Существенный вклад в развитие ИИ каждого пользователя Интернета в наши дни.
Думаю, если вы читаете эту статью, то уже много раз в своей повседневной жизни сталкивались с доказательствами того, что вы не робот. Лично я сталкиваюсь с этим каждый день, когда пытаюсь зайти на какой-нибудь сайт. Я должен доказать, что я не робот. Раньше это были текстовые CAPTCHA, которые мне нужно было решить, но в настоящее время мы видим множество CAPTCHA на основе изображений, специально созданных Google. Некоторые веб-сайты даже предлагают вам аудио CAPTCHA и простые математические вычисления.

Честно говоря, кажется раздражающим каждый раз сталкиваться с этим простым препятствием (иногда раздражающе сложным), чтобы доказать, что вы не робот. Однако вы можете немного гордиться тем, что помогаете разрабатывать решения на основе ИИ, такие как беспилотные автомобили.
В этой статье я хотел бы дать краткое представление о том, как эти изображения CAPTCHA, которые вы пометили, можно использовать для разработки искусственного интеллекта. Я называю это краткой идеей, потому что с этими CAPTCHA может проводиться много исследований или применений, но здесь я предоставляю вам информацию, основанную на моих исследованиях и обоснованных предположениях.
Прежде чем понять основную цель этой статьи, давайте познакомимся с историей CAPTCHA и их основным назначением.
Что такое капча?
CAPTCHA — это Полностью автоматизированный публичный тест Тьюринга, позволяющий отличить компьютеры от людей. Сама аббревиатура объясняет функцию. Это тип процедуры, которая используется для дифференциации людей и компьютеров. Основная цель этой процедуры — устранить спам-ботов, которые заходят на ваш сайт, и избежать любых мошеннических действий или автоматического создания учетной записи.
В 2003 году он был впервые разработан исследователями из Университета Карнеги-Меллона. Первоначально используется только текст, который представляется таким образом, что только люди могут его прочитать, а компьютеры — нет. Позже, с развитием компьютерных наук и искусственного интеллекта, стало проще запрограммировать бота, который сможет обмануть эти тесты. Следовательно, появились новые способы отличить людей от компьютеров, и прямо сейчас с помощью изображений почти невозможно обмануть тест. Google максимально использовал эту CAPTCHA и создал свои собственные версии под названием reCAPTCHA. Тем не менее, ведется много исследований по созданию ботов, которые могут выполнять поведение, близкое к человеческому.

reCAPTCHA от Google
В 2007 году Google выпустил reCAPTCHA, позволив веб-хостам различать людей и роботов, которые автоматически получают доступ к веб-сайтам. Основные варианты использования включают предотвращение мошеннических транзакций, захвата учетных записей, учетных записей синтетических ботов и отмывания денег.
Первоначальный выпуск просто просил пользователя расшифровать текст отображаемого изображения или сопоставить показанные изображения с данным описанием. Позже Google выпустил reCAPTCHA v2 в 2014 году с флажком Я не робот и невидимыми вызовами значка reCAPTCHA. В 2018 году была выпущена reCAPTCHA v3, которая проверяет запрос пользователя с помощью оценки и предоставляет вам доступ. Эта версия reCAPTCHA устраняет дискомфорт при нажатии на изображения, пока вы не сделаете это правильно. Теперь последней версией является reCAPTCHA Enterprise, и Google утверждает, что обеспечивает беспрепятственный пользовательский интерфейс, распространяя услугу на весь веб-сайт, а не только на некоторые выбранные страницы.
