В марте этого года IBM The Cloud Developer Advocates из группы разработчиков IBM в Саудовской Аравии открыли семинар IBM DSX в инкубаторе Badir.
Цель этого семинара — помочь разработчикам построить прогнозную модель с помощью инструмента IBM Data Science Experience (DSX).
Дима Аламар открыла сессию, объяснив важность науки о данных и то, как данные являются сырой нефтью; это ценно, но нуждается в доработке. Она ознакомилась с Международным стандартным процессом интеллектуального анализа данных «CRISP-DM» и различными ролями в области обработки данных, включенными в каждый этап.

Затем я начал объяснять реальные примеры науки о данных и концепции машинного обучения и методологии. Я рассказал об инструменте IBM DSX и о том, как бизнес может преобразовать свои данные в реальную ценность для бизнеса с помощью новейших, наиболее гибких и открытых технологий. Мы объяснили, как IBM DSX может помочь командам сотрудничать с лучшими в своем классе инструментами с открытым исходным кодом и визуальными инструментами, а также с наиболее гибкими и масштабируемыми вариантами развертывания. Мы продемонстрировали, как разработчики могут комбинировать модели машинного обучения с расширенным предписывающим моделированием для оптимизации сложных бизнес-решений. Они могут использовать возможности быстрого визуального моделирования без кодирования, расширенные возможности подготовки данных и автоматически решать распространенные проблемы с качеством данных.
Наконец, мы засучили рукава и начали семинар с создания модели машинного обучения, которая прогнозирует отток клиентов в телекоммуникационной компании. Мы использовали IBM SPSS Modular для создания потока.
Задача 1. Создайте проект в IBM DSX
После того, как вы вошли в систему IBM DSX, вы можете приступить к созданию проекта.
- Прокрутите страницу вниз и нажмите значок (+) New project.
- Назовите свой проект «Предсказать отток клиентов».
- Прокрутите вниз, в разделе «Определить хранилище» нажмите Добавить, чтобы создать экземпляр IBM Cloud Object Storage. Сервис откроется, выберите тарифный план Lite и нажмите Создать.
- В службе Spark нажмите Добавить, чтобы создать экземпляр IBM Analytics для Apache Spark. Сервис откроется, выберите тарифный план Lite и нажмите Создать.
- Обновите страницу, чтобы убедиться, что сервисы добавлены.
- Нажмите «Создать», чтобы завершить создание проекта.

Задача 2. Загрузить набор данных
- Скачать набор данных
- На странице проекта перейдите на вкладку «Активы», перетащите загруженный файл набора данных и поместите его на боковую панель «Загрузить».
- Ваш набор данных должен быть успешно загружен!

Задача 3. Создайте модель SPSS
- Та же страница, что и раньше, прокрутите вниз до потоков Modeler.
- Нажмите значок (+) «Новый поток».
- На вкладке «Создать» назовите средство моделирования «Прогнозная модель» и убедитесь, что вы выбрали IBM SSPS Modeler Runtime. Затем нажмите Создать.

Задача 4. Проверка набора данных
У вас есть набор данных с данными о клиентах и данными об оттоке. Инженер данных объединил оба набора данных в один набор. Набор данных ожидает проверки на холсте. В этой задаче вы проверите набор данных с помощью IBM SPSS Modeler.
- Перетащите набор данных на холст.
- Щелкните Telco-Customer-Churn.csv. В открывшемся меню нажмите Предварительный просмотр. Показаны первые 10 записей набора данных.
- Прокрутите, чтобы проверить правую часть набора данных. Последний столбец, CHURN, содержит данные о том, ушел ли клиент или нет.
- Нажмите ОК, чтобы закрыть окно предварительного просмотра.

- В палитре щелкните вкладку «Вывод».
- Добавьте узел Аудит данных на холст, щелкнув Аудит данных.
- Подключите узел аудита данных к узлу Telco-Customer-Churn.csv, щелкнув Telco-Customer-Churn.csv. Узел «Аудит данных» автоматически переименовывается в «21 поле».
