритм — Random Forest.
Random Forest — это популярный алгоритм машинного обучения, который использует концепцию ансамблевого обучения для построения надежной и точной модели.
Ансамблевое обучение включает в себя объединение нескольких моделей для получения прогноза. В случае случайного леса несколько деревьев решений строятся с использованием случайно выбранных подмножеств обучающих данных и признаков. Каждое дерево решений обучается независимо, и окончательный прогноз делается путем получения среднего или большинства голосов прогнозов из всех деревьев решений.
Случайный выбор подмножеств данных и функций помогает уменьшить влияние отдельных зашумленных точек данных или функций на прогнозы модели, а комбинация нескольких деревьев решений помогает повысить точность модели и уменьшить переоснащение.
Вопрос-13- › Что такое гиперпараметр?
В машинном обучении гиперпараметр — это параметр, который задается до начала процесса обучения и определяет общее поведение и производительность алгоритма машинного обучения.
Гиперпараметры используются для управления процессом обучения и влияют на то, как обучается модель, например скорость обучения, параметр регуляризации, количество скрытых слоев, количество нейронов на слой и т. д.
Процесс выбора наилучших гиперпараметров для данной проблемы известен как настройка гиперпараметров.
Вопрос-14-› Что такое недообгон
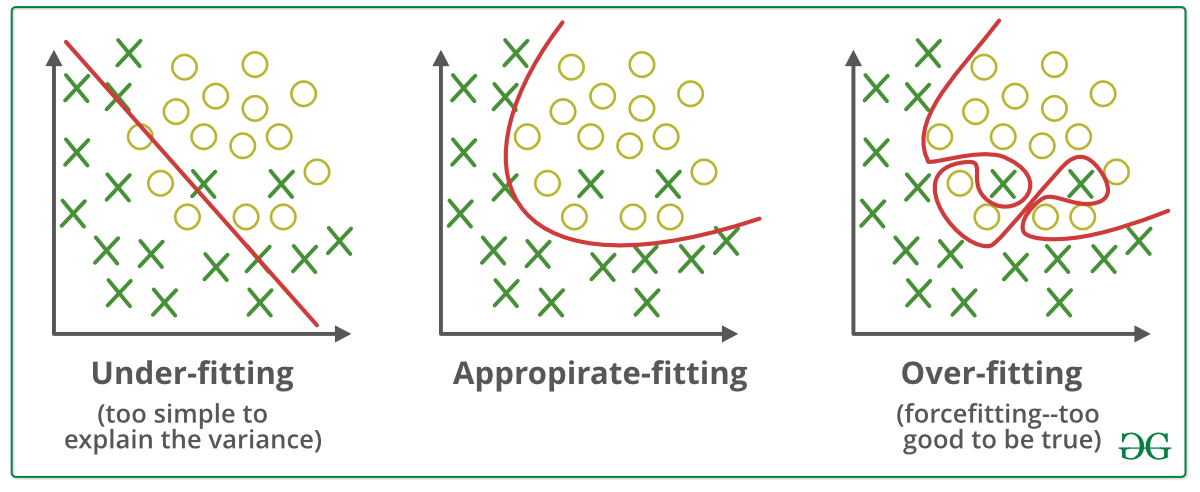
Ans-14 Недообучение — это распространенная проблема в машинном обучении, когда модель не может зафиксировать основные шаблоны и отношения в обучающих данных, что приводит к низкой производительности как на обучающих, так и на тестовых данных.
Проще говоря, недообучение происходит, когда модель слишком проста или недостаточно сложна для представления данных. Это означает, что модель не может изучить соответствующие функции и отношения между входными переменными и целевой переменной. В результате модель дает большое смещение и низкую дисперсию и плохо работает как с обучающими данными, так и с новыми невидимыми данными.
Вопрос-15-›Что такое переобучение?
Ответ-15. Переобучение — распространенная проблема в машинном обучении, когда модель слишком сложна и слишком точно соответствует обучающим данным, что приводит к плохой производительности обобщения новых невидимых данных.
Проще говоря, переобучение происходит, когда модель слишком сложна и изучает шум в обучающих данных вместе с основными шаблонами и отношениями между входными переменными и целевой переменной. Это означает, что модель не может хорошо обобщать новые данные и дает высокую дисперсию и низкое смещение, что приводит к плохой работе с новыми данными.
Вопрос-16-› Что такое ошибка модели?
Ответ-16 Ошибка модели определяется как:
Ошибка модели = смещение + (дисперсия)²
Вопрос-17- › Что такое One-Hot-Encoding?
Ans-17 Одно горячее кодирование — это метод, используемый в машинном обучении для представления категориальных данных в виде числовых данных. Он включает в себя создание бинарного вектора для каждой категории в категориальной переменной, где каждый вектор имеет длину, равную количеству уникальных категорий в переменной.
Проще говоря, одно горячее кодирование заменяет каждую категорию в категориальной переменной двоичным вектором, который имеет значение 1 в соответствующем индексе и значение 0 во всех остальных индексах.
Например, предположим, что у нас есть категориальная переменная «Цвет» с тремя уникальными категориями: красный, зеленый и синий. Одно горячее кодирование создаст двоичный вектор длины три для каждого цвета: [1, 0, 0] для красного, [0, 1, 0] для зеленого и [0, 0, 1] для синего.
Вопрос-18- › Что такое многоклассовая классификация?

