В этом посте рассказывается о лекциях Справедливость нашего курса Машинное обучение в производстве. Остальные главы смотрите в содержании.

Справедливость — одна из наиболее обсуждаемых тем в машинном обучении. Она возникла из-за осознания того, как модели, обученные на данных, могут выявлять предубеждения в этих данных и, возможно, даже усиливать существующие предубеждения. Несправедливые модели могут привести к продуктам, которые просто не подходят для некоторых групп населения, которые вызывают дискриминацию, усиливая стереотипы, и создают неравенство. Существует множество примеров несправедливых моделей, таких как модели медицинского диагноза, которые имеют низкую точность для всех, кроме взрослых белых мужчин, модели рецидивизма, учитываемые при вынесении приговора, которые могут чаще предлагать оставить чернокожих в заключении, и языковые модели, которые усиливают пол. стереотипы, предполагая, что медицинские работники-мужчины являются врачами, а женщины-медсестрами.
Понятие справедливости трудно точно уловить. На протяжении тысячелетий философы обсуждали, какие решения являются справедливыми, и на протяжении сотен лет общества пытались урегулировать определенные (различные) понятия справедливости в виде закона. В сообществе машинного обучения ведется множество дискуссий о различных мерах справедливости и о том, как изменить конвейер машинного обучения, чтобы оптимизировать модель для таких мер справедливости. При создании продукта с компонентами машинного обучения справедливость необходимо обсуждать на всех этапах процесса разработки и во время операций, которые включают как ML, так и не-ML части системы. Такие обсуждения часто обязательно носят политический характер — например, они включают в себя обсуждение между многими заинтересованными сторонами того, какое понятие справедливости имеет отношение к продукту (и соответствует закону), при поиске различных компромиссов и конфликтующих предпочтений. Как и в случае с другими ответственными инженерными свойствами, справедливость явно не является проблемой только на уровне модели, но требует рассуждений о всей системе и о том, как система взаимодействует с пользователями и остальным миром.
В этой главе мы действуем в три этапа. Во-первых, мы начнем с обзора общих проблем и вреда, которые обсуждаются в контексте справедливости в машинном обучении, и введем различные понятия справедливости. Во-вторых, мы даем обзор подходов к измерению и улучшению справедливости на уровне модели. Наконец, мы уменьшаем масштаб и обсуждаем общесистемные соображения, в том числе важную роль разработки требований и интеграции процессов, когда речь идет о справедливости.
Тема честности в машинном обучении слишком многогранна и сложна, чтобы всесторонне осветить ее в этой главе. На данный момент ежегодно публикуются тысячи статей о справедливости машинного обучения и проводятся целые конференции, посвященные этой теме. Следуя представлению о Т-образных профессионалах, мы предоставим интуитивно понятный обзор основополагающих проблем, который должен помочь вести разумный разговор по теме и определить, когда обратиться за помощью или углубиться. Также обратите внимание, что примеры в этой главе сформированы современным дискурсом и терминологией, использовавшейся в США на момент написания, что может потребовать некоторой абстракции для перевода в другие культурные контексты.
Пример работы: заявки на ипотеку
Справедливость машинного обучения часто и противоречиво обсуждается во многих приложениях, и мы упомянем многие из них в этой главе. В качестве рабочего примера мы будем использовать автоматизацию принятия кредитных решений по заявкам на ипотеку.
Ипотечный кредит в банке предоставляет большую сумму денег покупателю дома для погашения в течение длительного периода. Для заявителя доступ к кредиту может быть важной экономической возможностью, а исключение может стать ловушкой для лиц с ограниченной карьерной мобильностью. Для банка принятие решения об одобрении ипотечного кредита является важным решением, сопряженным со значительным финансовым риском. Банк должен решить, считает ли он, что заявитель сможет погасить кредит — если заявитель погашает кредит, банк получает прибыль от процентов и комиссий, но если заявитель не выплачивает кредит, банк может потерять значительные суммы. деньги, особенно если дом сейчас стоит меньше кредита.
Заявители, как правило, предоставляют много информации (прямо или косвенно), такой как доход, другие долги и прошлые платежи, а также стоимость дома, которую банк использует для прогнозирования того, будет ли погашен кредит и стоит ли ожидаемая прибыль. риск для конкретного приложения при заданной процентной ставке. Информация о прошлых долгах и платежах часто сжата в собственном кредитном рейтинге, который обычно предназначен для прогнозирования кредитоспособности заявителя, отслеживаемого сторонними кредитными бюро.
Заявки на ипотеку обычно рассматриваются банковскими служащими. Существует задокументированная история дискриминации при принятии решений о кредитовании в США, особенно практика, известная как красная черта, когда банки отказывали в кредитах в определенных районах или взимали более высокие процентные ставки. Поскольку кредит обеспечивает экономические возможности, а многие семьи накапливают богатство за счет домовладения, дискриминация в практике кредитования способствовала значительному неравенству в благосостоянии между различными группами населения. Например, Федеральная резервная система сообщает, что в 2019 году белые семьи в среднем владеют в 7,8 раза большим состоянием, чем черные семьи в США, и получают на 70 процентов больше дохода. Эти различия также имеют последующие последствия в ипотечных заявках.

Автоматизация решений по ипотечным кредитам потенциально может быть более объективной, например, исключая человеческую предвзятость и фокусируясь только на факторах, которые фактически предсказывают способность погасить кредит на основе прошлых данных. Однако, как мы обсудим, возникает много вопросов о том, что считается справедливым и может ли модель, обученная на необъективных исторических данных, быть справедливой.
Концепции справедливости
Понятие справедливости трудно уловить. Единого общепринятого определения не существует. По сути, дискурс справедливости задает вопросы о том, как относиться к людям и этично ли относиться к разным группам людей по-разному. Если к двум группам людей систематически относятся по-разному, это часто считается несправедливым. Несправедливое поведение людей по отношению к другим людям часто коренится во враждебности или предпочтении определенных характерных признаков членов социальной группы, таких как пол, цвет кожи, этническая или национальная принадлежность, класс, возраст и сексуальные предпочтения.
Понятия справедливости и неравных стартовых позиций
Что такое справедливость? Разные люди могут не всегда соглашаться с тем, что является справедливостью, а понятие справедливости может зависеть от контекста, поэтому один и тот же человек может предпочесть разные понятия справедливости в разных контекстах. Чтобы на время отвлечься от трудных дискуссий о поле, расе и других демографических характеристиках, давайте проиллюстрируем различные взгляды на справедливость на простом примере деления пирога, испеченного вместе, группой людей:
- Равные куски: каждый член группы получает кусок пирога, равный кусочку каждого другого члена. Размер ломтика не зависит от качеств или предпочтений каждого отдельного человека и не зависит от того, сколько труда они вложили в выпечку. Все в группе считаются равными, и любая разница в размере кусочков будет считаться несправедливой.
- Большие куски для активных пекарей: члены группы признают, что некоторые участники были более активны при выпечке пирога, в то время как другие в основном просто сидели сложа руки. Они дают большие куски пирога тем людям, которые были наиболее активны в выпечке. Предоставление всем одного и того же размера фрагмента будет считаться несправедливым, если участники выполнят существенно разный объем работы.
- Большие куски для неопытных участников: группа дает большие куски участникам с меньшим опытом выпечки (например, детям), потому что у них меньше возможностей испечь пирог самостоятельно и больше пользы от коллективного опыта выпечки. Простое рассмотрение индивидуального вклада при допущении, что все члены группы имеют одинаковую подготовку и опыт, будет считаться несправедливым по отношению к тем, у кого было меньше возможностей в прошлом.
- Большие ломтики для голодных: группа признает, что члены группы имеют разную степень желания съесть пирог (например, некоторые только что поели, детям в группе в целом может потребоваться меньше калорий). Таким образом, группа назначает более крупные куски тем членам, которые голодны. Другие формы деления пирога были бы сочтены несправедливыми, поскольку они не учитывают различные потребности отдельных членов.
- Больше пирога для всех: у каждого должно быть столько пирога, сколько он хочет. Если необходимо, группа печет еще, пока все не будут довольны. Пока пирог является дефицитным ресурсом, который нужно тщательно делить, любая форма дележа будет считаться кем-то несправедливой.
Хотя круговой сценарий прост и несколько глуповат, он иллюстрирует несколько контрастирующих, конкурирующих и взаимоисключающих взглядов на справедливость — независимо от того, принимаются ли решения людьми или машинами. Разногласия по поводу справедливости часто возникают из-за различных соображений того, что является справедливым. Ключевые моменты разногласий обычно заключаются в том, какие атрибуты считаются важными или запрещенными, например, следует ли учитывать вложенный труд или голод при разделе пирога и является ли учет возраста или опыта неуместным. Тот факт, что некоторые атрибуты могут быть выбраны участниками преднамеренно, в то время как другие могут быть инертными или фундаментально связанными с личностью или историей человека, может еще больше усложнить обсуждение того, какие атрибуты следует учитывать.
Психологические эксперименты показывают, что у большинства людей есть общее интуитивное понимание того, что справедливо во многих ситуациях. Например, когда вознаграждение зависит от количества вкладов, и участники могут выбирать свой вклад, большинство людей считают справедливым делить вознаграждение пропорционально вкладам — в нашем примере с пирогом мы могли бы предложить более крупные куски более активным пекарям. Также большинство людей согласны с тем, что для того, чтобы решение было справедливым, личные характеристики, не влияющие на вознаграждение, такие как пол или возраст, не должны учитываться при распределении вознаграждения.
Справедливость с неравными начальными позициями. Споры о том, что является справедливым, возникают, в частности, когда люди начинают с разных позиций, индивидуально или в группе. С одной стороны, разные стартовые позиции могут быть обусловлены инертными различиями, например, у более молодых членов команды будет (в среднем) меньше возможностей получить опыт выпечки. С другой стороны, разные исходные позиции часто возникают из-за поведения в прошлом, на которое в значительной степени могут влиять прошлые несправедливости, такие как красная черта в нашем примере с ипотечной заявкой, способствующая неравному распределению богатства.
Когда разные группы начинают с неравных стартовых позиций, есть три основных взгляда на справедливость:
- Равенство (сведение к минимуму неодинакового обращения): ко всем людям следует относиться одинаково и предоставлять равные возможности для участия в соревнованиях, независимо от их разного стартового положения. Справедливость фокусируется на процедуре принятия решений, а не на результатах. Например, мы учитываем, сколько усилий люди вкладывают в выпечку, независимо от способностей. Что касается заявок на ипотеку, мы гарантируем, что принимаем решения по ипотеке исключительно на основе ожидаемой способности заявителя погасить кредит, независимо от членства в группе, то есть мы даем всем с одинаковым уровнем риска (например, с учетом дохода) одинаковый доступ к кредиту, даже если члены одной группы чаще подвергаются более высокому риску (из-за более низкого дохода) и, таким образом, получают меньше кредита, чем члены другой группы. С точки зрения равенства решение, основанное исключительно на релевантных исходных данных (например, способности погашать на основе текущего дохода), считается справедливым, поскольку оно дает всем одинаковые возможности (к равенству возможностей) на основе индивидуальных атрибуты (например, доход, богатство), а не на основе членства в группе. Понятие меритократии часто ассоциируется с этой основанной на равенстве концепцией справедливости.
- Справедливость (сведение к минимуму неравномерного воздействия): если предположить, что у разных людей разное начальное положение, подход, основанный на равенстве, отдает предпочтение предоставлению большего количества ресурсов членам групп, находящихся в неблагоприятном положении, с целью достижения более равных результатов. В ипотечном сценарии мы могли бы признать, что прошлые несправедливости вызвали неравенство в богатстве и доходах между группами, и мы должны компенсировать это, принимая более рискованные ссуды от неблагополучных групп, чтобы предоставить им пропорционально больше возможностей для продвижения вверх за счет кредита. Вмешательства, основанные на справедливости, могут включать преднамеренное предоставление большего количества ресурсов отдельным лицам или группам с худшим начальным положением. Этот подход часто называют позитивными действиями. Справедливость, основанная на равенстве, направлена на распределительную справедливость, которая уменьшает разрозненные воздействия (в сторону равенства результатов), независимо от входных данных и намерений. С точки зрения справедливости справедливость достигается, когда результаты (например, доступ к кредиту) одинаковы для разных групп, обычно за счет компенсации различных исходных позиций.
- Справедливость. Иногда справедливость указывается в качестве желаемого третьего варианта, который коренным образом устраняет первоначальный дисбаланс в системе, обычно либо устраняя дисбаланс до принятия решения, либо устраняя необходимость принять решение в первую очередь. Например, если бы мы заплатили репарации за прошлые несправедливости, мы могли бы увидеть аналогичное распределение богатства по демографическим группам; если бы все жилье находилось в государственной собственности и предоставлялось в качестве основного права, нам, возможно, не нужны были бы банки для принятия решений по ипотеке. Решения, основанные на справедливости, как правило, переосмысливают всю социальную систему, в которой изначально существовал дисбаланс, выходящий за рамки продукта, для которого разрабатывается модель.
