"Отклонение — это наблюдение, которое настолько отличается от других наблюдений, что вызывает подозрение, что оно было создано с помощью другого механизма", — Хокинс, 1980 г.
1. Метод, основанный на правилах
Мы можем использовать подход, основанный на правилах, если аномалии можно точно идентифицировать с помощью нескольких правил.
Минусы:
- Возможна фильтрация нормальных точек
- Невозможно количественно оценить степень аномалий
2. Методы, основанные на статистике
2,1Межквартильный диапазон (IQR)
Аномалии находятся за пределами IQR (Q3-Q1)
def outlier_outside_iqr(x):
q3, q1 = np.percentile(x, [75 ,25])
iqr = q3 - q1
lower, upper = q1 - 1.5*iqr, q3 + 1.5*iqr
return lower, upper2,2 Z-показатель
Предположим, что данные нормально распределены.

где x_i — точка данных, \mu — среднее значение всех x_i, \sigma — стандартное отклонение всех x_i. После стандартизации всех данных те, которые превышают пороговое значение (например, 2,5, 3,0, 3,5), являются аномалиями.

def z_score(x):
z_score = (x - np.mean(x)) / np.std(x)
return z_score
2.3 Анализ экстремальных значений
Экстремальные значения в распределении вероятностей в совокупности называются хвостом распределения. Различные статистические методы количественно определяют вероятности хвостов распределений. Очень низкое значение вероятности хвоста указывает на то, что значение данных внутри него следует считать аномальным. Ряд хвостовых неравенств связывает эти вероятности в случаях, когда фактическое распределение недоступно.

https://stackoverflow.com/questions/47953098/python-markov-chebyshev-chernoff-upper-bound-functions
2.4 Детерминант минимальной ковариации (MCD)/гауссовская смесь (GM)
MCD: предположим, что вставки генерируются из многомерного распределения Гаусса. Установите гиперсферу (эллипсоид), которая покрывает нормальные данные, данные, выходящие за пределы эллипсоида, являются выбросом. MCD пытается оценить среднее значение и ковариационную матрицу таким образом, чтобы свести к минимуму влияние аномалий.
GM: Вставки генерируются из смеси распределений Гаусса.

Минусы:
- Зависит от дистрибутива
# Source: https://machinelearningmastery.com/model-based-outlier-detection-and-removal-in-python/ # The scikit-learn library provides access to this method via the EllipticEnvelope class from sklearn.covariance import EllipticEnvelope # identify outliers in the training dataset ee = EllipticEnvelope(contamination=0.01) yhat = ee.fit_predict(X_train) # inliers = yhat != -1
3. Методы на основе расстояния
3.1 КНН
Вычислите среднее расстояние каждой точки до ее K ближайших соседей и сравните расстояние с порогом. Если он превышает пороговое значение, он считается выбросом.
Плюсы:
- Независимость от дистрибутива
Минусы:
- Алгоритмы кластеризации оптимизированы для поиска кластеров, а не выбросов.
- Набор множества аномальных объектов данных, похожих друг на друга, будет распознан как кластер, а не как шум/выбросы.
- Невозможно количественно оценить степень аномалий каждой точки данных
from pyod.models.knn import KNN knn = KNN(method='mean', n_neighbors=5) knn.fit(X_train) y_train_pred = clf.labels_ # 0: inlier, 1: outlier y_train_scores = clf.decision_scores
4. Линейные модели
4.1 Анализ основных компонентов для обнаружения аномалий (Шью и др., 2003 г.)
Подход 1: сопоставьте данные с низкоразмерным пространством признаков, а затем посмотрите на отклонение данных. Собственные векторы из PCA отражают различные направления дисперсии исходных данных, а собственные значения представляют собой величину дисперсии в соответствующем направлении. Собственный вектор, соответствующий наибольшему собственному значению, является направлением с наибольшей дисперсией данных, что может указывать на аномальные точки данных.
Подход 2: сопоставьте данные с низкоразмерным пространством признаков, а затем сопоставьте обратно с исходным пространством. Попробуйте восстановить исходные данные с низкоразмерными функциями, чтобы увидеть размер ошибки реконструкции (X_reconstructed = X_low_dim * собственный вектор). Если точку данных нелегко реконструировать, это указывает на то, что характеристика точки данных несовместима с характеристикой общих точек данных, следовательно, это ненормальная точка. Мы можем использовать ошибки реконструкции в качестве оценок выбросов.
Плюсы:
- PCA обычно более устойчив к наличию нескольких выбросов, чем методы анализа зависимых переменных, потому что PCA вычисляет ошибки относительно оптимальной гиперплоскости, а не конкретной переменной.
Минусы:
- PCA иногда может давать плохие результаты, когда масштабы разных # измерений сильно различаются.
# Source: https://github.com/jeffprosise/Machine-Learning/blob/master/Anomaly%20Detection%20(PCA).ipynb from sklearn.decomposition import PCA pca = PCA(n_components=1, random_state=0) def is_anomaly(data, pca, threshold): pca_data = pca.transform(data) restored_data = pca.inverse_transform(pca_data) loss = np.sum((data - restored_data) ** 2) return loss > threshold
4.2 Одноклассовые машины опорных векторов (SVM)
Идея состоит в том, чтобы найти гиперплоскость, чтобы отделить данные от начала координат и максимизировать расстояние от гиперплоскости до начала координат.
Мы можем получить SVM одного класса, используя SVDD (описание домена опорного вектора). Для SVDD мы ожидаем, что все выборки, которые не являются аномалиями, являются выбросами. Он также использует гиперсферу вместо гиперплоскости для разделения данных. Алгоритм получает сферическую границу вокруг данных в пространстве признаков, а затем минимизирует объем этой гиперсферы.
Плюсы: никаких предположений о распределении данных
Минусы: чувствителен к выбросам