Ans-18 Мультиклассовая классификация — это задача прогнозирования целевой переменной, которая имеет более двух возможных результатов или классов. Например, предсказание типа фрукта на изображении, будь то яблоко, банан или апельсин, будет проблемой классификации нескольких классов.
Основное различие между бинарной классификацией и мультиклассовой классификацией заключается в количестве классов или категорий в целевой переменной. В бинарной классификации целевая переменная имеет только два класса, тогда как в многоклассовой классификации целевая переменная имеет более двух классов.
Вопрос-19- › Можем ли мы использовать весь алгоритм, если у нас есть проблема классификации нескольких классов?
Ответ-19 Нет, мы не можем использовать весь алгоритм напрямую для использования многоклассовой классификации. Мы используем такие методы, как One Vs ALL, чтобы заставить его работать.
Например, логистическая регрессия определена для бинарного класса, но мы можем использовать One Vs All, чтобы использовать ее для многоклассовой классификации.
Вопрос-20-› Какой показатель производительности вы будете использовать, если у вас есть проблема, связанная со здоровьем, такая как «Прогнозирование рака»?
Ans-20 Одним из часто используемых показателей производительности в медицинских приложениях является чувствительность, также известная как доля истинных положительных результатов. Чувствительность измеряет долю фактических положительных случаев, которые модель правильно идентифицирует как положительные. В прогнозировании рака важна чувствительность, поскольку она отражает способность модели правильно идентифицировать людей, у которых есть рак и которым может потребоваться дальнейшее медицинское обследование.
Еще одним важным показателем эффективности для прогнозирования рака является специфичность, также известная как истинный отрицательный показатель. Специфичность измеряет долю фактических отрицательных случаев, которые модель правильно идентифицирует как отрицательные. В прогнозировании рака важна специфичность, поскольку она отражает способность модели правильно идентифицировать людей, у которых нет рака и которым может не потребоваться дальнейшее медицинское обследование.
Вопрос-21- › Что такое F1 Score?
Оценка Ans-21 F1 представляет собой среднее гармоническое от Precision and Recall.
F1=2PR/P+R
Вопрос-22-› Почему вы думаете, что за наукой о данных будущее?
Ans-22 Наука о данных становится все более и более важной, потому что каждый день создается и хранится много информации из-за роста Интернета и технологий. Наука о данных помогает нам осмыслить всю эту информацию и найти полезные закономерности и идеи, которые могут помочь отдельным лицам и компаниям принимать более обоснованные решения. В результате растет спрос на специалистов по данным, которые могут анализировать и интерпретировать данные для решения реальных проблем.
По мере того, как все больше и больше людей будут понимать, как наука о данных может на самом деле принести больше бизнеса их компании, будет происходить больше наймов.
Вопрос-23-› Что такое NLTK?
Ans 23-NLTK — это программная библиотека с открытым исходным кодом, написанная на Python, которая предоставляет инструменты и ресурсы для задач обработки естественного языка (NLP), таких как токенизация, выделение корней, тегирование, синтаксический анализ и семантическое рассуждение. Он также предлагает доступ к обширной коллекции языковых корпусов и лексических ресурсов. NLTK широко используется в научных кругах и промышленности для исследований, разработок и обучения НЛП.
Вопрос-24-› Что такое Dropouts?
Ans 24-Dropout — это метод регуляризации, используемый в нейронных сетях глубокого обучения для предотвращения переобучения. Переобучение происходит, когда модель становится слишком сложной и обучена слишком близко подходить к обучающим данным, что может привести к плохой работе с новыми, невидимыми данными.
Dropout работает путем случайного исключения (т. е. обнуления) некоторых нейронов в нейронной сети во время обучения. Это вынуждает сеть изучать более надежные функции и не позволяет любому отдельному нейрону стать слишком важным для прогнозов.
В процессе обучения каждый нейрон в сети либо выбывает с заданной вероятностью, либо сохраняется с вероятностью (1 — частота выпадения). Частота отсева обычно устанавливается между 0,1 и 0,5, а оптимальное значение может зависеть от конкретной проблемы и архитектуры нейронной сети.
Вопрос-25- › Что такое нормализация партии?
Ответ 25. Пакетная нормализация работает путем нормализации выходных данных каждого слоя перед применением функции активации. Во время обучения среднее значение и стандартное отклонение выходных данных каждого слоя вычисляются для каждой мини-партии, и эта статистика используется для нормализации выходных данных. В частности, выходные данные нормализуются путем вычитания среднего значения и деления на стандартное отклонение, которое затем масштабируется и сдвигается на обучаемые параметры, называемые гаммой и бета.
Пакетная нормализация имеет несколько преимуществ, в том числе:
- Это снижает зависимость модели от инициализации весов, упрощая обучение глубоких сетей.
- Это может улучшить производительность обобщения модели за счет уменьшения переобучения.
- Это делает процесс оптимизации более стабильным, позволяя использовать более высокие скорости обучения.
Вопрос-26- › Что такое персептрон?