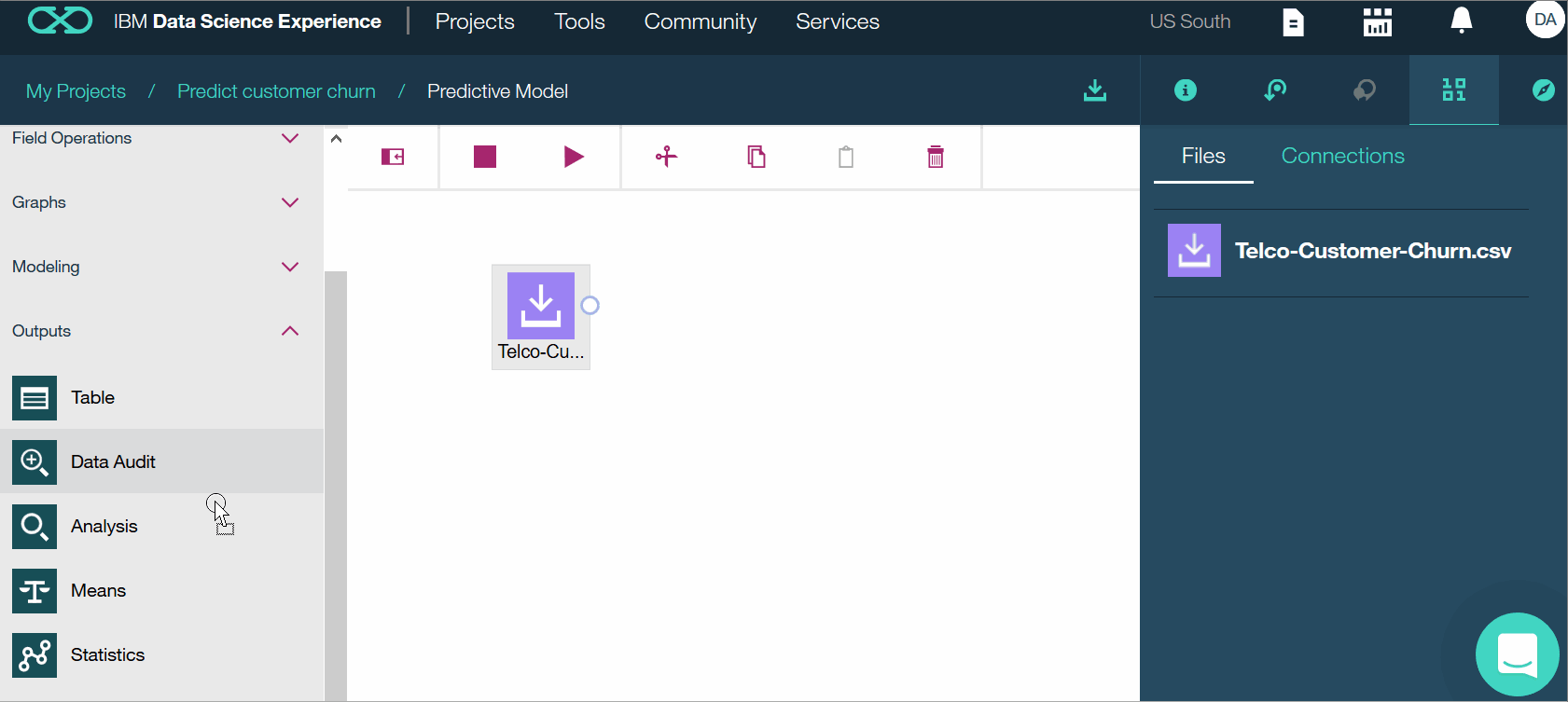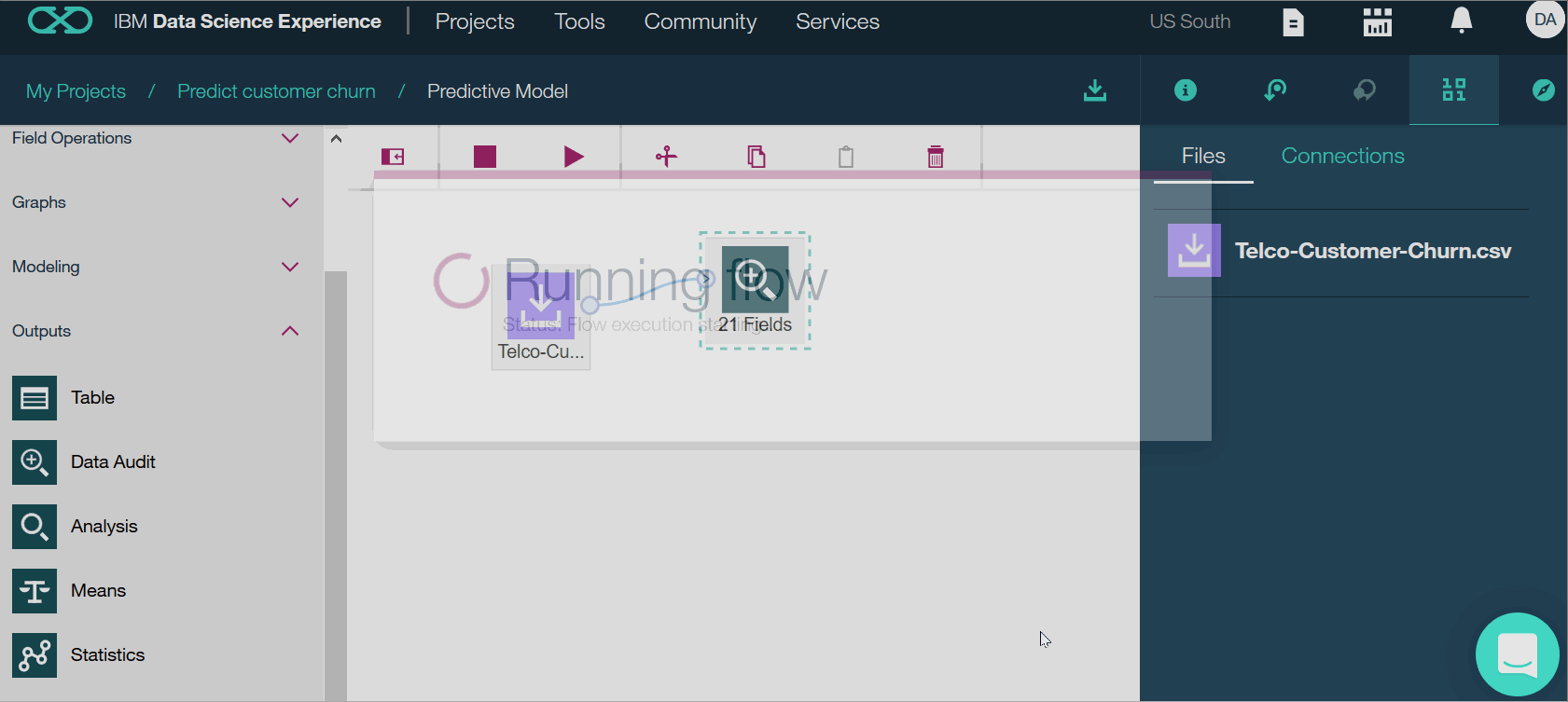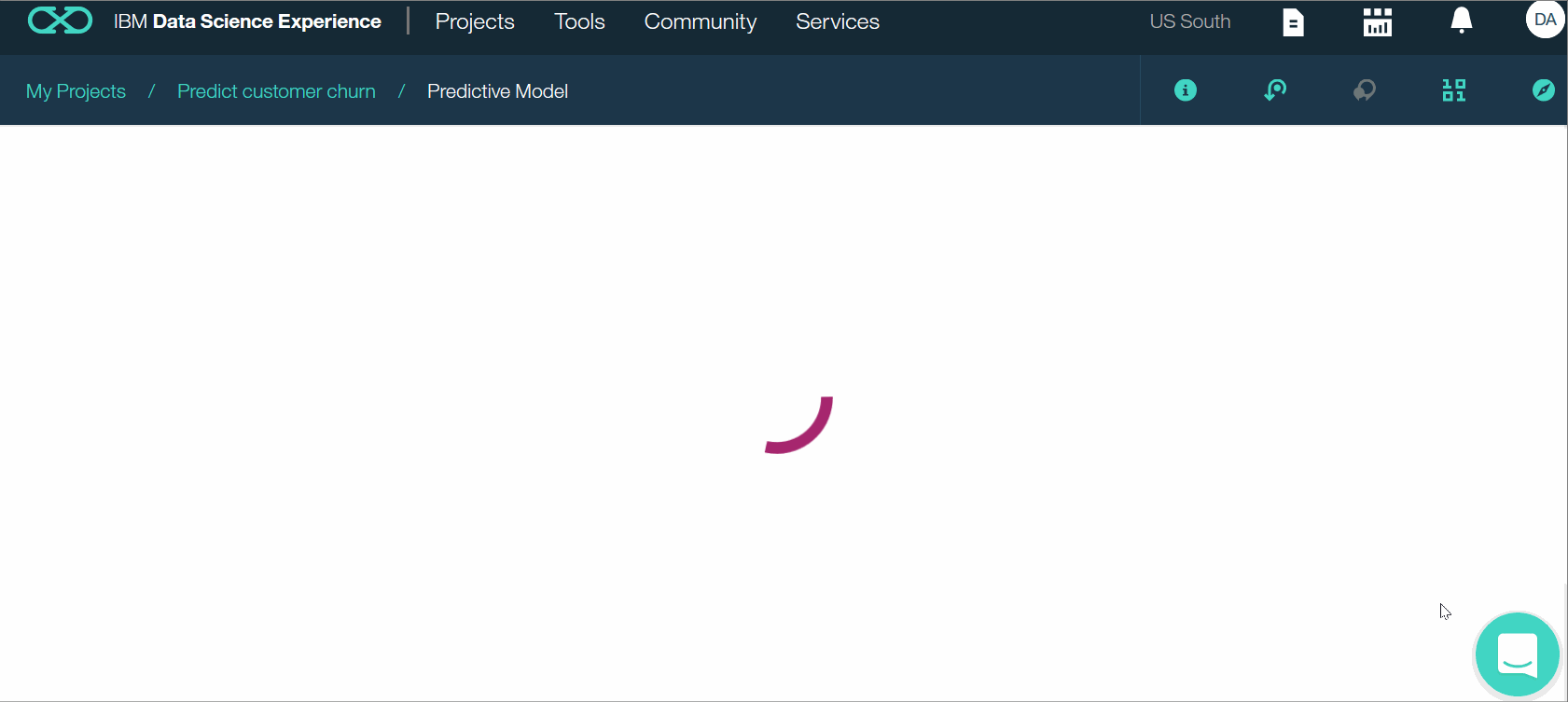