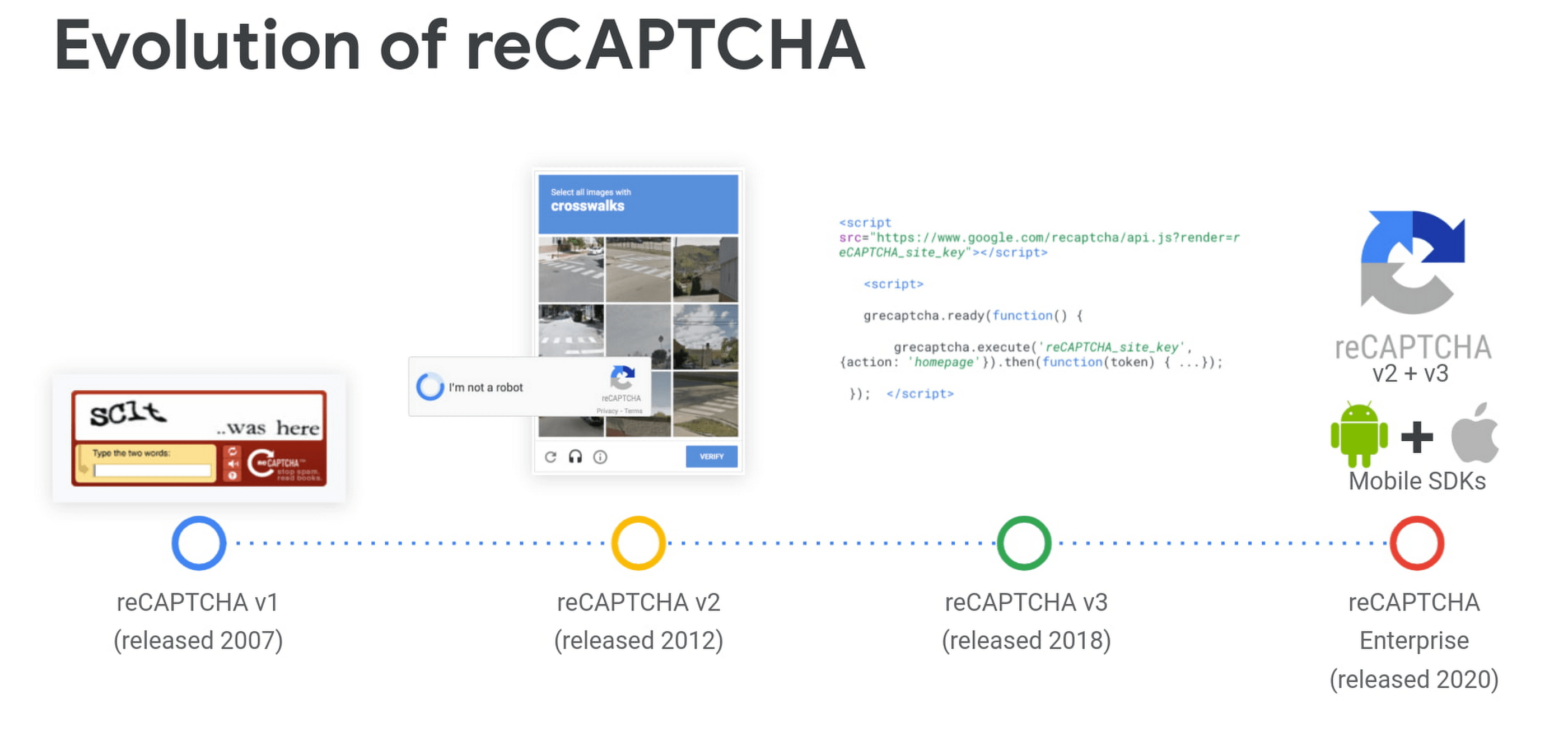
reCAPTCHA и варианты ее использования, а также создание самой reCAPTCHA — это отдельная тема. К сожалению, это выходит за рамки данной статьи. Вы можете посетить руководство разработчика reCAPTCHA v3 Google для получения дополнительной информации об этом.
reCAPTCHAs обучающий ИИ
В настоящее время данные доступны повсюду, и компании следят за тем, чтобы эти данные использовались в максимальной степени. Но также иногда очень трудно получить определенные данные, которые были помечены, в частности, людьми. Особенно в случае данных изображений каждое изображение должно быть помечено, чтобы алгоритмы научились классифицировать или обнаруживать объекты. Компании и отрасли тратят много человеческих усилий на маркировку данных и создание наборов данных.