Ответ 26. Персептрон — это тип искусственной нейронной сети, который обычно используется в машинном обучении для задач бинарной классификации. Это простая модель, которая принимает вектор входных данных, применяет к входным данным линейную функцию и выдает двоичный вывод на основе порогового значения.
Наиболее часто используемой функцией активации в персептронах является ступенчатая функция, которая дает на выходе 1, если взвешенная сумма входных данных больше или равна пороговому значению, и 0 в противном случае. Другие функции активации, такие как сигмовидная функция или функция ReLU, также могут использоваться в более сложных моделях.
Вопрос-27- › Как логистическая регрессия является моделью одного нейрона?

Ответ-27. Это модель с одним нейроном в том смысле, что она основана на одном выходном нейроне, который применяет логистическую функцию (также известную как сигмовидная функция) к линейной комбинации входных данных.
В логистической регрессии входные признаки x1, x2, …, xn линейно комбинируются с использованием весов w1, w2, …, wn и точки пересечения b для получения одного результата z = w1x1 + w2x2. + … + wn*xn + b. Затем этот вывод передается через логистическую функцию для получения прогнозируемой вероятности y_hat положительного класса:
y_hat = 1 / (1 + exp(-z))
Только один нейрон дает выход, это мы назвали моделью одного нейрона.
Вопрос-28- › Почему название логистической регрессии имеет регрессию, когда это метод классификации.
Ответ 28. Результат логистической регрессии:
y_hat = 1 / (1 + exp(-z))
y_hat всегда будет находиться в диапазоне от 0 до 1, так что это будет любое значение от 0 до 1, что напоминает регрессию. Классификация означает 0 или 1, регрессия означает любое значение от 0 до 1. Таким образом, характер вывода - регрессия, но затем мы берем пороговое значение, чтобы решить, принадлежит ли оно классу 0 или классу 1.
Например, если выход равен 0,8, а порог равен 0,5, то мы скажем, поскольку значение выхода> 0,5, он принадлежит к классу 0.
Вопрос-29- › Что такое сигмовидная функция? Почему он используется в логистической регрессии?
Ans-29 Сигмовидная функция
Сигмоид(x)=1 / (1 + exp(-x))
Сигмовидная функция является дифференцируемой функцией и имеет вероятностный характер.
Он используется в логистической регрессии, поскольку сужает выбросы в данных. Мы используем сигмовидную функцию, чтобы исключить выбросы из данных.
Вопрос-30- › Что вы подразумеваете под гиперплоскостью и насколько гиперплоскость важна для машинного обучения?