from sklearn import svm clf = svm.OneClassSVM(gamma=0.1) clf.fit(X) y_pred = clf.predict(X) # 1: inlier, -1: outlier n_error_outlier = y_pred[y_pred == -1].size
5. Методы на основе плотности
5.1 Фактор локального выброса (Бройнинг и др., 2000 г.)
Алгоритм на основе плотности — алгоритм сравнивает плотность выборки с соседними точками. В частности, для каждой точки данных найдите ее k-ближайшего соседа и рассчитайте оценку LOF.
Определения:
- K-distance(A)= расстояние между точкой A и ее k-м ближайшим соседом
- Расстояние достижимости (RD) точки A от другой точки B, RD(A,B) = max(K-расстояние(B), расстояние(A,B))
- Локальная плотность достижимости (LRD) точки A является обратной средней RD точки A от ее соседей.
- Фактор локального выброса (LOF) — это отношение среднего LRD k-соседей A к LRD A
Если LOF(A) около 1, это означает, что локальная плотность точки данных A аналогична плотности ее соседей. Если LOF(A) ‹ 1, это означает, что A находится в относительно плотной области и не похожа на точку аномалии. Если LOF(A) > 1, это означает, что точка A более удалена от других точек и, вероятно, является выбросом.

Плюсы:
- Хорошо, когда плотность данных не соответствует набору данных
- Может количественно оценить степень аномалий каждой точки данных
- Не требует предположений о распределении данных
Минусы:
- Точность может быть нарушена в больших размерах
- Оценка LOF представляет собой отношение и, следовательно, ее трудно интерпретировать.
- Необходимо вычислить расстояние между точками данных, что приводит к временной сложности O (n²) (позже появились алгоритмы, которые повысили эффективность, например, FastLOF (Goldstein, 2012) сначала случайным образом делит все данные на несколько подмножеств, а затем вычисляет LOF значение в каждом подмножестве. Он удаляет оценку LOF ‹1 и обновляет оценку KNN и LOF)