Прежде чем углубиться в концепцию данных изображения, маркировки и классификации, я хотел бы быстро дать краткое описание обучения с учителем.
Обучение с учителем — это подкатегория машинного обучения, в которой вы предоставляете алгоритмам машинного обучения обучающие данные с метками для каждого наблюдения. Например, если вы обучаете алгоритм, чтобы он научился определять, является ли показанное изображение изображением кошки или изображения собаки, вам необходимо предоставить алгоритму несколько уже помеченных изображений кошек и собак. Алгоритм обучения учится определять, кошка это или собака, с помощью заданного набора размеченных данных. Когда новое изображение передается обученному алгоритму, он говорит, есть ли на изображении кошка или собака. Короче говоря, обучению с учителем нужны метки для обучения алгоритма.
Google AI — одно из крупнейших предприятий в области искусственного интеллекта, которое активно занимается исследованиями и разработкой новых решений. Каждый раз, когда вы пытаетесь войти на какой-либо веб-сайт, контролируемый reCAPTCHA, вам нужно нажимать на изображения, на которых изображены пожарные гидранты, мосты, автомобили, пешеходные переходы, велосипеды, светофоры и т. д. Эти изображения сложно идентифицировать роботу/синтетическому боту. В основном эти изображения нуждаются в человеческом глазе, чтобы различать и выбирать. Следовательно, например, когда вы выбираете изображение с пожарным гидрантом, вы создаете метку для этого изображения, говорящую, что есть пожарный гидрант.
В качестве альтернативы существуют также версии reCAPTCHA, которые просят нас выбрать поля в сетке со всеми светофорами, пешеходными переходами и т. д. Обоснованно предположить, что все изображение было преобразовано в сетку, и когда вы выбираете части изображения (поля в сетке) на основе описания, вы создаете метку для этой конкретной сетки изображений, чтобы использовать их при обнаружении объекта.

Все эти ярлыки собираются бэкендом как побочный продукт, и он формирует огромный набор данных с введенными людьми ярлыками с точностью не менее 95–100%.
Эти наборы данных затем используются в качестве эталонных данных для различных алгоритмов классификации изображений, обнаружения объектов и семантической сегментации. Один из наиболее распространенных вариантов использования такого рода данных — автомобили с автоматическим управлением. Waymoявляетсяпроектом беспилотных автомобилей Google. Поскольку все эти изображения, показанные в reCAPTCHA, являются изображениями, снятыми на улице, можно предположить, что Google использует их для обучения беспилотных автомобилей.

У Amazon также есть собственный способ создания помеченного набора данных. У Amazon Web Services есть Mechanical Turk и Sagemaker Ground Truth, которые используют человеческие аннотаторы для маркировки данных. Можно настроить рабочую силу для управления этими задачами аннотирования данных и создания меток для желаемого набора данных.
Заключение
В этом развивающемся мире данные играют решающую роль в развитии событий. Хотя сами данные сильно различаются для каждого варианта использования, важно манипулировать данными для вашего использования.
Мотивация внедрения CAPTCHA вначале была другой, но теперь она служит для другого использования. Это также добавило большое преимущество, устранив сложную и утомительную задачу, то есть маркировку данных.
Ресурсы
Эта статья написана на основе информации, которую мне удалось собрать в ходе моего исследования. К сожалению, я не смог получить больше информации о том, как именно эти данные используются в каждой задаче в Google AI и беспилотных автомобилях. Я был бы рад узнать больше об этом, если я что-то пропустил. И если вы думаете/знаете, что есть еще варианты использования этих изображений CAPTCHA, сообщите мне об этом.