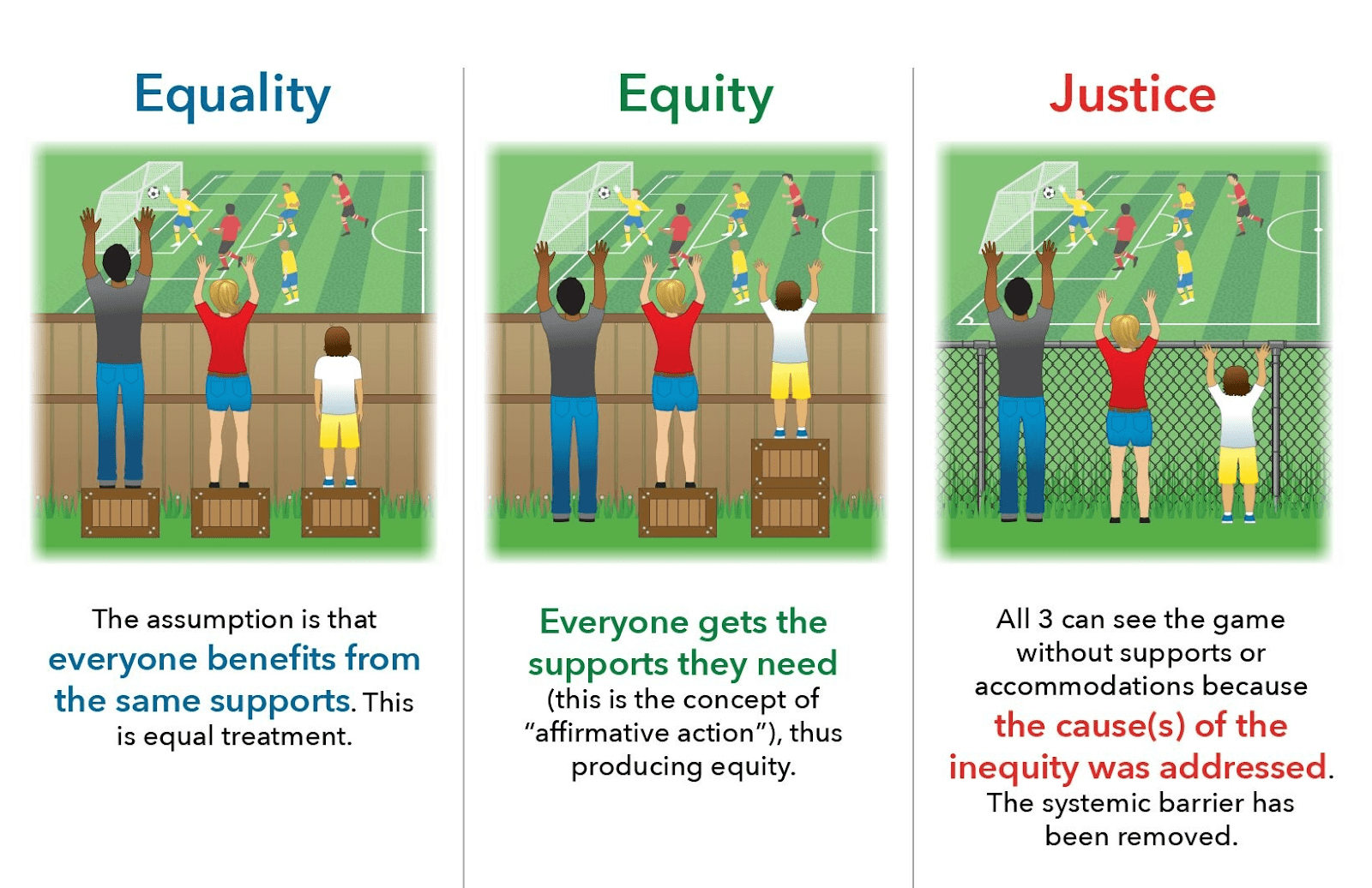
Обратите внимание, что дискуссии о равенстве и равенстве в справедливости сильно зависят от того, какие атрибуты и исходные данные учитываются и какие различия связаны с достоинствами или с системными недостатками определенных групп. Часто представление о том, в какой степени группа исходит из невыгодного положения, уже вызывает споры. Разработчик процедуры принятия решения, которая включает в себя модели с машинным обучением, должен принципиально решить, какой подход использовать в отношении того, какие атрибуты и входные данные, а также различные решения могут быть подходящими в различных контекстах. Дискуссии вокруг них часто уходят корнями в давние традиции в философии и праве. Например, как мы обсудим, в юридической литературе США, посвященной кредитным решениям, известно как о несопоставимом отношении, так и о несопоставимом воздействии, а в последнее время суды больше внимания уделяют несопоставимому воздействию. Существует также заметный политический раскол, когда люди с правыми политическими взглядами, как правило, предпочитают понятия справедливости, основанные на качестве меритократии, и порицают инициативы, основанные на равенстве, как обратную дискриминацию (дискриминация группы большинства из-за неравного обращения), в то время как левые люди склонны подчеркивать результаты и справедливость, основанные на справедливости, которые бросают вызов статус-кво.
Ущерб от дискриминационных решений
В техническом смысле мы говорим, что процедура принятия решения дискриминирует атрибут, если она использует этот атрибут в процессе принятия решения, но на практике мы заботимся о том, чтобы избежать «неправомерной дискриминации» когда использование атрибута для решения не оправдано и дискриминация может нанести вред пострадавшему населению. Вопрос о том, является ли использование атрибута для принятия решений оправданным, зависит от предметной области. Например, использование пола клиента определяет, нарушает ли утверждение ипотечного кредита антидискриминационные законы (в США), но использование пола пациента при диагностике медицинской проблемы может иметь большое значение, поскольку распространенность некоторых состояний сильно коррелирует. к полу пациента (например, рак молочной железы, самоубийство).
На данный момент в исследованиях и популярной прессе было показано множество примеров вреда от моделей с машинным обучением. В целом их можно разделить на вред распределения и вред представительства.
Вред распределения. Если модель неправомерно дискриминирует демографическую группу, она может удерживать ресурсы для этой демографической группы или предоставлять более низкое качество обслуживания для этой демографической группы. В нашем примере с ипотекой автоматизированная система может (неправомерно) выдавать меньше кредитов некоторым группам населения. Автоматизированная система проверки резюме может (неправомерно) выделять меньшее количество мест для интервью для соискателей-женщин. Продукт может обеспечивать низкое качество обслуживания для некоторых групп, например, модель распознавания лиц в службе обмена фотографиями, которая плохо работает на фотографиях с более темной кожей. Модель прогнозирования рецидивизма может (ошибочно) предполагать более высокий риск рецидива для чернокожих ответчиков, что приводит к более длительным срокам тюремного заключения.

Вред представительства. Даже если решения не предусматривают распределения ресурсов, дискриминационные решения могут причинить вред, искажая представительство определенных групп в организациях, усиливая стереотипы и (случайно) оскорбляя и унижая людей. Примеры включают системы естественного языка, которые систематически изображают врачей мужчинами, а медсестры женщинами, рекламные системы, которые показывают рекламу, ассоциирующую имена чернокожих с преступностью, и системы обнаружения объектов в фотоприложениях, которые идентифицируют черных людей как горилл.
Обратите внимание, что неправомерная дискриминация в одной и той же системе может нанести несколько видов вреда: например, система найма, в которой женщины систематически ставятся ниже, чем мужчины, удерживает ресурсы, предоставляет разное качество услуг разным группам населения, укрепляет стереотипы и может усугублять существующее неравенство в представительстве.
Источники предвзятости
Машинное обучение изучает модели из данных. Проблемы со справедливостью часто возникают из-за предвзятости в обучающих данных, так что модель, обученная на этих данных, воспроизводит предвзятость в данных. Существует множество различных источников систематической ошибки, связанной с тем, как данные отбираются, агрегируются, маркируются и обрабатываются. Понимание различных источников смещения может помочь нам быть более добросовестными при выборе данных, определении процедур сбора и маркировки данных, моделей обучения и моделей аудита.
Историческая предвзятость. Данные для обучения, как правило, отражают текущее состояние мира, на которое может повлиять давняя история предвзятости, а не состояние мира, к которому может стремиться разработчик системы, если он учитывает свои цели тщательно. Например, в 2022 году менее 7% генеральных директоров из списка Fortune 500 были женщинами и едва ли 1% были чернокожими, поэтому неудивительно, что модель, обученная на случайной репрезентативной выборке, будет ассоциировать роль генерального директора с белыми мужчинами, что может быть отражено. например, в результатах поисковых систем по фотографиям. Как описывает Кэти О’Нил в Оружии математического разрушения: Процессы больших данных систематизируют прошлое. Они не изобретают будущее. Для этого требуется нравственное воображение, а это могут обеспечить только люди. Если разработчик системы стремится сломать существующие стереотипы, необходимы дополнительные вмешательства, такие как преднамеренная балансировка результатов по демографическим группам, что усиливает репрезентативность исторически недопредставленных группы. Например, поиск фотографий Google для генерального директора в настоящее время сначала возвращает изображение женщины-гендиректора и еще нескольких женщин среди лучших результатов, но чернокожих генеральных директоров нет до второй страницы результатов.

Испорченные метки. Ярлыки для обучающих данных обычно создаются (прямо или косвенно) людьми, и эти люди могут быть предвзятыми, когда они назначают метки. Например, когда банковских служащих просят оценить риск заявки на получение ипотечного кредита, они могут показать свое предубеждение за или против социальных групп в ярлыках, которые они присваивают, например, присваивая более низкие оценки риска некоторым демографическим группам, потому что они бессознательно считают их таковыми. более целеустремленными и успешными в группе. Если ярлыки косвенно выводятся из действий, таких как запись решений человека об ипотеке в банке, предвзятые действия человека могут привести к сомнительным ярлыкам. Если используются прошлые данные, это становится примером исторической предвзятости. В принципе, любой метод, который может уменьшить предвзятость при принятии решений человеком (например, использование стандартизированных процессов, обучение неявной предвзятости), может использоваться для уменьшения предвзятости в процессе маркировки.
Асимметричная выборка. Многие решения связаны с тем, как создаются обучающие данные, включая то, что считать целевым распределением, как выбирать из целевого распределения и какую информацию собирать о каждой выборке. Не существует такой вещи, как «объективные необработанные данные» — то, что обычно считается необработанными данными, является результатом многих явных или неявных решений. Каждое решение о том, какие данные включать и как их регистрировать, может быть предвзятым и может исказить выборку. Например, криминальная статистика, используемая в качестве данных для моделирования будущей преступности, сильно искажена решениями о том, где полиция ищет преступления и какие преступления они ищут: (1) если полиция предполагает, что в определенных районах больше преступности, они будут патрулировать эти районы. район больше и найти больше случаев преступления, даже если преступление было фактически равномерно распределено по районам. (2) Если полиция будет больше следить за преступлениями, связанными с наркотиками, а не за инсайдерской торговлей или кражей заработной платы, и с большей вероятностью произведет аресты, а не вынесет предупреждения за некоторые правонарушения, эти правонарушения будут более заметны в статистике преступности и, следовательно, в обучающих данных. То есть способ сбора данных о преступности будет коренным образом влиять на обучающие данные и, следовательно, на модели, а предвзятость в процессе выборки может привести к дискриминационным решениям обученной модели. Чтобы уменьшить систематическую ошибку из-за асимметричной выборки, нам необходимо тщательно пересмотреть все решения, связанные с тем, какие данные собирать и как они регистрируются.
Ограниченные функции. Решения могут основываться на функциях, которые являются прогнозирующими и точными для большей части целевого распределения, но не для некоторых других частей распределения. Такая модель может иметь слепые зоны для определенных групп населения, для которых она обеспечивает низкое качество обслуживания, поскольку используемые данные бесполезны для прогнозов в отношении этой группы населения. Это часто бывает, когда слабые прокси используются в качестве признаков, когда предполагаемое качество трудно измерить. Например, система ранжирования заявок на поступление в аспирантуру может в значительной степени полагаться на рекомендательные письма и быть хорошо откалибрована для абитуриентов, которые могут запрашивать письма от наставников, знакомых с культурой и жаргоном таких писем в США, но может плохо работать для иностранных абитуриентов. из стран, где такие письма не распространены или где такие письма выражают поддержку другим жаргоном. Чтобы уменьшить систематическую ошибку, мы должны тщательно изучить все признаки и проанализировать, могут ли они быть менее предсказуемыми для определенных подгрупп.