# Source: https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.LocalOutlierFactor.html from sklearn.neighbors import LocalOutlierFactor X = [[-1.1], [0.2], [101.1], [0.3]] clf = LocalOutlierFactor(n_neighbors=2) clf.fit_predict(X) # array([ 1, 1, -1, 1]) clf.negative_outlier_factor_ # array([ -0.9821..., -1.0370..., -73.3697..., -0.9821...])
6. Метод на основе дерева
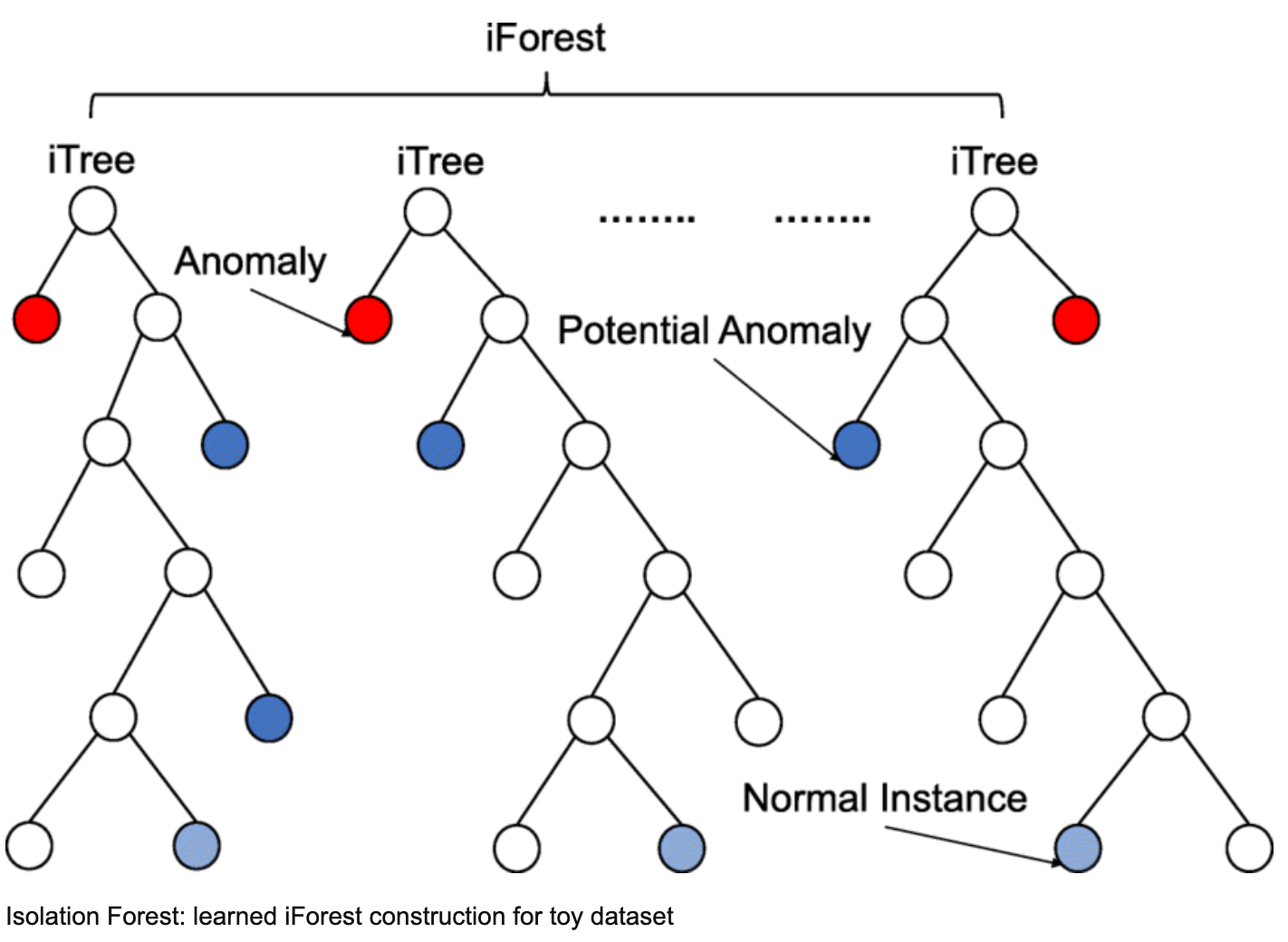
6.1 Изолированный лес (Лю и др., 2008 г.)
Метод на основе дерева. Он вычисляет, сколько разбиений узлов требуется, чтобы каждая точка данных была разделена на независимое пространство. Поскольку выбросы находятся далеко от выбросов, их можно легко выделить в независимое пространство с небольшим количеством разбиений.
Поскольку каждое разделение является случайным, поэтому нам нужен метод ансамбля для получения сходимости (метод Монте-Карло), многократное разделение с самого начала, а затем усреднение результата. iForest состоит из t iTree, каждое из которых представляет собой структуру двоичного дерева.
Шаги:
- Случайным образом выберите X выборок из обучающих данных в качестве подвыборок и поместите их в корневой узел дерева.
- Случайным образом укажите размер и случайным образом сгенерируйте точку отсечения p (между минимумом и максимумом этого размера)
- Генерируется гиперплоскость, которая делит текущее пространство на два подпространства — сэмплы из подпространства A перейдут к узлу A’, а сэмплы из подпространства B перейдут к узлу B’.
- Повторяйте шаги 2 и 3, пока в узле не будет только одна выборка или конечный узел не достигнет предельной глубины.