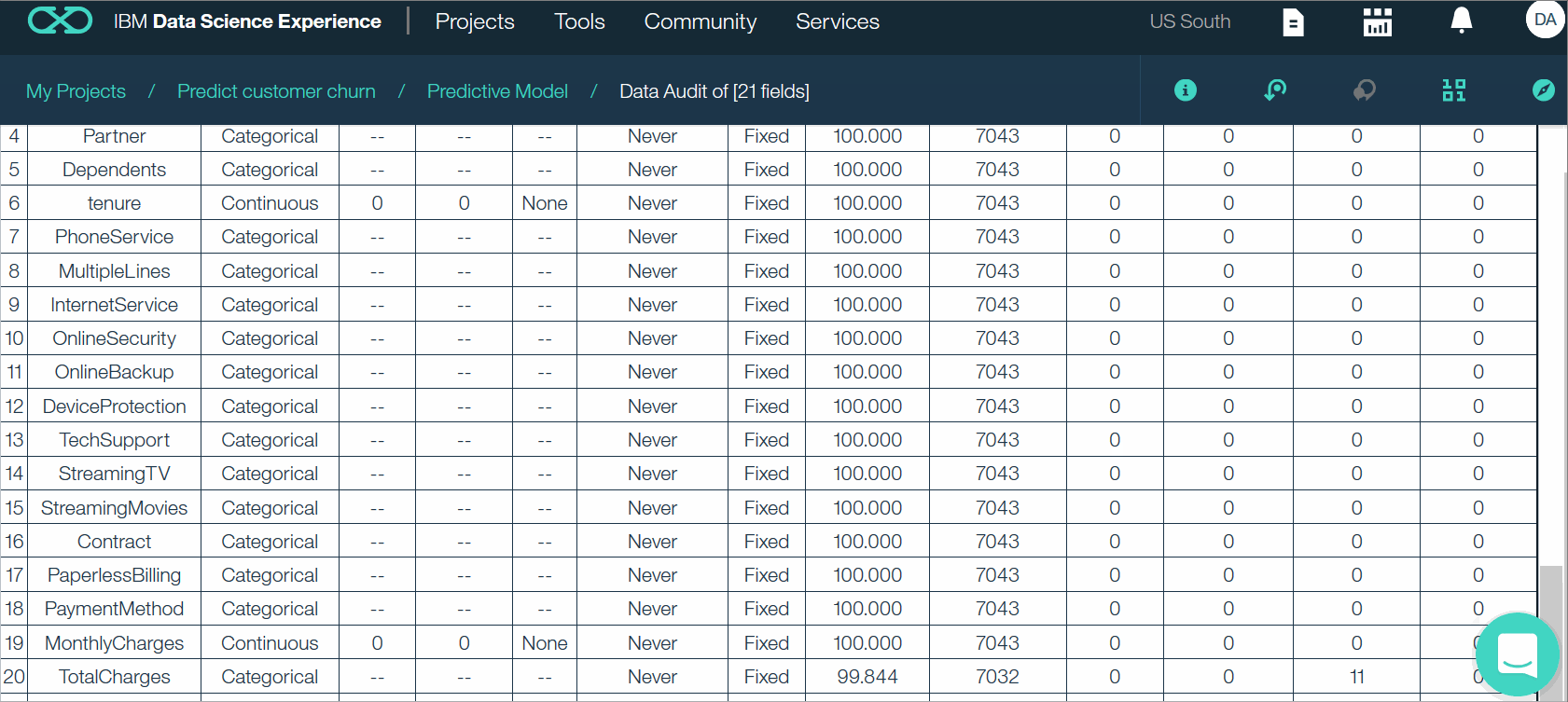
- Щелкните 21 поле. В открывшемся меню нажмите «Выполнить». Вы можете просмотреть ключевые статистические данные и показатели для набора данных. Когда вы закончите, нажмите OK, чтобы закрыть окно.