Несоответствие размера выборки. Обучающие данные могут быть недоступны в равной степени для всех частей целевого распределения, в результате чего модель обеспечивает гораздо лучшее качество обслуживания для входных данных, представленных большим количеством обучающих данных. Например, упомянутые выше различия в алгоритмах распознавания лиц часто можно объяснить тем фактом, что существует гораздо больше помеченных обучающих данных для фотографий белых мужчин, чем для других демографических данных. Субпопуляция может быть плохо представлена в обучающих данных, потому что (1) эта субпопуляция составляет небольшое меньшинство всего целевого распределения или (2) потому что они менее представлены в результате принятия решений в процессе сбора данных. Например, религиозная группа сикхов составляет менее 0,2 процента населения США каждая, и, следовательно, случайная выборка будет включать очень мало из них; набор фотографий из социальных сетей, скорее всего, будет представлять людей, которые считают себя привлекательными, потому что они сами решают размещать больше фотографий. Без вмешательства модели всегда могут быть смещены в сторону тех групп населения, которые уже больше представлены в целевом распределении, или тех, о которых легче собрать данные — алгоритм машинного обучения может просто рассматривать данные меньшинства населения как выбросы или шум, который следует игнорировать. Чтобы обеспечить аналогичные уровни обслуживания также для небольших или менее доступных групп населения, может потребоваться преднамеренная избыточная выборка данных из этих групп населения. См. также обсуждение нарезки для оценки модели в главе Качество модели: нарезка, возможности, инварианты и другие стратегии тестирования модели.
Доверенные лица. Чтобы уменьшить неправомерную дискриминацию, мы можем избегать сбора или удаления атрибутов, которые являются конфиденциальными и не должны влиять на решение, например пол, раса и этническая принадлежность при принятии решения о кредитовании. Тем не менее, машинное обучение хорошо подходит для использования других функций в качестве прокси, которые коррелируют с удаленными атрибутами. Например, модель, поддерживающая решения по ипотечному кредитованию, может использовать адрес человека или его активность в социальных сетях для (вероятностного) вывода о расовой принадлежности человека; алгоритм найма может использовать информацию о наградах и внеклассных мероприятиях (например, «группа поддержки», «наставник сверстников для студентов колледжей в первом поколении», «парусная команда», «классическая музыка») в качестве косвенных показателей для (вероятностного) вывода о поле человека. и социальный класс. Если обучающие данные смещены (например, из-за исторической погрешности, испорченных меток), модель может уловить эту погрешность через эти прокси, даже если прямая функция удалена. Чтобы уменьшить систематическую ошибку, нам может потребоваться тщательно искать атрибуты, которые коррелируют с удаленным атрибутом, и либо удалить их, либо статически учитывать корреляцию в процессе обучения.

Цикл обратной связи. Если модель обучается итеративно или постоянно на новых данных, историческая систематическая ошибка в обучающих данных может быть усилена дискриминационными решениями модели с машинным обучением. Например, отправка большего числа полицейских в районы, которые исторически перенасыщены полицией, на основе модели прогнозирования преступности обнаружит там больше преступлений (просто при более тщательном поиске) и, следовательно, создаст еще более предвзятые обучающие данные для следующего обновления модели. Петли обратной связи возникают в результате взаимодействия между программной системой и ее окружением (через исполнительные механизмы и датчики). Предвидение петель обратной связи посредством тщательной разработки требований (см. главу «Мир и машина») — это первый шаг к пониманию и смягчению порочных кругов подкрепляющей предвзятости.

Юридические аспекты
Философы и ученые-правоведы обсуждали понятия справедливости на протяжении тысячелетий, а психологи и экономисты также изучали, что люди считают справедливым в различных контекстах. В результате длительных политических процессов некоторые понятия справедливости и дискриминации определяются законом и имеют юридическую силу для решений в определенных областях, включая решения, принимаемые программными системами и моделями с машинным обучением.
Конкретные детали различаются в зависимости от юрисдикции, но следующие характеристики в настоящее время защищены от дискриминации и преследований федеральным антидискриминационным законом США:
- Раса (Закон о гражданских правах 1964 г.)
- Религия (Закон о гражданских правах 1964 г.)
- Национальное происхождение (Закон о гражданских правах 1964 г.)
- Пол, сексуальная ориентация и гендерная идентичность (Закон о равной оплате труда 1963 г., Закон о гражданских правах 1964 г. и Босток против Клейтона)
- Возраст (40 лет и старше, Закон о возрастной дискриминации при приеме на работу от 1967 г.)
- Беременность (Закон о дискриминации беременных 1978 г.)
- Семейное положение (предпочтение за или против наличия детей, Закон о гражданских правах 1968 г.)
- Статус инвалидности (Закон о реабилитации 1973 года; Закон об американцах-инвалидах 1990 года)
- Статус ветерана (Закон о помощи ветеранам Вьетнамской эры в адаптации 1974 г.; Закон о правах на трудоустройство и повторное трудоустройство в унифицированных службах 1994 г.)
- Генетическая информация (Закон о недискриминации генетической информации от 2008 г.)
Некоторые домены особенно регулируются, часто из-за прошлых проблем с дискриминацией. Например, Закон о справедливом жилищном обеспечении (Разделы VIII и IX Закона о гражданских правах 1968 г. и последующие поправки) запрещает дискриминацию при принятии решений о продаже или аренде жилья по признаку расы, цвета кожи, религии, или национальное происхождение, пол, сексуальная ориентация, гендерная идентичность, статус инвалидности и наличие детей; Дискриминация также запрещена по этим атрибутам, касающимся цены и условий продажи / аренды, решений о ремонте, рекламы или доступа к удобствам. Другие регулируемые области включают кредит (Закон о равных кредитных возможностях), образование (Закон о гражданских правах 1964 г.; Поправки об образовании 1972 г.), трудоустройство (Закон о гражданских правах 1964 г.) и общественные помещения (например, гостиницы). , рестораны, театры, розничные магазины, школы, парки; Раздел II Закона о гражданских правах 1964 года и Раздел III Закона об американцах-инвалидах 1990 года).
В судах США аргументы в делах о дискриминации могут включать доказательства несопоставимого отношения к делу (например, документы, подтверждающие, что в ипотеке было отказано из-за пола заявителя) и доказательства несопоставимого воздействия (например, доказательства того, что банк отклоняет заявки по значительно более высокой ставке, чем одна группа, чем другая). Стандарты для доказательств и то, как рассматриваются различные формы доказательств, могут зависеть от конкретного дела и прецедентного права, связанного с ним.
С 2020 года Федеральная торговая комиссия США (FTC) начала прямо сообщать о том, что они считают машинное обучение подпадающим под действие действующего антидискриминационного законодательства, например, Закон FTC запрещает недобросовестные или вводящие в заблуждение методы. Это может включать продажу или использование, например, алгоритмов с расовой предвзятостью. Они явно угрожают возможностью действий правоохранительных органов, Если, например, компания приняла решение о кредите на основании почтового индекса потребителей. Кодексы, приводящие к «несоизмеримому воздействию на определенные этнические группы, Федеральная торговая комиссия может оспорить эту практику в соответствии с [Законом о равных кредитных возможностях]».
Измерение и улучшение справедливости на уровне модели
В сообществе машинного обучения многие дискуссии сосредоточены на измерении различных понятий справедливости для решений данной модели и на способах улучшения измеряемой справедливости на уровне модели путем вмешательства во время обработки данных или обучения. Различные понятия справедливости, которые мы обсуждали выше, также отражаются в различных мерах справедливости. Мы иллюстрируем три группы мер, которые обычно обсуждаются, хотя было предложено много других.
Обычно мы измеряем справедливость модели в отношении одного или нескольких защищенных атрибутов. Защищенные атрибуты — это подмножество признаков, разделяющих демографические группы, в отношении которых мы обеспокоены неправомерной дискриминацией.
Анти-классификация
Антиклассификация — это простой критерий справедливости, согласно которому модельне должна использовать защищенные атрибуты при прогнозировании. Например, модель принятия решений по ипотеке не должна использовать защищенные атрибуты расы, пола и возраста. Антиклассификация также известна как справедливость через неосведомленностьили справедливость через слепоту, поскольку модель не должна учитывать защищенные атрибуты. Часто считается, что как очень слабый или наивный критерий справедливости, поскольку он вообще не учитывает прокси (т. е. другие признаки, коррелирующие с защищенными атрибутами) — например, как обсуждалось выше, ипотечная модель может обучаться расово - предвзятые решения при использовании адреса заявителя.
Антиклассификация тривиально достигается путем удаления защищенных атрибутов из набора данных перед обучением. Защищенные атрибуты также можно удалить во время вывода, заменив их значения во всех входных данных константой. Будучи посторонним лицом, не имеющим доступа к обучающему коду или коду логического вывода, мы также можем провести внешний аудит модели, выполнив поиск доказательств того, что она использует защищенный атрибут при принятии решений: технически мы просто ищем нарушения инварианта надежности это говорит о том, что модель должна предсказывать один и тот же результат для двух входных данных, которые отличаются только защищенными атрибутами. Мы можем выразить это формально (см. также главу Качество модели): мы ожидаем, что предсказание модели f одинаково для всех возможных входных данных x независимо от того, является ли защищенный атрибут A элемента x имеет значение 0 или 1: ∀x. f(x[A ←0]) = f(x[A ←1]). Теперь мы можем использовать любую стратегию для поиска входных данных, нарушающих этот инвариант (от случайной выборки до поиска со стороны противника, см. главу Безопасность). Если мы находим один вход, который нарушает этот инвариант, мы знаем, что модель нарушает антиклассификацию; если мы хотим количественно оценить серьезность нарушения, мы можем сообщить, сколько таких входных данных мы можем найти (относительное или абсолютное).
На практике антиклассификация может стать хорошей отправной точкой для размышлений о том, какие функции следует использовать для процедуры принятия решений, а какие следует рассматривать как защищенные атрибуты, но, вероятно, это никогда не должно быть концом дискуссий о справедливости.
Групповая справедливость
Групповая справедливость — это общее название мер справедливости, позволяющих оценить, в какой степени группы, определенные защищенными атрибутами, достигают сходных результатов. Обычно это соответствует понятиям справедливости, связанным с справедливостью (равенство результатов) и критериями несопоставимого воздействия в законе, которые обсуждались выше. Этот показатель справедливости также известен как демографический паритет и соответствует статистическому свойству независимости.
Короче говоря, групповая справедливость требует, чтобы вероятность модели, предсказывающей положительный результат, была одинаковой для субпопуляций, отличающихся защищенными атрибутами. Например, банк должен принимать заявки на ипотеку по одинаковой ставке для чернокожих и белых заявителей. Формально групповая справедливость может быть описана как независимость прогнозируемого результата Y’ с защищенным атрибутом(ами) A: P[ Y’=1 | A=1 ] = P[ Y’=1 ∣ A=0 ] или Y’ ⊥ A. Обычно одинаковые вероятности (в пределах заданной погрешности) принимаются как справедливые; например, в дискурсе несоизмеримого воздействия в трудовом законодательстве США обычно используется правило четырех пятых, утверждающее, что коэффициент отбора для группы, находящейся в неблагоприятном положении, должен составлять не менее 80 % коэффициента отбора для другой группы (т. е. P [Y'=1 | A=1] / P[ Y'=1 ∣ A=0] ‹ 0,8).
Обратите внимание, что групповая справедливость фокусируется на результатах, а не на точности прогнозов. Например, нашу ипотечную модель можно считать справедливой в соответствии с групповой справедливостью, если она принимает 20% заявок с наименьшими рисками от белых заявителей, но просто случайным образом принимает 20% всех заявок от чернокожих заявителей. одинаково для обеих групп, но достоверность выдачи ипотечных кредитов в зависимости от риска значительно различается между группами. Если результаты, которые необходимо предсказать, коррелируют с защищенным атрибутом, например, члены одной группы на самом деле с большей вероятностью погасят кредит, поскольку они начинают с более высокого состояния и дохода, идеальный предсказатель со 100% точностью для всех групп будет не считать справедливым, так как это приведет к разным результатам в разных группах.
Чтобы проверить групповую справедливость модели, мы просто сравниваем уровень положительных результатов в подгруппах. Обычно это несложно, так как нам даже не нужно оценивать, были ли предсказания точными. Однако обратите внимание, что нам нужно либо использовать производственные данные, либо собрать репрезентативные тестовые данные для каждой подгруппы. Поскольку точность не требуется, мониторинг справедливости группы в производственных данных является простым и обычно целесообразным.
Уравненные шансы
Выравнивание шансов — это мера справедливости, позволяющая оценить, в какой степени модель достигает одинаковой точности при прогнозировании групп, определенных защищенными атрибутами, как с точки зрения доли ложноположительных, так и ложноотрицательных результатов. Это соответствует статистическому свойству разделения. Существует много вариантов этой меры, которые сравнивают различные меры точности между группами под такими названиями, как прогнозная четность и прогнозируемая равенство. Эти меры в целом соответствуют понятиям справедливости, связанным с равенством (равенство возможностей) и неравным обращением, которые обсуждались выше.
