
Категориальная переменная — это распространенный тип данных, который можно найти во многих наборах данных машинного обучения. Эффективная обработка категориальных переменных может иметь решающее значение для построения успешных моделей, поскольку она содержит обширную информацию, которую можно использовать для прогнозирования результатов в машинном обучении.
Однако работа с категориальными переменными может быть сложной задачей, поскольку многие модели предназначены для обработки числовых данных. В результате некоторым людям может потребоваться разъяснение правильной обработки категорийных данных, что может привести к путанице и потенциально неоптимальной производительности модели.
Цель этой статьи — предоставить четкий и всесторонний обзор наиболее популярных подходов к обработке категориальных данных в машинном обучении. Понимая различные доступные варианты и их последствия, я надеюсь предоставить читателям знания и инструменты, необходимые им для обработки категориальных данных в их проектах машинного обучения.
Категориальные данные в машинном обучении
Категориальные данные состоят из данных, которые можно классифицировать по категориям. В машинном обучении часто встречаются категориальные данные из таких переменных, как пол, раса, национальность, жанр. или род занятий. Категориальные данные часто присутствуют в реальных наборах данных, и очень важно правильно с ними обращаться.
Одна из основных проблем работы с категориальными данными заключается в том, что большинство алгоритмов машинного обучения предназначены для работы с числовыми данными. Это означает, что категориальные данные должны быть преобразованы в числовой формат для использования в качестве входных данных для модели.
Работа с категориальными данными
В этом разделе будут рассмотрены некоторые популярные методы работы с категориальными данными в машинном обучении.
Что такое «Замена цифр»?
Замена на числа относится к процессу замены категориальной переменной числовым значением.
Например, продолжая пример выше, если мы заменим категориальную переменную числовыми значениями, мы получим следующее:

Вот код Python, использующий replace во фрейме данных Pandas в качестве ссылки:
df.replace({'rock': 0, 'jazz': 1, 'blues': 2})
Что такое «кодировщик меток»?
Label Encoder — это еще один метод кодирования категориальных переменных. Он присваивает уникальное числовое значение каждой категории в категориальной переменной.
Использование Label Encoder в предыдущем примере приведет к тем же значениям, что и замена. Хотя заменить может быть подходящим подходом для небольшого числа категорий, он может стать непрактичным при работе со многими категориями.
Вот код Python с использованием Label Encoder:
from sklearn import preprocessing le = preprocessing.LabelEncoder() le.fit(df['genres']) df['genres'] = le.transform(df['genres'])
Что такое преобразование в «фиктивную переменную»?
Это процесс создания нового двоичного столбца для каждой категории в категориальной переменной, где 0 или 1 указывают на наличие или отсутствие этой категории, например:
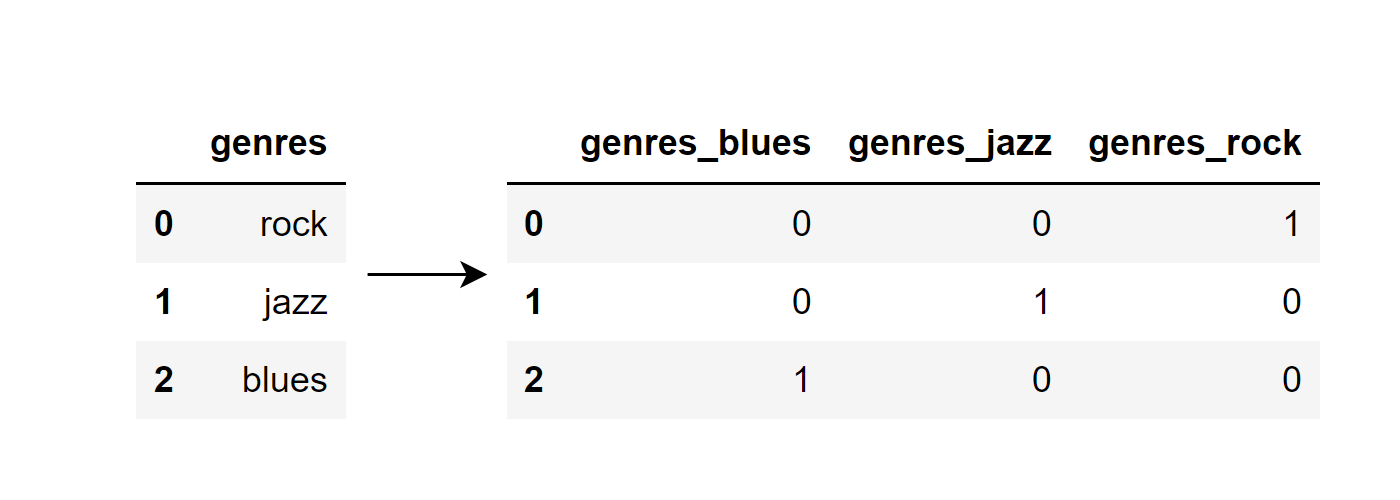
Есть два способа сделать это. Первый использует get_dummies() из библиотеки Pandas:
import pandas as pd X_encoded = pd.get_dummies(df, columns=['genres'])
Другой использует OneHotEncoder() Scikit-learn (sklearn):
from sklearn.preprocessing import OneHotEncoder enc = OneHotEncoder() enc.fit(df) X_encoded = enc.transform(df).toarray()
Думификация и One Hot Encoding — это, по сути, одно и то же. Основное отличие состоит в том, что «обманывать» — это более разговорный термин, а «горячее кодирование» — это технический термин, используемый в литературе по машинному обучению.