Ans30- Допустим, у меня есть задача классификации, и я хочу классифицировать два класса, спам и не спам, и у меня есть только 2 функции.
Две функции означают, что геометрия задачи находится в 2D, ось x — это функция 1, а ось y — функция 2.
Теперь, если вы видите на диаграмме, если я хочу классифицировать 2 класса, мне понадобится линия.
Если у меня есть три функции, чтобы разделить эти два класса, нам нужна плоскость.
Если бы у меня было больше трех функций, мне понадобилась бы гиперплоскость.
В большинстве проблем машинного обучения у нас есть более 3 функций, и для их решения мне понадобится гиперплоскость. Я бы знал уравнение гиперплоскости, потому что гиперплоскость на самом деле является границей решения.
Вопрос-31- › Что такое обратное распространение?

Ans31 Обратное распространение — это способ, в котором мы используем цепное правило дифференцирования и концепцию мемоизации, чтобы найти производную функции потерь по весам, чтобы мы могли обновить наши веса в обновленном уравнении градиентного спуска.
Обратное распространение — это обратная сторона глубокого обучения, потому что в конце нам нужно найти веса, чтобы завершить процесс обучения.
Вопрос-32- › Что такое градиентный спуск?
Ans32-Градиентный спуск — это алгоритм оптимизации, используемый для минимизации функции стоимости модели машинного обучения. Функция стоимости — это мера разницы между прогнозируемым выходом модели и фактическим выходом.
Алгоритм работает, начиная со случайной точки в пространстве параметров модели и итеративно корректируя параметры в направлении наискорейшего спуска функции стоимости, которая определяется градиентом функции стоимости. Градиент — это вектор, который указывает в направлении наибольшей скорости увеличения функции стоимости, и алгоритм обновляет параметры в направлении, противоположном градиенту, чтобы двигаться к минимуму функции стоимости.
Вопрос-33-› В чем проблема с градиентным спуском?
Ans33- Хотя градиентный спуск является широко используемым и эффективным алгоритмом оптимизации для многих моделей машинного обучения, с ним связаны некоторые потенциальные проблемы:
- Локальные минимумы: градиентный спуск может сходиться к локальному минимуму функции стоимости, который может не быть глобальным минимумом. Это может привести к неоптимальным решениям, которые не работают так хорошо, как могли бы.
- Скорость обучения: скорость обучения определяет размер шага, предпринимаемого алгоритмом в направлении градиента. Если скорость обучения слишком мала, алгоритм может сходиться слишком медленно, а если скорость обучения слишком велика, алгоритм может выйти за пределы минимума и не сойтись.
Вопрос-34-› Что такое SGD (стохастический градиентный спуск)?
Ответ34-
- SGD — это вариант градиентного спуска, используемый для обучения моделей машинного обучения.
- Он обновляет параметры модели после каждого отдельного обучающего примера или небольшой партии примеров.
- Это делает алгоритм более эффективным в вычислительном отношении и может привести к более быстрой сходимости.
- SGD обычно используется для больших наборов данных и моделей глубокого обучения.
Вопрос-35- › Объясните проблему исчезающего градиента?
Ans35- Проблема исчезающих градиентов относится к ситуации, когда градиенты функции стоимости по отношению к параметрам модели становятся очень малыми, особенно в глубоких нейронных сетях, что затрудняет эффективное обучение сети.
Когда градиенты малы, обновления параметров модели во время обучения становятся очень маленькими, и сеть может сходиться к неоптимальному решению или вообще не сходиться. Проблема особенно остро стоит в глубоких нейронных сетях со многими слоями, где градиенты могут становиться экспоненциально малыми по мере распространения по слоям.
Вопрос-36- › Какие различные функции активации мы использовали в глубоком обучении?