Интуитивно уравнивание шансов просто означает, что скорость, с которой модель делает ошибки, должна быть одинаковой для разных подгрупп. Например, при рассмотрении заявок на ипотеку мы хотим быть уверены, что выдаем кредиты всем группам населения с одинаковым уровнем риска, видимым в одинаковых показателях невозвратных ипотечных кредитов (т. , ложные срабатывания) во всех популяциях. Формально, предполагая предсказание Y' и правильный результат (наземную правду) Y и защищенный атрибут A, мы можем сформулировать равные шансы как P[ Y'=1 ∣ Y=0, A=1] = P[ Y'=1 ∣ Y= 0, A=0] и P[ Y'=0 ∣ Y=1, A=1] = P[ Y'=0 ∣ Y=1, A=0] или Y' ⊥ A | Ю.
Если один результат решения предпочтительнее другого (например, получение ипотечного кредита, поступление в колледж, прием на работу), мы можем гораздо больше беспокоиться о том, чтобы утаить положительный результат, чем об ошибочном предоставлении положительного результата. В этом контексте принято подчеркивать равенство только частоты ложноотрицательных результатов (P[Y'=0 ∣ Y=1, A=1] = P[Y'=0 ∣ Y=1, A=0]), но не ложноположительный показатель. Этот показатель часто называют равными возможностями. Тем не менее, другие показатели справедливости этого семейства сравнивают другие показатели точности по подгруппам, такие как точность, частота ложноотрицательных результатов и положительная прогностическая ценность.
Уравненные шансы и связанные с ними меры признают корреляцию защищенного атрибута с другими соответствующими характеристиками и позволяют принимать решения на основе защищенного атрибута в той мере, в какой это оправдано ожидаемым прогнозируемым результатом. Это считается справедливым, даже если оно приводит к несоизмеримым последствиям, когда есть различия в конечных результатах. Например, если заявки на ипотеку от заявителей с более низким благосостоянием и доходом на самом деле чаще не возвращаются, то ожидается, что заявки от демографических групп с более низким благосостоянием и доходом будут иметь более низкие показатели принятых заявок на ипотеку - разница в результатах составляет объясняется разницей в рисках между группами. И наоборот, равные шансы гарантируют, что мы не будем отдавать предпочтение одной группе, принимая более рискованные заявки на ипотеку от этой группы.
Как и для групповой справедливости, для оценки равных шансов и аналогичных мер справедливости для моделей требуется доступ к репрезентативным тестовым данным или производственным данным. В отличие от групповой справедливости, для этого также требуется знание того, какие прогнозы верны, для которых у нас часто есть метки в наборах данных, но которые может быть сложно установить в производственной среде. Особенно трудно точно измерить ложноотрицательные результаты в производственной системе (см. также главу Обеспечение качества в производстве).
Пример
Рассмотрим следующую матрицу ошибок для модели прогноза рака, разбитую на пациентов мужского и женского пола.

Для анти-классификации мы прогнали бы все данные пациентов (и, возможно, другие тестовые данные, включая случайные входные данные), просто перевернув отдельно предоставленный гендерный признак, связанный с входными данными, чтобы увидеть, чувствителен ли предиктор вообще к половому признаку. Мы не можем оценить антиклассификацию по матрице ошибок, но в этом легко убедиться, не предоставляя гендерную характеристику модели во время обучения или логического вывода.
Для групповой справедливости нас волнует не точность, а только то, как часто модель предсказывает определенный результат. Предполагая, что пациенты являются репрезентативными для соответствующих групп, мы обнаруживаем, что у пациентов мужского пола прогнозируется наличие рака в (23+11)/(23+11+41+925) = 3,4% всех случаев, тогда как у пациентов женского пола прогнозируется наличие рака. рак в (13+5)/(13+5+2+480) = 3,6% всех случаев. Эти показатели довольно схожи, что указывает на то, что модель в целом справедлива с точки зрения групповой справедливости.
Для уравновешенных шансов нам нужно сравнить как ложноположительный, так и ложноотрицательный коэффициент. Для пациентов мужского пола частота ложноположительных результатов составляет 11/(11+925) = 1,2%, а частота ложноотрицательных результатов составляет 41/(23+41) = 64%, для пациентов женского пола частота ложноположительных результатов составляет 5/(5+). 480) = 1,0% и частота ложноотрицательных результатов 2/(13+2) = 13%. В то время как частота ложноположительных результатов сопоставима, частота ложноотрицательных результатов значительно выше у пациентов мужского пола. Таким образом, модель не соответствует цели справедливости уравнивания шансов: она обеспечивает значительно лучшее обслуживание для пациентов женского пола, чем для мужчин.
Улучшение справедливости и инструментов справедливости
Во многих исследованиях изучались стратегии повышения справедливости моделей (в соответствии с различными мерами справедливости). Мы можем применять вмешательства на разных этапах конвейера машинного обучения.
Оценка и аудит моделей. Многие исследования справедливости в области машинного обучения изначально были сосредоточены на различных способах измерения справедливости в соответствии с разными представлениями о справедливости. На данный момент существует множество академических и промышленных наборов инструментов, которые позволяют легко измерять справедливость с помощью различных показателей и визуализировать результаты, такие как AI Fairness 360 от IBM, Fairlearn от Microsoft, Aequitas и Audit-AI. Большинство из них можно легко интегрировать в код науки о данных и в инфраструктуру непрерывной интеграции и отслеживания экспериментов (см. главы Основы обеспечения качества и Версии, происхождение и воспроизводимость), чтобы сообщать о мерах справедливости вместе с мерами точности каждый раз, когда модель обучается.
Термин аудит обычно используется для обозначения всесторонней оценки достоверности модели и предвзятости данных в определенный момент времени. В аудите часто используются те же данные оценки, что и в традиционных оценках точности (обычно отделенные от обучающих данных, см. главу Качество модели: измерение точности прогнозирования) для вычисления различных показателей справедливости, но аудит может также собирать новые данные или генерировать синтетические данные. . Аудит также может анализировать обучающие данные, в частности, для поиска функций, которые коррелируют с защищенными атрибутами. Помимо метрик и статистического анализа, аудиты могут также включать людей, исследующих систему или предвидящих проблемы с справедливостью; часто такие внешние аудиты проводятся путем набора потенциальных пользователей из разных слоев общества, которые могут исследовать систему на наличие проблем со своей точки зрения и опыта, например, на семинарах или на краудсорсинговых платформах.
Если возникает подозрение или свидетельство нежелательной систематической ошибки, можно использовать различные методы объяснимости для устранения источника систематической ошибки, например, путем определения важности функций, чтобы увидеть, опирается ли модель на защищенные атрибуты или функции, коррелирующие с ними. В главе Объяснимость и интерпретируемость дается обзор таких методов, а более целенаправленные методы были разработаны специально для отладки проблем справедливости, таких как Google What-If Tool.
Вывод модели. Во многих случаях существуют меры для повышения достоверности прогнозов модели, которые можно применить на этапе постобработки к обученной модели без необходимости обучения новой модели.
Чтобы гарантировать, что модель не использует защищенный атрибут, который является частью функций, предоставляемых во время вывода, мы можем просто заменить защищенный атрибут фиксированным или случайным значением, например, присвоить входным данным всех пол «неизвестно». запросы на вывод. Таким образом, мы можем тривиально добиться антиклассификации для модели, которая во время обучения имела доступ к защищенному атрибуту.
Для групповой справедливости и уравнивания шансов часто существует значительная гибкость для корректировки прогнозов путем настройки доверительных порогов отдельно для разных подгрупп. Обычно порог для модели выбирают намеренно, чтобы найти компромисс между точностью и полнотой или между частотой ложноположительных и ложноотрицательных результатов (см. главу Качество модели), но здесь мы выбираем разные пороги для различные группы следующим образом:
Чтобы добиться групповой справедливости, мы можем выбрать отдельные пороги для каждой группы, чтобы частота положительных прогнозов была сопоставимой. Например, мы принимаем только самые надежные заявки на ипотеку из одной группы, но также принимаем более рискованные заявки на кредит (с более низкой прогнозируемой достоверностью погашения) из другой группы. Корректировку пороговых значений можно рассматривать как форму позитивных действий, направленных на достижение справедливости в решениях, поскольку мы оказываем большую поддержку группам, которые в противном случае в среднем достигают более низких результатов. Технически, мы устанавливаем пороговые значения t0 и t1 для оценки предсказания R таким образом, что P[ R›t0 | A=1 ] = P[ R›t1 ∣ A=0 ].
Мы также можем выбрать разные пороги для достижения равных шансов. Ключевым моментом является определение пар пороговых значений, при которых частота ложноположительных и ложноотрицательных результатов совпадает. Технически также возможно преднамеренно ослабить предсказатель для одной группы, чтобы он соответствовал более низкой точности предсказания другой группы, например, чтобы намеренно случайным образом перевернуть определенное количество предсказаний для группы с преимуществом.

Обучение модели. Подходы к обучению модели могут быть оптимизированы для различных типов ошибок (или функций потерь). Несколько исследователей изучали, как включить меры справедливости в процесс оптимизации во время обучения. В некотором смысле это специализированный пример включения знаний предметной области в процесс обучения.
Многие алгоритмы машинного обучения также имеют механизмы для разного взвешивания разных строк обучающих данных, например, фокусируя обучение на тех, которые имеют менее известные смещения, не отбрасывая полностью более предвзятые.
Очистка данных, разработка признаков. Если мы стремимся к антиклассификации, мы можем просто удалить защищенные атрибуты из обучающих данных во время разработки признаков. На этом этапе мы также можем измерить корреляции, чтобы определить, какие функции являются прокси для защищенного атрибута, и рассмотреть возможность удаления этих прокси.
Помимо удаления защищенных атрибутов, мы часто можем попытаться частично исправить известные смещения в наших обучающих данных. Например, мы можем отбросить обучающие данные, которые, как мы знаем, предвзяты из-за исторической предвзятости, испорченных примеров или искаженных выборок. Мы можем попытаться определить, какие обучающие данные были получены в рамках предыдущего прогноза (петля обратной связи), и рассмотреть возможность их удаления. Мы можем попытаться обнаружить ограниченные функции, определяя функции, которые являются прогнозирующими только для некоторых субпопуляций, и удаляя их для субпопуляций, где они дают менее точную информацию. Если столкнуться с несоответствием размера выборки, стратегии увеличения данных могут обеспечить частичное улучшение, чтобы получить больше обучающих данных для менее представленных групп.
Многие современные подходы сосредоточены, в частности, на отладке данных: начиная с несправедливого прогноза, они используют методы объяснимости (см. главу Объяснимость и интерпретируемость) для выявления причин несправедливости. Такие методы могут выявить систематические ошибки в данных, такие как испорченные метки или искаженные выборки, или экземпляры обучающих данных, которые оказывают чрезмерное влияние на прогнозы. С таким пониманием мы можем затем очистить или изменить обучающие данные (например, удалить выбросы, удалить предвзятые выборки) или собрать дополнительные данные.
Наконец, можно нормализовать обучающие данные таким образом, чтобы обученные модели были более справедливыми, обычно путем масштабирования функций для выборок обучающих данных из разных подгрупп по отдельности.
Сбор данных. Зачастую самый действенный способ добиться справедливости — это самый первый этап конвейера машинного обучения во время сбора данных. Различие в точности модели для разных подгрупп (нарушения уравненных шансов и аналогичных мер) часто вызвано различиями в количестве и качестве обучающих данных для этих подгрупп. Уточнение процедуры сбора данных и сбор дополнительных данных часто может помочь улучшить модели для определенных подгрупп. В частности, несоответствие размера выборки может быть устранено путем сбора дополнительных данных. Если нам известно об искаженных выборках или ограниченных функциях, мы можем пересмотреть наши протоколы выборки и сбора данных; если мы знаем об испорченных примерах, мы можем больше инвестировать в обеспечение того, чтобы маркировка данных была менее предвзятой.
Справедливость — это проблема всей системы
Почти все сложные проблемы честности систем с компонентами машинного обучения являются общесистемными проблемами, которые нельзя решить только на уровне модели. Основные проблемы включают в себя (1) проблемы разработки требований, связанные с выявлением проблем справедливости, выбором защищенных атрибутов, разработкой протоколов сбора данных и маркировки и выбором показателей справедливости, (2) взаимодействие человека с компьютером. проблемы разработки того, как представлять результаты пользователям, объективно собирать данные от пользователей и разрабатывать меры по смягчению последствий, (3) проблемы обеспечения качества оценки того, насколько справедлива вся система и как это может быть гарантировано постоянно в производстве, (4) проблемы интеграции процессов для обеспечения справедливости на протяжении всего процесса разработки, от требований до проектирования и реализации, оценки и эксплуатации, а также (5) обучение проблемы документирования того, как повысить осведомленность о проблемах справедливости и документировать соображения и результаты справедливости, особенно между командами с разным опытом и приоритетами.