Почему чайники предпочтительнее других решений?
Есть несколько причин, по которым Dummies обычно предпочтительнее других методов кодирования:
Избегайте подразумеваемых порядковых отношений и предотвращайте предвзятость
Манекены создают отдельные столбцы для каждой категории, что позволяет модели изучить отношения между отдельными категориями и целевой переменной. Замена на числа и кодировщик меток, с другой стороны, подразумевает порядковую связь между категориями и не создает отдельные столбцы для каждой категории, что может привести к вводящим в заблуждение результатам, если категории не имеют внутреннего порядка.
Например, предположим, что вы заменили «рок» на 1, «джаз» на 2 и «блюз» на 3 в своем наборе данных. В этом случае ваша модель может предположить, что «джаз» в два раза важнее «рока», а «блюз» в три раза важнее «рока». Это может привести к смещению модели, поскольку она делает предположения о порядке, в котором вы присваиваете числа.
Макеты позволяют модели изучать более сложные взаимосвязи
Поскольку для каждой категории создаются отдельные столбцы, модель может изучать более сложные взаимосвязи между категориями и целевой переменной.
С другой стороны, другие упомянутые кодировщики позволяют модели изучать только общую взаимосвязь между числовым значением и целевой переменной, что может не отражать всю сложность данных.
Когда следует избегать чайников
Есть определенные ситуации, в которых «чайники» могут быть не лучшим подходом. Вот наиболее важные из них:
- Высокое количество элементов: One Hot Encoding создает отдельный столбец для каждой категории в категориальной переменной. Это может привести к большому количеству столбцов, особенно если категориальная переменная имеет много уникальных значений. В таких случаях One Hot Encoding может привести к разреженным и громоздким наборам данных, с которыми может быть сложно работать.
- Ограничения памяти. Одно горячее кодирование также может быть проблематичным, если набор данных большой и требует много памяти для хранения. Результирующий набор данных может занимать много места, что может оказаться невыполнимым, если память ограничена.
- Мультиколлинеарность. Происходит при высокой корреляции между фиктивными переменными, из-за чего коэффициенты в модели могут быть нестабильными и трудными для интерпретации. Фиктивные переменные естественно коррелированы, потому что они созданы из одной и той же категориальной переменной.
В этих ситуациях могут оказаться более подходящими альтернативные методы кодирования, такие как кодировщик меток или целевое кодирование, которые могут более эффективно обрабатывать большое число элементов.
Если вам интересно узнать больше о мультиколлинеарности и целевом кодировании, есть много других доступных ресурсов. Возможно, вы захотите ознакомиться со следующими статьями:
В этой статье подробно рассматривается проблема мультиколлинеарности и даются советы о том, как с этим бороться, углубляясь в параметры функций OneHotEncoder()и to_dummy().
В этой статье всесторонне анализируется целевое кодирование для решения проблемы размерности.
Я надеюсь, что эта статья помогла вам обрести уверенность при принятии решения о том, как обрабатывать категориальные переменные в вашем наборе данных и когда следует подумать о выходе из вашей зоны комфорта при кодировании.
Важно тщательно учитывать характеристики данных и требования модели при принятии решения о том, какой метод кодирования использовать. Две статьи, упомянутые в этом посте, являются отличными ссылками. Проверь их!
Если вам интересно прочитать другие статьи, написанные мной. Посмотрите мой репозиторий со всеми написанными мной статьями, разделенными по категориям.
Спасибо, что прочитали