Ответ36-
- Сигмоид: функция сигмоида сопоставляет любое входное значение со значением от 0 до 1. Она часто используется в выходном слое моделей бинарной классификации.
- Гиперболический тангенс (tanh): функция tanh сопоставляет любое входное значение со значением от -1 до 1. Она обычно используется в качестве функции активации в скрытых слоях.
- Выпрямленная линейная единица (ReLU). Функция ReLU выводит входное значение, если оно положительное, и 0 в противном случае. Он широко используется в глубоких нейронных сетях благодаря своей простоте и эффективности.
- Leaky ReLU. Функция Leaky ReLU — это вариант функции ReLU, который допускает небольшой положительный градиент при отрицательном входном сигнале. Это может помочь решить проблему «умирающего ReLU», когда градиенты становятся нулевыми для отрицательных входных данных.
Вопрос-37- › Как бороться с выбросами в машинном обучении?
Ответ -37- Вот несколько методов, которые можно использовать для борьбы с выбросами в машинном обучении:
- Обнаружение. Прежде чем работать с выбросами, важно сначала их обнаружить. Это можно сделать с помощью различных статистических методов, таких как Z-оценка, межквартильный диапазон (IQR) и ящичковые диаграммы.
- Удаление. Один из подходов к работе с выбросами — просто удалить их из набора данных. Однако этот подход следует использовать с осторожностью, поскольку удаление слишком большого количества точек данных может привести к потере информации и необъективным результатам.
Вопрос-38-› Что вы будете делать, если ваша модель переобучен?
Ответ 38. Увеличьте размер набора данных. Один из способов уменьшить переоснащение — увеличить размер набора обучающих данных. Это может помочь модели лучше обобщать невидимые данные.
- Выбор функций. Другой подход заключается в тщательном выборе наиболее релевантных функций, которые могут оказать сильное влияние на прогнозы модели. Это может помочь уменьшить шум в данных и улучшить производительность модели.
- Регуляризация. Регуляризация — это метод, который добавляет штрафной член к функции стоимости во время обучения, что помогает предотвратить переоснащение модели обучающими данными. Популярные методы регуляризации включают регуляризацию L1 и L2, отсев и раннюю остановку.
Вопрос-39- › Что такое RFR (рандомизация для регуляризации)?
Ans39- Рандомизированная регуляризация — это метод, который сочетает в себе концепции регуляризации и рандомизации для повышения производительности моделей машинного обучения. Он включает в себя добавление случайного компонента в процесс регуляризации, что помогает предотвратить переоснащение модели обучающими данными.
Вопрос-40- › Можете ли вы объяснить разницу между выпуклой и невыпуклой функциями?
Ответ 40. Проще говоря, выпуклая функция — это функция, имеющая чашеобразную форму, где любой отрезок, соединяющий две точки функции, лежит над функцией или над ней.
С другой стороны, невыпуклая функция — это функция, имеющая более сложную форму, где может быть несколько локальных минимумов и максимумов.
В задачах оптимизации выпуклые функции оптимизировать легче, потому что они имеют единственный глобальный минимум, который можно найти эффективно. С другой стороны, невыпуклые функции сложнее оптимизировать, поскольку они могут иметь несколько локальных минимумов, а поиск глобального минимума требует исследования большего пространства поиска.
КОДИРОВАНИЕ РАУНДА
Вопрос-41- › Найдите в списке элемент с наибольшим числом.

Вопрос-42- › Повернуть массив на d элементов.

Вопрос-43-›По заданной строке измените порядок строк в каждом слове в предложении, сохранив при этом пробелы и первоначальный порядок слов.

Вопрос-44-› Имея 2 строки, вам нужно найти общие элементы в обеих строках.

Вопрос-45- › Напишите код на питоне для печати шаблона.

Вопрос-46- › Какова временная сложность поиска списка и словаря?
Ответ 46. Сложность времени поиска составляет O (n), что не очень хорошо по сравнению со словарями, которые составляют O (1).
Вопрос-47- › Напишите программу на Python для определения функции мощности с нуля?

Вопрос-48- › Напишите функцию Python, чтобы найти кубическую сумму только рекурсией?

Вопрос-49- › Написать программу для поиска скалярного произведения в питоне с нуля?

Вопрос-50- › Напишите программу на Python, которая дает нам евклидово расстояние с нуля?

Это было длинное длинное интервью, я был очень счастлив и удовлетворен ответами.
Команда выглядела счастливой, директор улыбнулся мне, но ничего не сказал.
Через 1 час я узнал, что «меня выбрали».
Поэтому, если вы спросите меня, что у меня получилось, я отвечу: «Моя способность разбивать сложные определения на простые слова имела решающее значение».
Работа Data Analyst / Data Scientist заключается не только в том, чтобы анализировать данные или строить модель, но и в том, чтобы фактически сообщать результаты людям, которые принимают решения в компании, и они могут не знать ни слова о науке о данных, но они знают бизнес. Как только вы поймете, как использовать свои технические навыки для решения бизнес-задач простыми словами, вы готовы к работе.
Так что да, интерпретируемость модели машинного обучения и интерпретируемость ваших слов очень важны в любом интервью.
На сегодня все, спасибо за прочтение…