Задача 5. Подготовьте набор данных
Подготовьте набор данных для машинного обучения.
- В палитре перейдите на вкладку Field Ops.
- Добавьте узел Тип на холст, нажав Тип.
- Соедините узел Telco-Customer-Churn.csv с узлом Type, щелкнув Telco-Customer-Churn.csv.
- Нажмите Тип. В открывшемся меню нажмите Открыть.
- На правой боковой панели разверните настройки.
- Нажмите Настроить типы.
- Установите уровень измерения столбцов, щелкнув Read Values. В строке CustomerID щелкните Ввод. В открывшемся меню нажмите Record ID, чтобы изменить роль.
- Прокрутите до строки CHURN.
- Нажмите CHURN и измените роль с Input на Target. Строка CHURN используется в качестве цели для прогнозирования в вашей модели машинного обучения.
- Нажмите «Применить», а затем нажмите «ОК».

Задача 6. Обучите модель
Обучите модель дерева C&R с вашим набором данных.
- В палитре перейдите на вкладку Моделирование.
- Добавьте узел C&R Tree на холст, нажав C&R Tree.
- Соедините узел Дерево C&R с узлом Тип, нажав Тип. Узел C&R Tree автоматически переименовывается в «CHURN».
- Щелкните ИЗМЕНИТЬ. В открывшемся меню нажмите «Выполнить». Модель обучается, и на холст добавляется новый узел CHURN, который выглядит как золотой самородок.
- На выходе нажмите на результаты. Просмотрите модель и обратите внимание, какие функции являются важными предикторами. Когда вы закончите, нажмите OK, чтобы закрыть окно.
Задача 7. Оцените и визуализируйте модель
Оцените производительность модели и визуализируйте модель с помощью диаграммы усиления.
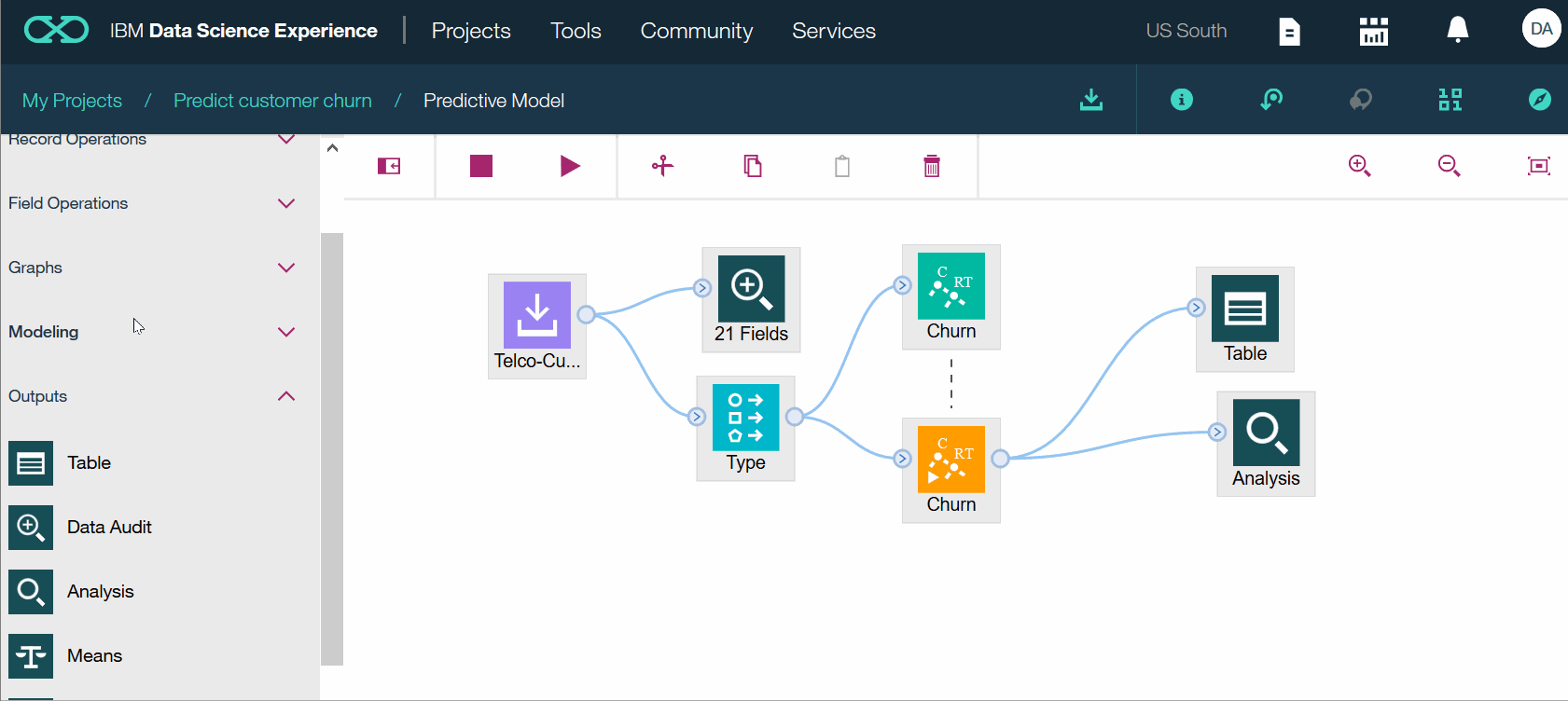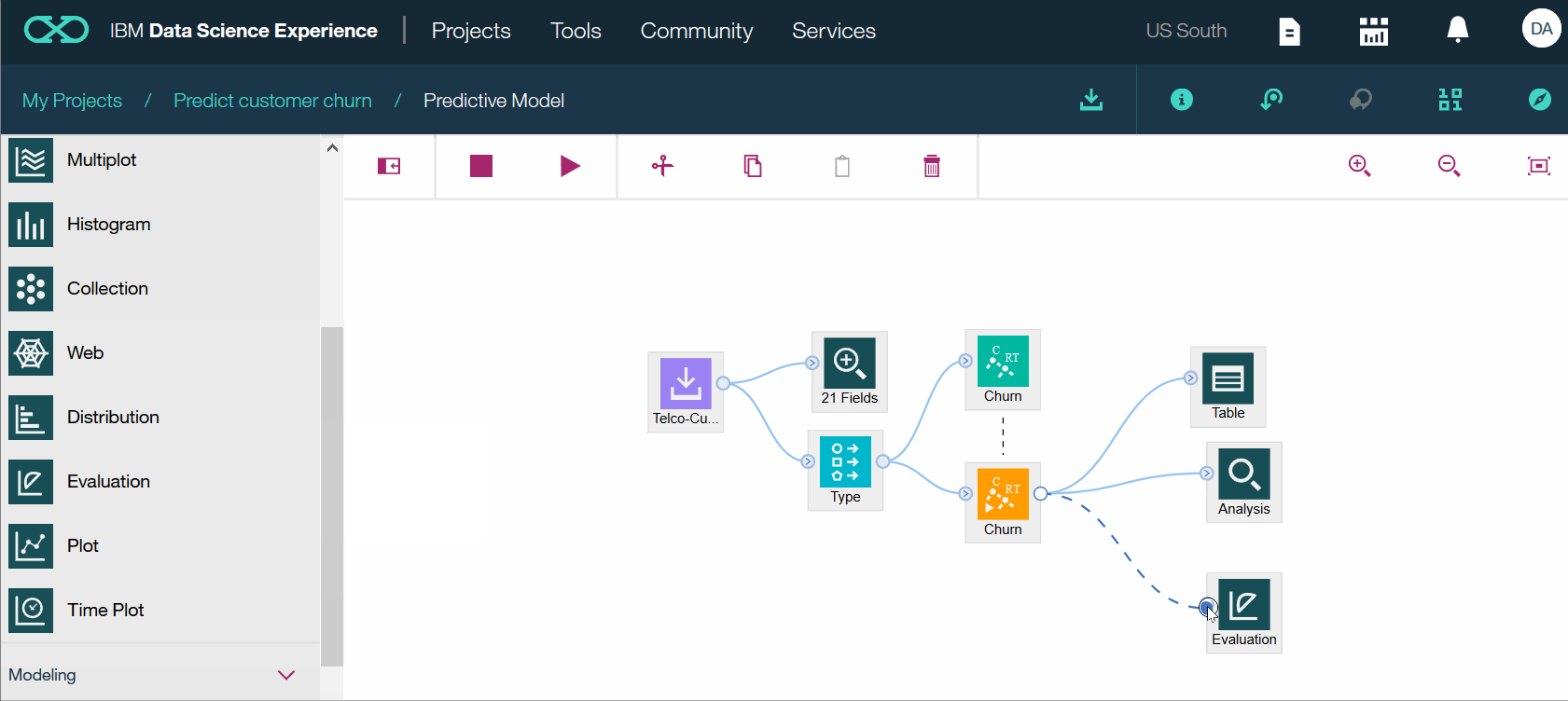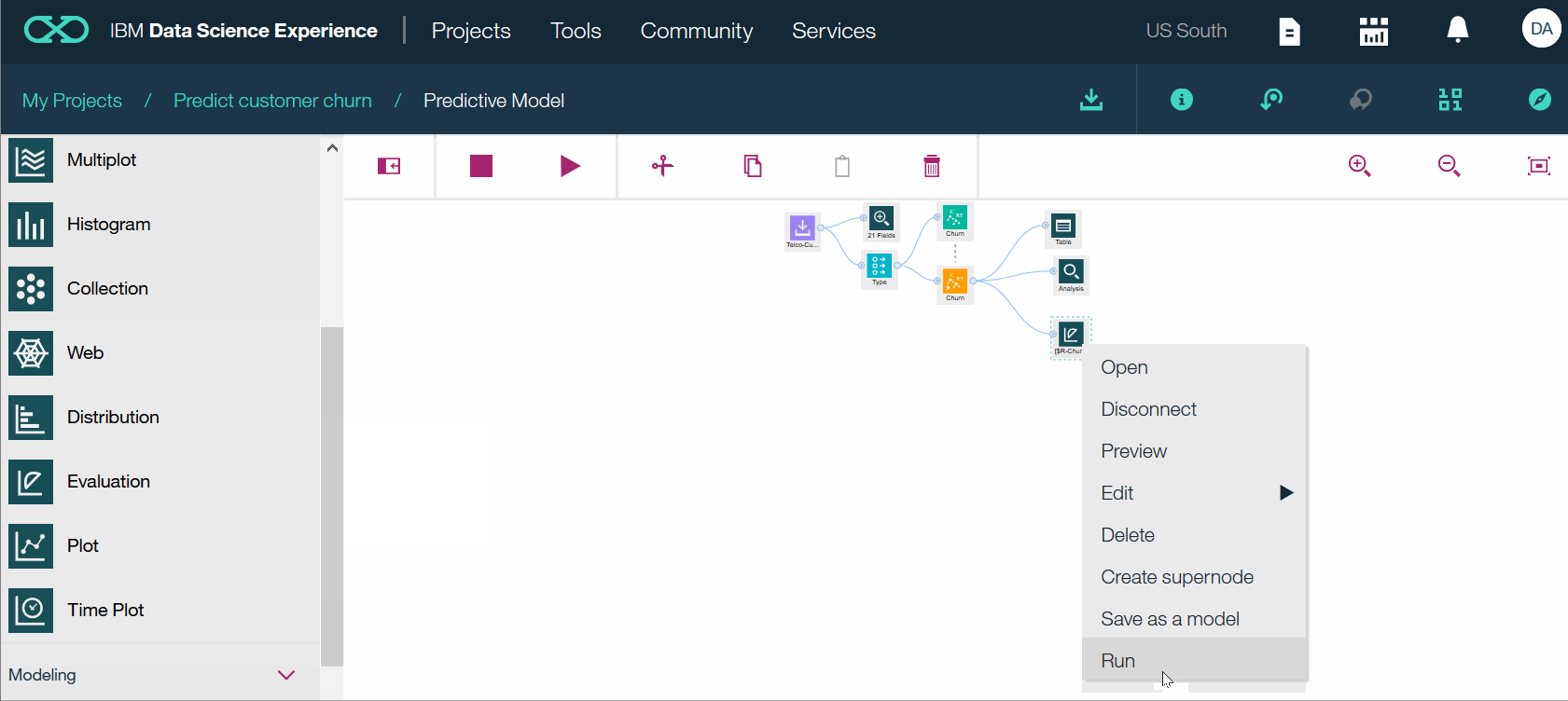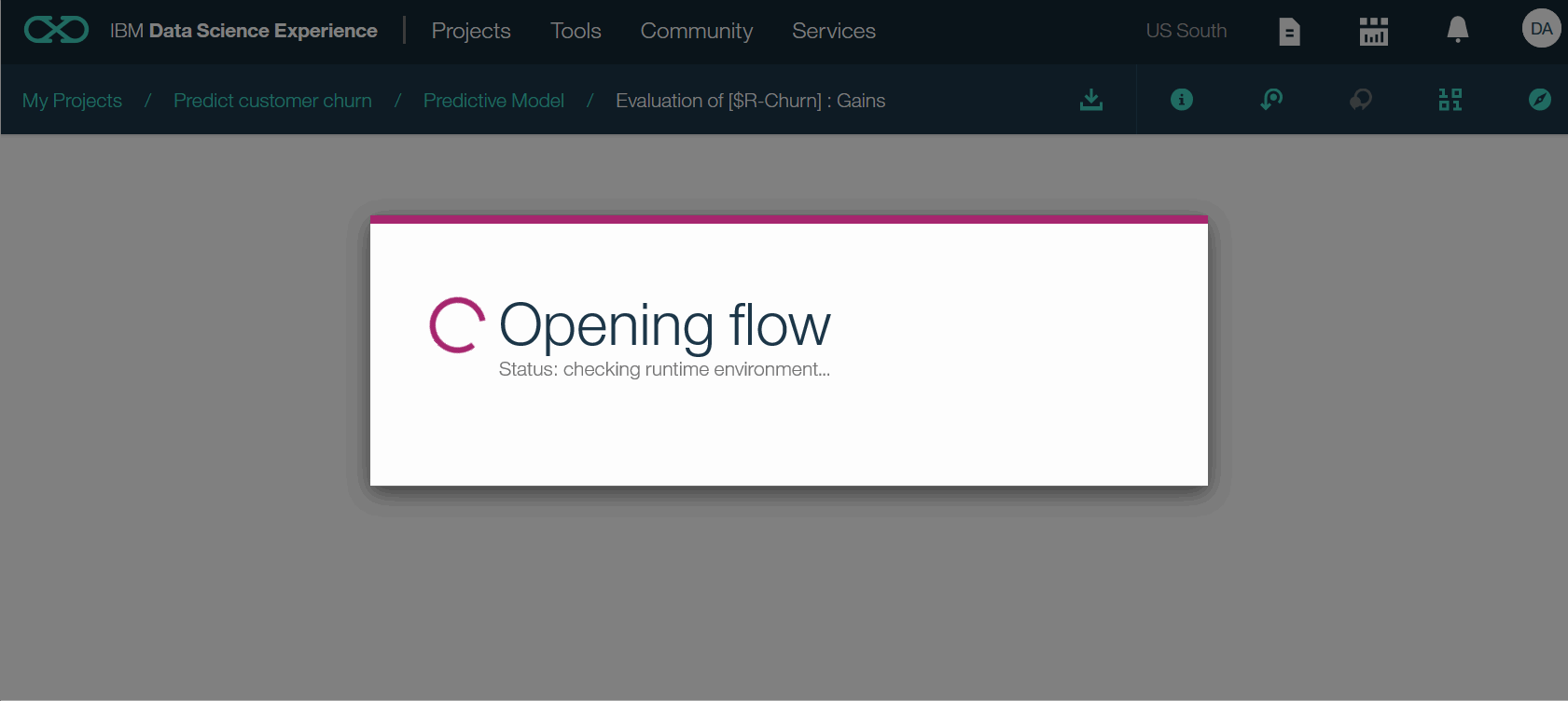
- В палитре перейдите на вкладку Вывод.
- Добавьте узел Таблица на холст, нажав Таблица.
- Добавьте на холст узел Анализ, нажав Анализ.
- Соедините узел золотого слепка CHURN с узлами Table и Analysis, щелкнув узел золотого слепка CHURN.
- Нажмите на золотой самородок CHURN еще раз. В открывшемся меню нажмите «Выполнить отсюда».
- В открывшемся боковом окне «Вывод» вы должны увидеть выходные данные как «Анализ», так и «Таблица».
- Нажмите на вывод Table, чтобы просмотреть результаты.
- Прокрутите вправо и обратите внимание, что в набор данных были добавлены два столбца: $R-CHURN и $RC-CHURN. Столбец $R-CHURN является столбцом предсказания. Столбец $RC-CHURN — это столбец уровня достоверности. Нажмите Прогнозная модель, чтобы вернуться на холст.
- Просмотрите производительность или точность модели в выходных данных анализа. Нажмите Прогнозная модель, чтобы вернуться на холст.

- В палитре перейдите на вкладку Графики.
- Добавьте узел оценки EvОценка на холст, нажав Оценка.
- Соедините узел Оценка с узлом CHURN Golden Nugget, щелкнув узел CHURN Golden Nugget.
- Нажмите ОТМЕНИТЬ. В открывшемся меню нажмите «Выполнить». Просмотрите диаграмму усиления. Когда вы закончите, нажмите Прогнозная модель, чтобы вернуться на холст.
Вы завершили обучение. Поздравляем!
В этом учебном пособии поверхностно рассматриваются многие мощные возможности IBM SPSS Modeler. В этом уроке вы выполнили следующие задачи:
1. Проверен набор данных об оттоке клиентов
2. Подготовил набор данных для машинного обучения
3. Обучение и оценка модели машинного обучения
4. Отображена диаграмма усиления модели
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Чувствуете, что пропустили это мероприятие, не волнуйтесь, впереди еще больше, присоединяйтесь к нашей группе встреч и следите за обновлениями.
Кредиты на эту демонстрацию идут на https://www.ibm.com/cloud/garage/demo/try-spss-modeler/