Выявление и согласование требований справедливости
Хотя измерение и улучшение показателей справедливости на уровне модели интересно и хорошо поддерживается инструментами, может быть очень сложно определить, какое понятие справедливости в первую очередь актуально и какие функции следует рассматривать как защищенные атрибуты. Различные критерии справедливости являются взаимоисключающими, и разные заинтересованные стороны могут иметь очень разные предпочтения. Определение того, какое понятие справедливости следует использовать в системе, является сложной задачей разработки требований, которая может быть сопряжена с политикой.
Разработка требований для справедливости обычно начинается с нескольких довольно простых вопросов, многие из которых уже рассматриваются как часть обычного процесса разработки требований:
- Какова цель системы? Какие преимущества это дает и кому?
- Какие подгруппы населения (включая группы меньшинств) могут использовать систему или быть затронуты ею? Какие типы вреда может причинить система с (противоправной) дискриминацией?
- Кто является заинтересованными сторонами системы? Каковы взгляды или ожидания заинтересованных сторон в отношении справедливости и в чем они противоречат друг другу? Пытаемся ли мы добиться справедливости, основанной на равенстве или равноправии?
- Подрывает ли справедливость какие-либо другие цели системы (например, точность, прибыль, время выпуска)?
- Как собирались обучающие данные и какие предубеждения могли быть закодированы в процессе сбора или данных? Какие возможности у нас есть для формирования сбора данных?
- Существуют ли законодательные антидискриминационные требования, которые следует учитывать? Есть ли у общества этические ожидания, связанные с этим продуктом? Какова активистская позиция?
Анализ потенциального вреда. Программная автоматизация часто продвигается, чтобы заменить предвзятое и медленное принятие решений человеком более объективными автоматизированными решениями, свободными от предвзятости, как и в примере с ипотекой. Тем не менее, люди, разрабатывающие систему, по-прежнему могут создавать предвзятые процедуры принятия решений, а с машинным обучением люди влияют на данные, на которых обучаются модели системы, и люди решают, какие данные собирать и как. Автоматизация решений может быть еще более вредной, потому что решения теперь могут применяться в значительных масштабах (потенциально нанося вред большему количеству людей), и их еще труднее обжаловать, поскольку они принимаются, казалось бы, объективными программными системами.
Во-первых, мы должны понять, как несправедливые решения модели с машинным обучением могут причинить вред, включая возможный вред распределения и вред представления. С этой целью важно понимать, как модель внутри системы влияет на результаты работы системы, независимо от того, показывает ли система только прогнозы модели (например, стереотипы при выборе рекламы) или действует на основе прогнозов (например, отклонение заявки на ипотеку из-за предвзятости). оценка риска).
Даже у команд с благими намерениями, даже у специально выделенных центральных команд по обеспечению справедливости есть слепые зоны, и они могут быть удивлены проблемами справедливости, затрагивающими население, которые они не рассматривали. Маловероятно, что даже разные команды привнесут свой жизненный опыт и нюансы культурных знаний и знаний в предметной области, чтобы предвидеть все проблемы справедливости в продукте, развернутом по всему миру. Чтобы выявить возможный вред, взаимодействие с заинтересованными сторонами может открыть глаза. Простые методы, такие как простое описание проблемы и предполагаемого решения для потенциальных пользователей, демонстрация макетов пользовательских интерфейсов или предоставление интерактивных прототипов (возможно, с использованием дизайна Волшебник страны Оз, когда человек моделирует модель для быть развитым) может выявить различные взгляды и возможные опасения. Если доступ к заинтересованным сторонам ограничен или участники не представляют ожидаемый разнообразный опыт, персоны могут быть эффективными для выявления проблем групп населения, которые могут быть недостаточно представлены в команде разработчиков: идея состоит в том, чтобы опишите репрезентативного вымышленного пользователя из определенной целевой демографической группы, а затем спросите, учитывая конкретную задачу с продуктом, который необходимо разработать: Что бы этот человек сделал или подумал? Все эти методы широко описаны в учебниках по разработке требований и дизайну.
Идентификация защищенных атрибутов. После того, как мы предвидим потенциальный вред от дискриминации, нам необходимо определить, по каким атрибутам мы можем дискриминировать в системе и какие атрибуты следует рассматривать как защищенные атрибуты при обсуждении справедливости. Это требует понимания нашей целевой группы населения и ее подгрупп, а также того, как на них может повлиять дискриминация.
Закон о борьбе с дискриминацией обеспечивает отправную точку (см. выше), перечисляя атрибуты, которые могут привести к юридическим проблемам у разработчиков системы, если будет доказана дискриминация. Однако есть и другие критерии, которые могут рассматриваться как проблематичные для некоторых задач, даже если они не требуются по закону, например, социально-экономический статус при принятии решений о приеме в колледж, рост или вес в системах обнаружения пешеходов, прическа или цвет глаз в системах проверки заявлений. или предпочтения конкретных спортивных команд при принятии решений по ипотечному кредитованию. Защищенные атрибуты, как правило, относятся к характеристикам людей, но концептуально мы можем также распространить обсуждение защищенных атрибутов на животных (например, системы автоматизации на фермах) и неодушевленные объекты (например, обнаружение цветов на фотографиях).
Инженеры-программисты и специалисты по данным могут не всегда быть осведомлены о требованиях законодательства и общественных дискуссиях о справедливости и дискриминации. Как обычно в разработке требований, обычно стоит поговорить с широким кругом заинтересованных сторон, проконсультироваться с юристами, ознакомиться с соответствующими исследованиями и привлечь экспертов, чтобы определить, какие защищенные атрибуты следует учитывать для обеспечения справедливости.
Устранение конфликтующих критериев справедливости. Различные критерии справедливости, описанные выше, в большинстве случаев являются взаимоисключающими. Например, ипотечная модель, которая является справедливой в соответствии с равными шансами, не будет удовлетворять групповой справедливости, если между группами существуют различия. Конфликт, однако, не должен вызывать удивления, учитывая, как эти меры соответствуют очень разным представлениям о том, что считается справедливым, если группы исходят из разных позиций (будь то инертность или дискриминация в прошлом). Каждое понятие справедливости можно считать несправедливым, если рассматривать его через призму справедливости других: одинаковое отношение ко всем в рамках меритократии только усилит существующее неравенство, в то время как улучшение неблагополучных сообществ можно рассматривать как предоставление несправедливых преимуществ людям, которые внесли меньший вклад, что затрудняет достижение успеха в жизни. привилегированная группа только из-за группового статуса.
Разные заинтересованные стороны могут отдавать предпочтение разным понятиям справедливости, что существенно противоречит друг другу. Например, в исследовании пользователей в крупной технологической компании, о котором сообщили Holstein et al., пользователи поисковых систем считают, что попытки разработчика повысить объективность поиска изображений (например, увеличение представленности в поиске генеральный директор, как обсуждалось выше) представляет собой неэтичную манипуляцию результатами поиска: Пользователи прямо сейчас видят [поиск изображений] как «Мы показываем вам [объективное] окно в […] общество, тогда как у нас есть сильный аргумент [ вместо этого] для Мы должны показать вам как можно больше различных типов изображений, [чтобы] попытаться найти что-то для всех.
Конфликты между различными критериями справедливости трудно разрешить, и решение о критериях справедливости по своей сути является политическим, взвешивая предпочтения различных заинтересованных сторон. Цели справедливости могут балансировать между несколькими критериями и могут явно допускать некоторую степень несправедливости.
Меры справедливости, основанные на справедливости, часто предлагаются активистами, которые хотят изменить статус-кво с помощью технических средств. В некоторых случаях закон может дать некоторые рекомендации, например:
- В делах о дискриминации при приеме на работу суды часто используют понятие групповой справедливости с правилом четырех пятых для определения возможной дискриминации, проверяя, различаются ли коэффициенты найма среди подгрупп, определяемых (юридически) защищенными признаками, более чем на 20%. . Затем компании могут попытаться обосновать, почему эти различия вызваны деловой необходимостью или связаны с работой.
- Юридические требования к решениям о приеме в колледж в США интерпретируются некоторыми юристами как следующие подходу справедливости, соответствующему антиклассификации: использование защищенных атрибутов, включая расу, национальное происхождение, религию, пол, возраст и инвалидность незаконна, но использование «расово-нейтральных» критериев, таких как социально-экономический статус, первое поколение, поступившее в колледж, предшествующее посещение исторически сложившихся колледжей или университетов для чернокожих (HBCU) и область обучения, как правило, считается законным, даже если они сильно коррелирует с защищенными атрибутами. Кроме того, закон предусматривает конкретные узкие исключения из тех случаев, когда разрешено возвышение некоторых групп, включая возможность использовать расовую принадлежность при целостном рассмотрении заявок в пользу заявителей из недостаточно представленных групп (позитивные действия) и возможность в целом отдавать предпочтение ветеранам, а не не ветеранам. .
Существует также несколько попыток предоставить руководства, помогающие решить, какой показатель справедливости подходит в данной ситуации, например, дерево справедливости Aequita или блок-схема К какому типу статистической справедливости вам следует стремиться? от Aspen Technology Hub. . В этих руководствах задаются вопросы о том, следует ли стремиться к равенству результатов (например, групповая справедливость) или ошибок (например, равные шансы) и какие ошибки более проблематичны, чтобы рекомендовать подходящую метрику справедливости.

Известный общественный спор по поводу инструмента оценки риска рецидивизма для вынесения приговора в США был сосредоточен вокруг того, какой показатель справедливости выбрать из семейства показателей, сравнивающих точность между группами: было ясно, что антиклассификация и групповая справедливость не подходят, но эту справедливость следует оценивать с точки зрения одинаково точного прогнозирования риска рецидивизма среди подгрупп населения. В широко обсуждаемой статье ProPublica Machine Bias утверждалось, что коммерческий инструмент для оценки рисков, основанный на ML, COMPAS нарушает принцип уравнивания шансов (т. Производитель Northpointe ответил, что их инструмент справедлив в том смысле, что он имеет одинаковые коэффициенты ложных открытий (или точность) и что эта мера больше подходит для карательных решений (Если модель помечает вас как человека с высокой степенью это зависит от вашей расы?).
Учитывая, что одна и та же модель может считаться справедливой и несправедливой в зависимости от выбранной метрики справедливости, важно очень тщательно подходить к выбору. Поскольку такое решение по своей сути политическое, и, вероятно, ни одно решение не сделает всех заинтересованных сторон одинаково счастливыми, важно предоставить обоснование решения.
Справедливость, точность и прибыль. Добросовестность часто противоречит точности и системным целям, таким как прибыль или пользовательский опыт. Многие подходы к повышению справедливости модели в соответствии с некоторым показателем справедливости снижают общую точность модели либо потому, что они ограничивают доступ к прогностическим функциям (антиклассификация), либо потому, что они обеспечивают равные результаты для групп, где несбалансированные результаты были бы более точными (групповая справедливость). , либо потому, что он ограничивает выбор порогов достоверности или искусственно снижает точность классификатора для одной группы (выравнивание шансов). Более низкая точность часто сопровождается более низким качеством обслуживания пользователей (в среднем) или более низкой прибылью владельца системы. Мы настоятельно рекомендуем изучить превосходную интерактивную визуализацию Ваттенберга, Вьегаса и Хардта о том, как различные пороговые значения в сценарии кредитной заявки значительно влияют на прибыль при различных настройках справедливости.
Однако, возможно, справедливость не всегда противоречит точности и прибыли, и понимание правильного построения может помочь убедить инженеров и руководство обратить внимание на справедливость. С одной стороны, более честные продукты могут привлечь большую клиентскую базу, увеличивая общую прибыль, даже если точность отдельных решений может быть ниже. И наоборот, недобросовестные продукты могут получить настолько плохое освещение в СМИ, что даже очень точные прогнозы не смогут убедить пользователей использовать продукт. С другой стороны, действия, которые повышают точность для одной группы, чтобы улучшить показатели справедливости, подобные уравнению шансов, такие как сбор большего количества или более качественных обучающих данных или разработка лучших функций, могут оказать положительное влияние на точность всей системы. В этом смысле несправедливость может быть показателем того, что для улучшения модели требуется дополнительная работа, что хорошо согласуется с более детальной оценкой моделей с использованием срезов, как описано в главе Качество модели.
Опять же, мы видим неотъемлемые компромиссы и необходимость согласования противоречивых целей, исходящих от разных заинтересованных сторон. Владельцы продукта обычно имеют право расставлять приоритеты в своих целях, и без регулирования или значительного давления со стороны клиентов или освещения в СМИ разработчикам может быть трудно убедить руководство сосредоточиться на справедливости, когда повышение справедливости снижает прибыльность продукта. Однако активисты и конечные пользователи также могут влиять на такие решения, а инженеры по требованиям могут привести веские доводы в пользу того или иного проекта. В идеале такие конфликты выявляются на ранней стадии разработки требований, и команда принимает и документирует обдуманные решения о том, как найти компромисс между различными качествами на системном уровне. Требования честности существенно не отличаются от других требований — нам всегда нужно находить противоречивые цели и компромиссы (см. главы Разработка требований и Атрибуты качества компонентов ML), но требования справедливости имеют тенденцию привлекать больше внимания общественности.
Справедливость за пределами прогнозов модели
В обсуждениях справедливости мы в основном сосредотачиваемся на справедливости (автоматизированной) процедуры принятия решений модели с машинным обучением, но всегда важно понимать, как такие решения встроены в программную систему и как эта система используется в среде.
Устранение предвзятости за счет дизайна системы. Узкий фокус на модели может упустить возможности повысить справедливость за счет перепроектирования системы на основе модели, переформулирования целей системы или устранения предвзятости с помощью мер безопасности, не входящих в модель. Есть несколько реальных примеров того, как вмешательства, выходящие за рамки модели, помогли избежать проблем со справедливостью, обойдя или смягчив проблему с помощью решений в более крупной системе:
- Избегать ненужных различий. Если различие между двумя классами связано с мошенничеством по предубеждению или ошибки могут быть дискриминационными, подумайте, действительно ли это различие необходимо или можно создать более общий класс для их объединения (это согласуется с понятие справедливости для устранения неравных исходных позиций, о которых говорилось выше). Например, в приложении для добавления подписей к фотографиям, где различие между врачами и медсестрами не имело особого значения, система избегала проблем с гендерной предвзятостью, приняв нейтральную объединяющую терминологию «медицинский работник».
- Подавление потенциально проблемных выходных данных. Если определенные прогнозы склонны вызывать дискриминационные выходные данные, подумайте, допустимо ли полное подавление этих выходных данных. Например, система обмена фотографиями с моделью обнаружения объектов, которая в редких случаях оскорбительно ошибочно классифицировала людей как обезьян, имеет жестко закодированную логику, запрещающую показывать какие-либо результаты, относящиеся к обезьянам; это решение ухудшило качество системы для некоторых вариантов использования фотографии животных, но позволило избежать дискриминационных результатов в основном случае использования — обмена фотографиями друзей и семей.
- Разработайте безотказные стратегии. Разработайте систему таким образом, чтобы вред даже в наихудшем дискриминационном прогнозе был сведен к минимуму. Например, система, обнаруживающая игры в онлайн-обучении, предпочла отображать негативные эмоции и предлагать дополнительные упражнения, а не прямо выявлять мошенничество, чтобы уменьшить негативные последствия в случаях, когда детектор неправильно классифицировал экземпляр; даже если предиктор был смещен, вред от такого смещения уменьшается.
- Держите людей в курсе. Избегайте полной автоматизации, но привлекайте людей для исправления ошибок и предубеждений. Например, коммерческие сервисы для создания телевизионных субтитров часто заставляют людей редактировать расшифровки, автоматически созданные моделями машинного обучения, исправляя ошибки и исправляя предубеждения, которые могут привести к созданию автоматических расшифровок более низкого качества для определенных диалектов.
Взаимодействие машинных решений и решений человека. Модели с машинным обучением часто заменяют человеческое суждение с целью его масштабирования или повышения справедливости, исключая индивидуальные человеческие предубеждения из процесса принятия решений. Но как люди будут взаимодействовать с автоматическими решениями, справедливыми они или нет? Например, предпринимает ли система автоматические действия на основе решения или человек остается в курсе событий? Если человек участвует в процессе (будь то при принятии первоначального решения или в рамках процесса апелляции), есть ли у него достаточно информации и времени, чтобы должным образом рассмотреть предложение системы? Будет ли у человека возможность скорректировать предвзятость в процедуре принятия решения или, наоборот, сможет ли человек отвергнуть справедливое решение своими собственными предубеждениями?
Lally обсуждает интересный пример этого конфликта для алгоритмов прогнозирования полицейских: отдельные полицейские, за которыми наблюдают, склонны использовать модельные прогнозы в качестве предлога для расследований, если они совпадают со своими личными предубеждениями, и игнорируют их в противном случае; следовательно, модель используется для выборочного оправдания человеческого предубеждения, независимо от того, является ли сама модель справедливой или нет. Поскольку развертывание прогностической полицейской системы может свидетельствовать об объективности (особенно если модель была проверена на справедливость), даже если это не меняет никаких результатов, развертывание такой системы может затруднить проверку существующих человеческих предубеждений и, следовательно, нанести больше вреда в целом.
Понимание более широкого контекста системы и того, как различные заинтересованные стороны взаимодействуют с ней или как она влияет на нее, имеет первостепенное значение при построении справедливых систем. С этой целью важна разработка строгих требований и проектирование, ориентированное на человека.
Более честный сбор данных. Многие модели принимают дискриминационные решения из-за предвзятости обучающих данных, которая появляется в процессе сбора данных. Понимание предвзятости в источнике сбора данных часто намного эффективнее, чем исправление несправедливых результатов позже в модели путем корректировки порогов. В то время как студенты, изучающие науку о данных, часто получают фиксированные наборы данных и мало влияют на сбор данных, специалисты-практики в проектах по науке о данных часто могут влиять на процесс сбора данных — например, Holstein et al. сообщает, что 65% опрошенных специалистов, работающих над справедливостью в системах с поддержкой ML, в той или иной степени контролируют сбор и обработку данных.
Проводя тщательный анализ существующих процессов и разработку требований для новых, разработчики систем должны учитывать, как собираются обучающие данные и какие могут возникнуть ошибки — это требует явного внимания к интерфейсу между системой и ее окружением и тому, как система воспринимает информацию о его окружение (см. главы «Мир и машина» и «Качество данных»). Важно помнить, что не существует такого понятия, как «необработанные и объективные данные», и что весь сбор данных определяется решениями о том, какие данные собирать и как (например, как отбираться, какие функции, какая степень детализации, какая частота) . Приведенный выше список источников систематической ошибки, включая нечеткие этикетки, искаженные выборки и различия в размерах выборки, можно использовать в качестве контрольного списка для проверки решений по сбору данных. Могут быть значительные возможности для разработки более совершенных методов сбора данных для достижения более высокого качества данных, а также для сбора данных, которые лучше отражают все целевые демографические данные.
Петли обратной связи. Петли отрицательной обратной связи часто способствуют усилению существующих предубеждений, таких как автоматические решения о выдаче кредита, усиливающие существующее неравенство в уровне благосостояния, и предсказывающие алгоритмы полицейских действий, которые еще больше направляют полицию в уже и без того чрезмерно охраняемые сообщества.
В идеале мы ожидаем циклов отрицательной обратной связи во время разработки требований или проектирования системы. Как обсуждалось в главе «Мир и машина», мы можем предвидеть множество петель обратной связи, анализируя, как система воспринимает мир (понимая, какие предположения мы делаем) и как система влияет на мир, а также взаимодействуют ли эти два процесса через механизмы в окружающей среде. Например, наша ипотечная система может регулярно переобучаться на прошлых данных об ипотечных кредитах и просроченных кредитах, где на некоторые данные могли повлиять прошлые решения наших моделей — ясно, что решения системы влияют на реальный мир способами, которые могут повлиять обучающие данные.
Возможно, мы не сможем предвидеть все петли обратной связи, но мы все же можем предвидеть, что петли обратной связи могут существовать, и инвестировать в мониторинг, как мы обсудим ниже, чтобы мы замечали петли обратной связи, когда они проявляются.
Как только мы предвидим или наблюдаем петли обратной связи, мы можем (пере)конструировать систему, чтобы разорвать петлю обратной связи. Конкретная стратегия будет зависеть от системы, но может включать (1) изменение методов сбора данных, чтобы избежать сбора сигналов, чувствительных к петлям обратной связи, (2) явную компенсацию смещения на уровне модели или системы и (3) прекращение построения и развернуть систему в первую очередь.
Последствия для общества. Автоматизация масштабных решений может изменить динамику власти в масштабах общества. Существует множество дискуссий о том, что это может быть источником добра, но также и путем к антиутопии. Часто возникает ключевой вопрос: кому выгодна автоматизация на основе машинного обучения? И кто несет расходы? Мы не сможем начать здесь всестороннюю дискуссию, но приведем три примера.
Продукты с поддержкой машинного обучения могут сделать способности доступными для широких слоев населения, которые ранее требовали существенного обучения, тем самым улучшая доступ и снижая затраты. Например, автоматизация медицинской диагностики может сделать доступной помощь при редких состояниях за пределами населенных пунктов с участием узкоспециализированных врачей; автоматизированные навигационные системы позволяют даже неопытным водителям оказывать транспортные услуги, не полагаясь на опытных, обученных таксистов. В то же время продукты с поддержкой ML могут вытеснить квалифицированных работников, которые ранее выполняли эти задачи, таких как врачи и таксисты. Как правило, такие автоматизированные продукты могут обеспечить невероятный прогресс и экономию средств, но также могут привести к сокращению рабочих мест. Экстраполируя, это приводит к серьезным фундаментальным вопросам о том, кому принадлежат продукты с поддержкой машинного обучения, и как построить общество, в котором традиционное понятие работы может больше не быть центральным, поскольку многие рабочие места автоматизированы.
Продукты с поддержкой машинного обучения, как правило, в значительной степени зависят от данных, и способ сбора и маркировки таких данных может быть эксплуататорским. Наборы данных часто собираются из онлайн-ресурсов без компенсации создателям, а маркировка часто осуществляется краудсорсингом, за утомительные задачи выплачивается нищенская заработная плата. В условиях ограниченных ресурсов, таких как больницы и прогнозирование браконьерства на диких животных, как сообщает Самбасиван и Вирарагхаван, ручной ввод данных часто поручается полевым работникам в дополнение к их существующим задачам; в то же время эти полевые работники не получают выгоды от системы, не ценятся создателями автоматизированной системы и часто манипулируются с помощью механизмов наблюдения и геймификации.
Проблемы справедливости в продуктах с поддержкой ML часто поднимаются затронутыми сообществами. В организациях, разрабатывающих продукты, работе по обеспечению справедливости часто не уделяется приоритетное внимание, и ее часто выполняют внутренние активисты при незначительной институциональной поддержке. Это может привести к тому, что стоимость борьбы за справедливость в системах с поддержкой ML в первую очередь придется на группы населения, которые уже маргинализированы и находятся в неблагоприятном положении.
Разработчикам легко обосновать, что каждый отдельный продукт мало влияет на большие социальные тенденции. Может быть трудно отклониться от текущей отраслевой практики и оправдать вложение ресурсов в создание более честных продуктов, учитывая отсутствие юридических требований, более высокую стоимость разработки, более медленное время выхода на рынок, меньше технических возможностей или даже отсутствие выпуска продукта вообще. Однако ответственные инженеры должны учитывать, как их продукты вписываются в более масштабные социальные проблемы, и учитывать, как их продукты могут способствовать улучшению мира.
Интеграция процессов
Несмотря на множество академических и общественных дискуссий о справедливости в машинном обучении, справедливость, как правило, получает мало внимания в большинстве конкретных программных проектов с компонентами машинного обучения. Исследование за исследованием показывают, что большинство команд недостаточно активно учитывают справедливость в своих проектах. В интервью специалисты-практики часто признают потенциальные опасения по поводу справедливости, когда их спрашивают, но также признают, что они ничего не сделали для этого — самое большее, они в основном говорят о справедливости в желаемых терминах для будущих этапов своих проектов. Если вообще проводится какая-то конкретная работа по обеспечению справедливости, то ее продвигают в первую очередь отдельные заинтересованные члены команды, выступающие в качестве внутренних активистов в организациях, но почти всегда без институциональной поддержки. В некоторых крупных организациях (особенно в компаниях BigTech) есть центральные группы по ответственному машинному обучению, но они часто ориентированы на исследования и редко имеют возможность оказывать широкое влияние на команды разработчиков.
Препятствия. Специалисты-практики, которые заинтересованы в справедливости и хотят внести свой вклад в справедливость своих продуктов, как правило, сообщают о множестве организационных барьеров (подробности см. в Holstein et al. и Rakova et al.).
Во-первых, работа по обеспечению справедливости редко является приоритетом в организациях и почти всегда носит реактивный характер. Большинство организаций не работают над справедливостью до тех пор, пока не возникнет внешнее давление со стороны СМИ и регулирующих органов или внутреннее давление со стороны активистов, подчеркивающих проблемы со справедливостью. Ресурсы для проактивной работы ограничены, а работа по обеспечению справедливости почти никогда официально не требуется, из-за чего она часто кажется малоприоритетной и ее легко игнорировать. Даже если справедливость сообщается в качестве приоритета в ответственной инициативе ИИ, часто отсутствует ответственность за работу по обеспечению справедливости, а при неясных обязанностях работу по обеспечению справедливости можно легко пропустить.
Во-вторых, особенно за пределами организаций BigTech, работа по обеспечению справедливости часто рассматривается как двусмысленная и слишком сложная для текущего уровня ресурсов организации. Показатели академической справедливости иногда считают слишком далекими от реальных проблем конкретных продуктов. И наоборот, область исследований справедливости продолжает быстро развиваться, и проблемы справедливости, которые привлекают внимание средств массовой информации и общественных активистов, продолжают меняться, что затрудняет отслеживание.
В-третьих, значительная часть работы по обеспечению справедливости добровольно выполняется людьми вне их официальных должностных обязанностей. Справедливая работа редко вознаграждается организационными структурами при оценке результатов работы сотрудников при продвижении по службе, а активисты могут восприниматься как нарушители спокойствия. Люди, работающие над справедливостью, обычно полагаются на свои личные сети для распространения информации, а не на организационные структуры.
В-четвертых, успех работы по обеспечению справедливости бывает трудно измерить количественно (например, улучшение продаж или предотвращение катастроф в области связей с общественностью), что затрудняет обоснование организационных инвестиций в обеспечение справедливости. Кроме того, справедливость редко активно измеряется и контролируется с течением времени. Справедливость редко считается ключевым показателем эффективности продукта. Организации часто сосредотачиваются на краткосрочных целях развития и показателях успеха продукта, тогда как многие проблемы справедливости связаны с долгосрочными результатами, такими как циклы обратной связи и предотвращение редких аварий.
В-пятых, технические проблемы мешают тем, кто занимается повышением справедливости. В частности, политики конфиденциальности данных, которые ограничивают доступ к необработанным данным и защищенным атрибутам, могут затруднить диагностику проблем справедливости. Работа по обеспечению справедливости может быть замедлена бюрократией. Кроме того, понимание того, соответствуют ли жалобы пользователей на справедливость просто нормальной частоте неправильных прогнозов или систематическим искажениям, закодированным в модели, является сложной задачей отладки.
Наконец, вопросы справедливости, как правило, сильно зависят от проекта, что затрудняет повторное использование конкретных идей и инструментов в разных командах на очень действенных шагах.
Улучшение интеграции процессов. Чтобы выйти за рамки текущего реактивного подхода, организациям было бы полезно внедрить упреждающие методы как часть процесса разработки во всей организации, как на уровне модели, так и на уровне системы. Переход от отдельных лиц, стремящихся к справедливости, к практике, встроенной в организационные процессы, может распределить работу по многим плечам и может привлечь всю организацию к ответственности за серьезное отношение к справедливости.
Чтобы обеспечить справедливость работы, организации могут сделать ее частью этапов и результатов и назначить конкретные обязанности отдельным членам команды для их выполнения. Это может включать в себя различные шаги, такие как (1) обязательное обсуждение рисков дискриминации, защищенных атрибутов и целей справедливости в документах с требованиями, (2) требуемое сообщение о справедливости в (автоматизированных) отчетах о тестировании, (3) обязательные внутренние или внешние проверки справедливости до релизы и (4) необходимая инфраструктура мониторинга и контроля справедливости для обеспечения достижения согласованных целей уровня обслуживания для обеспечения справедливости в производстве (см. главу Планирование операций). Долгосрочные показатели справедливости (вне модели) могут быть установлены в качестве ключевых показателей эффективности наряду с другими показателями успеха проекта. Если работа по обеспечению справедливости осязаема и является частью ожидаемых рабочих обязанностей, лица, работающие над обеспечением справедливости, также могут получить признание за свою работу, например, указывая на конкретный вклад и улучшение конкретных показателей в рамках оценки эффективности сотрудников. Как обычно, с процессными требованиями разработчики могут начать сопротивляться и жаловаться на бюрократию, если работа становится слишком обременительной или оторванной от их непосредственных рабочих приоритетов (см. обсуждение в главе Процесс), что можно частично смягчить, мотивируя важность справедливости. работа, облегчение работы по обеспечению справедливости и привлечение экспертов.
Чтобы изменения в процессах были эффективными, решающее значение имеет участие руководства организации. Организация должна показать, что она серьезно относится к справедливости, не только с помощью высоких заявлений о миссии, но и путем предоставления выделенных ресурсов и серьезного рассмотрения справедливости среди других качеств, когда речь идет о трудных компромиссных решениях, что демонстрируется готовностью в худшем случае прервать проект. весь проект по этическим соображениям. Ракова и др. резюмируют стремления как
«Они предполагали, что руководство организации будет понимать, поддерживать и активно заниматься ответственными проблемами ИИ, которые будут учитываться в контексте их организации. Ответственный ИИ будет расставлен по приоритетам как часть организационной миссии высокого уровня, а затем преобразован в действенные цели на отдельных уровнях посредством установленных процессов. Респонденты хотели, чтобы информация распространялась по хорошо зарекомендовавшим себя каналам, чтобы люди знали, где искать и как делиться информацией».
Преодолеть организационную инерцию, чтобы добраться до такого места, может быть невероятно сложно, как могут подтвердить многие разочарованные сторонники справедливости ML в различных организациях. Пути, которые были отмечены как успешные в некоторых организациях, включают (1) представление инвестиций в работу по обеспечению справедливости как финансово выгодное решение, позволяющее избежать последующих доработок и репутационных издержек, (2) демонстрацию конкретных, количественных доказательств выгод от работы по обеспечению справедливости, (3) непрерывное внутренняя активность и образовательные инициативы, а также (4) внешнее давление со стороны клиентов и регулирующих органов.
Даже когда организации не хотят проявлять инициативу, столкновение с конкретной проблемой справедливости и негативной реакцией общественности может стать для организации обучающим моментом. Прошлый опыт, особенно если он был разрушительным и дорогостоящим, может быть использован в качестве аргумента в пользу более активной работы по обеспечению справедливости в будущем. Хорошей отправной точкой является проведение внутреннего расследования или привлечение консультантов для выявления «слепых зон» и предотвращения подобных проблем в будущем. Внутреннее расследование каждого инцидента также является хорошей организационной политикой, даже для зрелых команд, чтобы улучшать свои методы каждый раз, когда проблема ускользает.
Распределение обязанностей в командах. В настоящее время работа по обеспечению справедливости часто продвигается изолированными людьми внутри команд, которые пытаются убедить других членов команды и организацию в целом обратить внимание на справедливость.
Справедливость — это сложная и сложная тема, и во многих командах может просто не быть членов, обладающих необходимыми навыками для проведения или даже пропаганды честной работы. Хотя вопросы справедливости и этики имеют долгую историю, они лишь недавно получили широкое признание в сообществе машинного обучения и до сих пор отсутствуют во многих учебных программах по машинному обучению. При решении конкретных технических задач забота о справедливости может показаться отвлекающим маневром со стороны активистов, не имеющим большого практического значения; практикующие могут даже обидеться на эту тему и относиться к ней просто как к еще одной ячейке для проверки среди перегруженной бюрократии. Вместо того, чтобы каждый стал экспертом в области справедливости, мы снова придерживаемся концепции T-образных профессионалов, которые достаточно осведомлены о справедливости, чтобы оценить опасения по теме и знать, когда и как обратиться за помощью.
Как обсуждалось в главе Междисциплинарные команды, важно подумать о том, как распределять специалистов внутри и между командами. Как обсуждалось там, для безопасности часто лучше предоставить базовое образование по теме, чтобы повысить осведомленность всех членов команды, но делегировать специфику экспертам, а не ожидать, что каждый станет экспертом по каждой теме. Та же стратегия кажется приемлемой и для работы по обеспечению справедливости: убедитесь, что все члены команды осведомлены (например, с помощью коротких тренингов во время адаптации) о возможном вреде, источниках предвзятости и типичных проблемах справедливости, но привлекайте специалистов или полностью делегируйте работу по обеспечению справедливости, когда это необходимо. приходит к сложным частям, таким как разработка требований для проверки честности и честности. Это может гарантировать, что справедливость воспринимается серьезно, а работа по обеспечению справедливости выполняется специалистами, которые могут сосредоточиться на работе по обеспечению справедливости, которые сотрудничают с другими специалистами по справедливости и могут быть в курсе последних исследований и публичных дискуссий, в то же время позволяя другим членам команды сосредоточиться на своих основных задачах.
Специализированная команда по ответственному машинному обучению может служить движущей силой, но собрать ресурсы за пределами крупных организаций может быть сложно. Иногда существующим юридическим командам также может быть поручено контролировать работу по обеспечению справедливости. При наличии мандата любая из этих групп или даже отдельные лица с достаточной организационной поддержкой могут оказывать поддержку, обучение и надзор за деятельностью по развитию, а также они могут требовать и проверять доказательства того, что деятельность, связанная с обеспечением справедливости, была фактически завершена в рамках процесса проведения продуктовые команды ответственны.
Документирование справедливости на интерфейсе
Хотя справедливость обычно обсуждается на уровне модели, она влияет на всю конструкцию системы и, следовательно, затрагивает несколько команд, включая группы специалистов по данным, создающих модель, группы инженеров-программистов, интегрирующих модель в продукт, группы операторов, контролирующих систему в процессе производства. , а также юридическая команда, обеспечивающая соблюдение законов и правил. Как и в случае всех проблем, выходящих за рамки команд, необходимо обсуждать и договариваться о вопросах справедливости между командами и документировать ожидания и гарантии на интерфейсе между командами (общая тема в этой книге, см. также главы Мыслить как программный архитектор, Развертывание модели и Междисциплинарные команды).
В идеале все требования справедливости документируются как часть системных требований и разбиваются на требования справедливости для отдельных компонентов. В частности, для компонентов, принимающих решения с помощью моделей с машинным обучением, документация по требованиям должна четко определять, какие атрибуты считаются защищенными, если таковые имеются, и для каких критериев справедливости следует оптимизировать компонент, если таковые имеются. Для реализованного компонента вывода модели результаты оценки достоверности должны быть задокументированы вместе с компонентом. Предлагаемый формат документации Карточки моделей (рассмотренный ранее в главе Развертывание модели) представляет собой хороший шаблон, в котором подчеркиваются соображения справедливости при обращении к разработчикам моделей с просьбой описать предполагаемые варианты использования и предполагаемых пользователей модели. модель, рассматриваемые демографические факторы, точность результатов по подгруппам, характеристики используемых оценочных данных, а также этические соображения и ограничения.
Многие проблемы справедливости возникают из-за предвзятости в процессе сбора данных (как обсуждалось выше), поэтому документирование как процесса, так и предположений, лежащих в основе этого процесса, а также итогового распределения данных важно для обмена информацией между командами, чтобы избежать того, что специалисты по данным делают неправильные предположения о данные, которые они получают. Здесь Таблицы данных — это часто обсуждаемое предложение по документированию набора данных, в котором, среди прочего, делается попытка четко указать, что данные пытаются представить, как данные были собраны и отобраны, как они представляют различные подсовокупности, что известный шум и предвзятость, которые он содержит, какие атрибуты можно считать конфиденциальными и какой процесс получения согласия был задействован при сборе данных, если таковой имел место. Недавний эксперимент Карен Л. Бойд дает обнадеживающие доказательства того, что доступность таблицы данных с предоставленным набором данных для задачи машинного обучения может стимулировать этические рассуждения об ограничениях и потенциальных проблемах с данными. Помимо таблиц данных было предложено несколько других форматов для документирования данных с аналогичными целями (например, Ярлыки набора данных о питании, Отчеты о данных), иногда специализированные для определенных областей, таких как обработка естественного языка.

Мониторинг
Хотя некоторые проблемы со справедливостью могут быть обнаружены на тестовых данных при автономной оценке, эти тестовые данные могут не отражать реальное использование в производстве, и некоторые проблемы могут возникнуть из-за того, как пользователи используют систему и взаимодействуют с ней. Кроме того, поведение модели и пользователя может меняться со временем, поскольку модель переобучается, а поведение пользователя дрейфует, и некоторые проблемы со справедливостью могут стать видимыми только со временем, когда небольшие различия усиливаются через петли обратной связи. Поэтому важно оценивать справедливость системы в производстве и постоянно контролировать систему.
Если инфраструктура для оценки качества модели или системы в производстве уже существует, как обсуждалось в главе «Обеспечение качества в производстве», расширить ее в сторону справедливости довольно просто. Ключом к оценке справедливости в рабочей среде является операционализация интересующей метрики справедливости с данными телеметрии. Предполагая, что у нас есть доступ к защищенным атрибутам, таким как пол или раса, как часть данных логического вывода или нашей пользовательской базы данных, мы можем проверить справедливость группы на уровне модели, просто отслеживая уровень положительных прогнозов для различных подгрупп и настраивая оповещения. в случае, если ставки расходятся во времени. Например, мы можем наблюдать, как наша модель заявок на ипотеку отклоняет заявки от белых и черных заявителей. Это можно распространить на системный уровень, отслеживая количество результатов, например, отслеживая, приводят ли рекомендации песен на потоковой платформе к значительно более низкой вовлеченности испаноязычных клиентов по сравнению с неиспаноязычными клиентами. Для уравненных шансов и связанных метрик нам необходимо дополнительно определить (или приблизить) правильность прогнозов, например, опросив пользователей, наблюдая за их реакцией или ожидая подтверждения в будущих данных (подробности см. в главе «Обеспечение качества в производстве»).
Помимо наблюдения за прогнозами и результатами, также стоит следить за сдвигами в распределении данных, как описано в главе «Качество данных». Если производственные и оценочные данные расходятся, автономные оценки справедливости и прошлые аудиты могут больше не давать заслуживающих доверия результатов. Точно так же изменение численности населения с течением времени может указывать на проблему, которая может заслуживать пересмотра порогов справедливости.
В производственной среде стоит предоставить пользователям возможность сообщать о проблемах и обжаловать решения (см. главу «Прозрачность и подотчетность») и отслеживать всплески жалоб. Если наша система мониторинга предупредит нас о внезапном всплеске жалоб от одной группы населения, это может указывать на недавнюю проблему со справедливостью, которую стоит изучить в срочном порядке.
Наконец, также стоит подготовить план реагирования на непредвиденные проблемы справедливости (см. главу «Планирование операций»). Готовность к проблемам может помочь более эффективно справляться с потенциальной негативной реакцией и минимизировать ущерб для репутации. План должен учитывать, по крайней мере, что делать в кратчайшие сроки (например, отключить функцию или всю систему, восстановить старую версию, заменить модель эвристикой) и как поддерживать линии связи перед лицом внешнего контроля.
Лучшие практики
Лучшие практики обеспечения справедливости в продуктах с поддержкой машинного обучения все еще развиваются, но они включают действия, описанные выше. Рекомендации почти всегда включают раннее начало и активную работу по обеспечению справедливости, учитывая, что на ранних этапах требований и проектирования существует гораздо больше гибкости, чем при попытке решить проблему в производственной среде с помощью поздних корректировок моделей или данных. В частности, разработка требований и тщательно продуманный дизайн процесса сбора данных рассматриваются как важные рычаги для достижения справедливости на уровне системы. Образование всегда играет центральную роль, поскольку осведомленность и заинтересованность необходимы для серьезного отношения к работе по обеспечению справедливости, даже если фактическая работа в конечном итоге в основном делегируется специалистам.
Несколько исследователей и практиков разработали учебные пособия и контрольные списки, которые могут помочь в продвижении и проведении работы по обеспечению справедливости. Например, учебные пособия Справедливость в машинном обучении, Машинное обучение с учетом справедливости на практике и Проблемы внедрения алгоритмической справедливости в отраслевую практику охватывают многие понятия справедливости, источники предвзятости и обсуждения процессов, которые также рассматриваются в эта глава. В Контрольном списке честности ИИ Microsoft рассматриваются конкретные вопросы, помогающие собирать требования и принимать решения, а также предлагаются конкретные шаги на всех этапах, включая развертывание и мониторинг.
Краткое содержание
Автоматизация решений с помощью моделей с машинным обучением вызывает опасения по поводу несправедливого обращения с различными подгруппами населения, что может нанести ущерб распределению и представлению. Хотя машинное обучение часто позиционируется как более объективное, чем предвзятое принятие решений человеком, предвзятость из реального мира может проникать в модели с машинным обучением разными способами, и, если ее не остановить, система с поддержкой ML может отражать или усиливать существующие предубеждения, а не способствует более справедливому будущему.
Однако справедливость трудно уловить. Существуют разные представления о справедливости, которые особенно противоречат друг другу при обсуждении того, что является справедливым, когда между подгруппами существуют врожденные или исторические различия: должна ли система просто игнорировать членство в группе, должна ли она гарантировать, что все группы получают услуги с одинаковой точностью, или она должна признавать и активно противодействовать существующее неравенство? Каждое из этих понятий справедливости может быть формализовано и измерено на уровне модели.
Тем не менее, анализа справедливости на уровне модели недостаточно, важно учитывать, как модель используется в программной системе и как эта система взаимодействует со средой. Чтобы серьезно относиться к работе с требованиями, ее необходимо интегрировать в процесс разработки и действовать на опережение. Ключевая проблема в построении справедливых систем (с машинным обучением и без него) заключается в разработке требований и проектировании для выявления потенциального вреда и согласования требований справедливости, а также в понимании того, как система будет взаимодействовать с окружающей средой, как могут возникать петли обратной связи и как потенциальный вред можно уменьшить. При машинном обучении процесс сбора данных требует особого внимания, так как именно там может быть расположено большинство источников систематической ошибки. Документирование и мониторинг важны, но часто недооцениваются, когда речь идет о создании и эксплуатации систем междисциплинарными командами.
Дальнейшее чтение
- Очень доступная книга со множеством примеров предвзятости и петель обратной связи автоматизированных систем принятия решений: 🕮 О’Нил, Кэти. Оружие математического разрушения: как большие данные увеличивают неравенство и угрожают демократии. Издательство Корона, 2017.
- Отличные туториалы: 🖮 Барокас, Солон и Мориц Хардт. «Справедливость в машинном обучении.» NIPS Tutorial 1 (2017) [слайды] и 🖮 Генриетта Крамер, Кеннет Холштейн, Дженнифер Вортман Воган, Хэл Дауме III, Мирослав Дудик, Ханна Уоллах, Шравана Редди, Джин Гарсия-Гатрайт. «Учебное пособие по переводу FAT* 2019: проблемы внедрения алгоритмической справедливости в отраслевую практику», Учебное пособие по FAT*19 (2019 г.) [слайды] и 🖮 Машинное обучение с учетом справедливости, Bennett et al., Учебное пособие по WSDM (2019 г.). и 🖮 Беннетт, Пол, Сара Берд, Бен Хатчинсон, Кришнарам Кентапади, Эмре Кичиман и Маргарет Митчелл. «Машинное обучение с учетом справедливости: практические проблемы и извлеченные уроки.» Учебное пособие по WSDM. 2019.
- (Неполная) книга с подробным обсуждением показателей справедливости: 🕮 Солон Барокас, Мориц Хардт и Арвинд Нараянан. Справедливость и машинное обучение. 2019
- Глава книги, посвященная показателям справедливости и полемике с ProPublica: 🕮 Ян Фостер, Райид Гани, Рон С. Джармин, Фрауке Кройтер и Джулия Лейн. Большие данные и социальные науки: методы и инструменты науки о данных для исследований и практики. Глава 11, 2-е изд., 2020 г.
- Подробное обсуждение различных источников предвзятости и различных представлений о справедливости: 🗎 Барокас, Солон и Эндрю Д. Селбст. «Разрозненное влияние больших данных.» Калифорния Л. Ред. 104 (2016): 671.
- Опрос с исчерпывающим списком возможных источников предвзятости: 🗎 Мехраби, Нинаре, Фред Морстаттер, Нрипсута Саксена, Кристина Лерман и Арам Галстян. «Опрос о предвзятости и справедливости в машинном обучении.» ACM Computing Surveys (CSUR) 54, вып. 6 (2021): 1–35.
- Исследование интервью и опрос практиков, изучающих проблемы справедливости в производственных системах на протяжении всего жизненного цикла: 🗎 Холштейн, Кеннет, Дженнифер Вортман Воан, Хэл Дауме III, Миро Дудик и Ханна Уоллах. «Повышение справедливости в системах машинного обучения: что нужно специалистам в отрасли?» Материалы конференции CHI 2019 года по человеческому фактору в вычислительных системах, стр. 1–16. 2019.
- Еще одно исследование с интервью о работе по обеспечению справедливости на практике, в котором каталогизируются текущие практики и подчеркиваются стремления, часто с сильным акцентом на организационные практики и интеграцию процессов: 🗎 Ракова, Богдана, Цзинъинг Ян, Генриетта Крамер и Румман Чоудхури. «Где ответственный ИИ встречается с реальностью: взгляды практиков на средства изменения организационной практики.» Труды ACM по взаимодействию человека с компьютером 5, вып. CSCW1 (2021): 1–23.
- Исследование интервью, посвященное проблемам справедливости в небольших организациях: 🗎 Хопкинс, Аспен и Серена Бут. «Практики машинного обучения вне больших технологий: как ограничения ресурсов мешают ответственному развитию.» В материалах конференции AAAI/ACM 2021 года по ИИ, этике и обществу (AIES ’21) (2021).
- Документ, разрабатывающий и представляющий контрольный список справедливости для практиков: 🗎 Мадайо, Майкл А., Люк Старк, Дженнифер Вортман Воан и Ханна Уоллах. «Совместная разработка контрольных списков для понимания организационных проблем и возможностей, связанных с справедливостью в ИИ.» В материалах конференции CHI 2020 г. по человеческому фактору в вычислительных системах, стр. 1–14. 2020.
- Провокационная статья, иллюстрирующая опасность узкого внимания только к показателям справедливости на уровне модели: 🗎 Ос Киз, Джеван Хатсон, Мередит Дурбин. «Предложение по мульчированию: анализ и улучшение алгоритмической системы для превращения пожилых людей в высокопитательную навозную жижу.» Расширенные тезисы CHI, 2019.
- Подчеркивая необходимость учитывать более широкий контекст того, как модель используется при обсуждении справедливости и как моральная философия может направлять обсуждения: 🗎 Биетти, Элеттра. «От мытья этики к избиению этики: взгляд на техническую этику изнутри моральной философии.» В материалах конференции 2020 г. по справедливости, подотчетности и прозрачности, стр. 210–219. 2020.
- Обзор философских аргументов и истории дискриминации и справедливости: 🗎 Биннс, Рубен. «Справедливость в машинном обучении: уроки политической философии.» В конференции по справедливости, подотчетности и прозрачности, стр. 149–159. ПМЛР, 2018.
- Примеры подходов отладки на уровне модели для поиска подгрупп с несправедливыми прогнозами: 🗎 Трамер, Флориан, Ваггелис Атлидакис, Роксана Геамбасу, Даниэль Хсу, Жан-Пьер Юбо, Матиас Умбер, Ари Джуэлс и Хуан Линь. «FairTest: обнаружение необоснованных ассоциаций в приложениях, управляемых данными.» Европейский симпозиум IEEE по безопасности и конфиденциальности (EuroS&P) 2017 г., стр. 401–416. IEEE, 2017 г. и 🗎 Чанг, Ёуно, Неоклис Полизотис, Кихён Тэ и Стивен Ыйджонг Ван. «Автоматизированное разделение данных для проверки модели: подход к интеграции больших данных и ИИ.» Транзакции IEEE по знаниям и обработке данных (2019 г.).
- Документация по соображениям справедливости в наборах данных и моделях: 🗎 Гебру, Тимнит, Джейми Моргенштерн, Бриана Веккионе, Дженнифер Вортман Воан, Ханна Уоллах, Хэл Дауме III и Кейт Кроуфорд. «Даташиты для наборов данных.» Сообщения ACM 64, вып. 12 (2021): 86–92. и 🗎 Митчелл, Маргарет, Симона Ву, Эндрю Залдивар, Паркер Барнс, Люси Вассерман, Бен Хатчинсон, Елена Спитцер, Иниолува Дебора Раджи и Тимнит Гебру. «Модельные карточки для модельных отчетов.» В материалах конференции по справедливости, подотчетности и прозрачности, стр. 220–229. 2019.
- Эксперимент с участием человека, наблюдающий за тем, как этическая чувствительность и принятие решений могут поддерживаться таблицами данных: 🗎 Бойд, Карен Л. «Таблицы данных для наборов данных помогают инженерам машинного обучения замечать и понимать этические проблемы в обучающих данных.» Труды ACM по взаимодействию человека с компьютером 5, вып. CSCW2 (2021): 1–27.
- Конкретное обсуждение и анализ справедливости в ипотечном кредитовании: 🗎 Ли, Мишель Сенг А и Лучано Флориди. «Алгоритмическая справедливость в ипотечном кредитовании: от абсолютных условий к относительным компромиссам.» Умы и машины 31, вып. 1 (2021): 165–191.
- Отличная интерактивная визуализация компромиссов и конфликтов между различными целями справедливости при принятии решений о кредитовании: 🖮 Мартин Ваттенберг, Фернанда Вьегас и Мориц Хардт. «Атака на дискриминацию с помощью более умного машинного обучения.»
- Обзорный документ, в котором перечислены вмешательства на уровне модели для повышения справедливости: 🗎 Песах, Дана и Эрез Шмуэли. «Обзор честности в машинном обучении.» ACM Computing Surveys (CSUR) 55, вып. 3 (2022): 1–44.
Как и все главы, этот текст выпущен под лицензией Creative Commons 4.0 BY-SA.