Получив t iTree, мы можем использовать его для оценки тестовых данных. Для точки данных x пусть x проходит через каждое iTree, смотрите, какая глубина требуется для разделения x на независимое пространство, затем получайте средняя глубина.
Как только у нас будет средняя глубина для каждой точки данных, установите порог. Те, у которых глубина ‹ порога, являются аномалиями.
Плюсы:
- Никаких предположений о распределении данных
- Работает с многомерными данными
Минусы:
- Реализация может быть длительной и требовать более высокой вычислительной мощности, если она не оптимизирована должным образом.
- Чувствителен только к глобальным аномалиям
# Source: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html from sklearn.ensemble import IsolationForest X = [[-1.1], [0.3], [0.5], [100]] clf = IsolationForest(n_estimators=100, max_samples='auto', contamination=0.05, max_features=4, bootstrap=False, random_state=0).fit(X) clf.predict([[0.1], [0], [90]]) #array([ 1, 1, -1])
7. Графические модели
Используйте информацию об учетной записи и устройстве, полученную от пользователей, входе в систему, размещении заказов и т. д., мы можем создавать сети взаимоотношений между пользователями и находить мошенничество с помощью
- выявление необычных сетевых структур и сообществ внутри сети
- определение хороших/плохих пользователей через сетевые отношения с использованием, например. распространение меток, модель SIR и т. д.
8. Автоэнкодеры
Мы можем создать автоэнкодер с частью кодирования и частью декодирования, масштабировать данные, подогнать к обычным данным (без аномалий), получить вложения для обычных данных и данных о мошенничестве, а затем визуализировать встраивание/обучить классификатор для классификации вложений.
# Source:https://www.zhihu.com/question/30508773?sort=createdinput_layer = Input(shape=(X.shape[1],))## encoding part encoded = Dense(100, activation='tanh', activity_regularizer=regularizers.l1(10e-5))(input_layer) encoded = Dense(50, activation='relu')(encoded)## decoding part decoded = Dense(50, activation='tanh')(encoded) decoded = Dense(100, activation='tanh')(decoded)## output layer output_layer = Dense(X.shape[1], activation='relu')(decoded)autoencoder = Model(input_layer, output_layer) autoencoder.compile(optimizer="adadelta", loss="mse")x = data.drop(["Class"], axis=1) y = data["Class"].values x_scale = preprocessing.MinMaxScaler().fit_transform(x.values) x_norm, x_fraud = x_scale[y == 0], x_scale[y == 1] autoencoder.fit(x_norm[0:2000], x_norm[0:2000], batch_size = 256, epochs = 10, shuffle = True, validation_split = 0.20); hidden_representation = Sequential() hidden_representation.add(autoencoder.layers[0]) hidden_representation.add(autoencoder.layers[1]) hidden_representation.add(autoencoder.layers[2])norm_hid_rep = hidden_representation.predict(x_norm[:3000]) fraud_hid_rep = hidden_representation.predict(x_fraud)
Ссылка: