
Как использовать машинное обучение для обнаружения аномалий и мониторинга состояния
Конкретный вариант использования машинного обучения и статистического анализа
В этой статье я представлю несколько различных методов и приложений машинного обучения и статистического анализа, а затем покажу, как применять эти подходы для решения конкретного варианта использования для обнаружения аномалий и мониторинга состояния.
Цифровая трансформация, цифровизация, Индустрия 4.0 и т. д.
Это все термины, которые вы, вероятно, слышали или читали раньше. Однако за всеми этими модными словами основная цель - использование технологий и данных для повышения производительности и эффективности. Связь и поток информации и данных между устройствами и датчиками позволяет использовать множество доступных данных. Таким образом, ключевым фактором является возможность использовать эти огромные объемы доступных данных и фактически извлекать полезную информацию, что позволяет снизить затраты, оптимизировать емкость и свести к минимуму время простоя. Здесь в игру вступает недавний ажиотаж вокруг машинного обучения и анализа данных.
Обнаружение аномалий
Обнаружение аномалий (или обнаружение выбросов) - это идентификация редких элементов, событий или наблюдений, вызывающих подозрения, поскольку они значительно отличаются от большинства данных. Как правило, аномальные данные могут быть связаны с какой-либо проблемой или редким событием, например, банковское мошенничество, проблемы со здоровьем, структурные дефекты, неисправное оборудование и т. д. Такое соединение делает очень интересным возможность выбрать, какие точки данных можно считать аномалиями, поскольку идентификация этих событий обычно очень интересна с точки зрения бизнеса.
Это подводит нас к одной из ключевых задач: как определить, являются ли точки данных нормальными или аномальными? В некоторых простых случаях, как на рисунке ниже, визуализация данных может дать нам важную информацию.
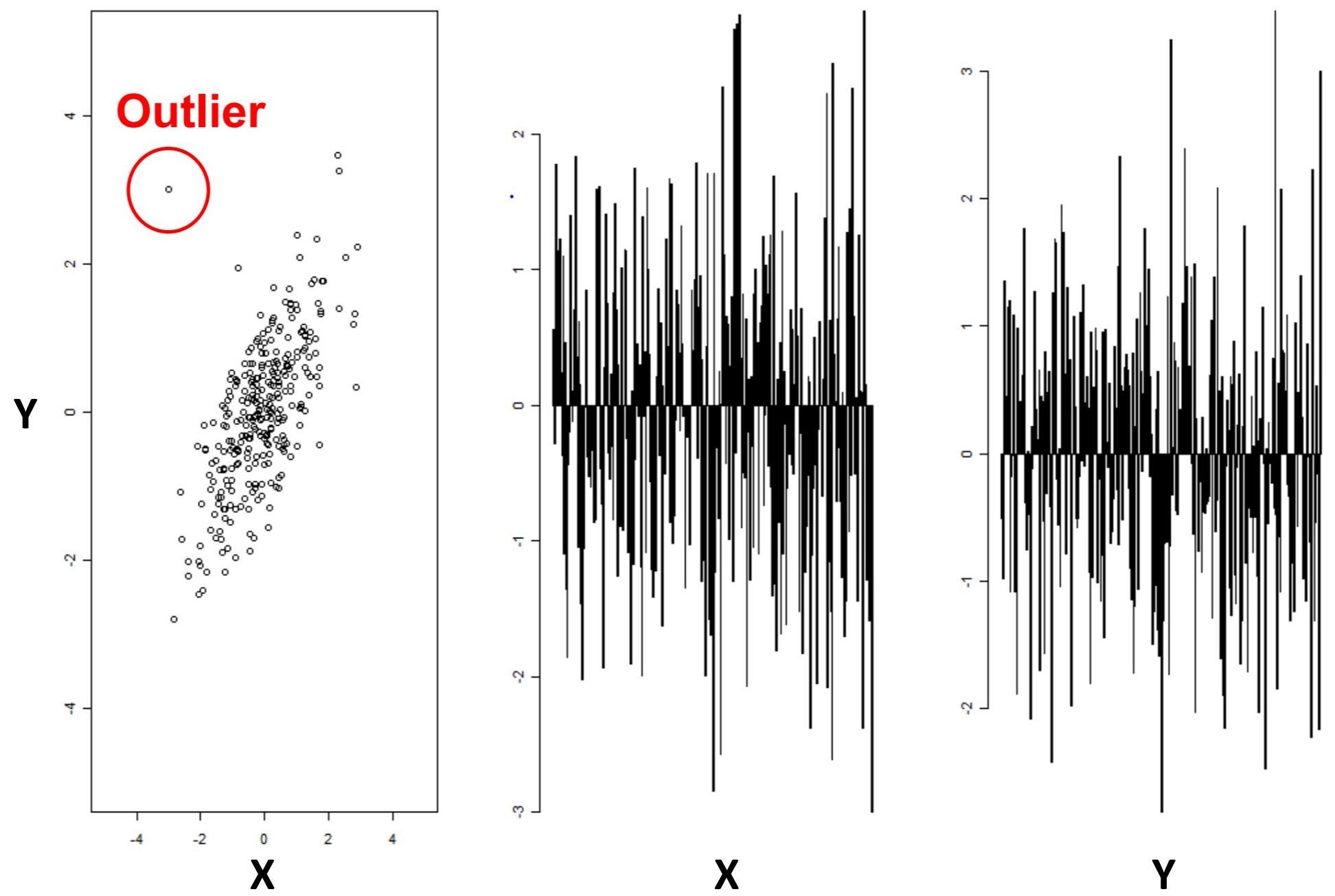
В случае двумерных данных (X и Y) становится довольно легко визуально идентифицировать аномалии по точкам данных, расположенным за пределами типичного распределения. Однако, глядя на цифры справа, невозможно определить выброс непосредственно из исследования одной переменной за раз: именно комбинация переменных X и Y позволяет нам легко идентифицировать аномалия. Это существенно усложняет задачу, когда мы увеличиваем масштаб от двух переменных до 10–100 переменных, что часто имеет место в практических приложениях обнаружения аномалий.
Подключение к мониторингу состояния
Любая машина, будь то вращающаяся машина (насос, компрессор, газовая или паровая турбина и т. Д.) Или невращающаяся машина (теплообменник, дистилляционная колонна, клапан и т. Д.), В конечном итоге выйдет из строя. Это может быть не момент фактического отказа или останова, а момент, когда оборудование больше не работает в своем оптимальном состоянии. Это сигнализирует о том, что может потребоваться некоторое техническое обслуживание для восстановления полного рабочего потенциала. Проще говоря, определение состояния работоспособности нашего оборудования - это область мониторинга состояния.
Самый распространенный способ выполнить мониторинг состояния - это посмотреть на каждое измерение датчика от машины и наложить на него минимальный и максимальный предел значений. Если текущее значение находится в допустимых пределах, значит, машина исправна. Если текущее значение выходит за допустимые пределы, значит, машина неисправна и отправляется сигнал тревоги.
Известно, что эта процедура наложения жестко запрограммированных пределов сигналов тревоги отправляет большое количество ложных сигналов тревоги, то есть сигналов тревоги для ситуаций, которые фактически являются исправными состояниями для машины. Также отсутствуют аварийные сигналы, то есть ситуации, которые являются проблемными, но не тревожными. Первая проблема - это не только потеря времени и сил, но и доступность оборудования. Вторая проблема более важна, так как приводит к реальным повреждениям с соответствующими затратами на ремонт и производственными потерями.
Обе проблемы возникают по одной и той же причине: о работоспособности сложного оборудования нельзя достоверно судить на основе анализа каждого измерения отдельно (как также показано на рисунке 1 в приведенном выше разделе, посвященном обнаружению аномалий). Лучше рассмотреть комбинацию различных измерений, чтобы получить истинное представление о ситуации.
Технический раздел:
Трудно охватить темы машинного обучения и статистического анализа для обнаружения аномалий, не вдаваясь в некоторые из более технических аспектов. Я все же не буду слишком углубляться в теоретические основы (но предоставлю несколько ссылок на более подробные описания). Если вас больше интересуют практические применения машинного обучения и статистического анализа, например, мониторинг состояния, смело переходите к разделу «Сценарий использования мониторинга состояния».
Подход 1: многомерный статистический анализ
Уменьшение размерности с помощью анализа главных компонентов: PCA
Поскольку работа с данными большой размерности часто является сложной задачей, существует несколько методов уменьшения количества переменных (уменьшение размерности). Одним из основных методов является анализ главных компонентов (PCA), который выполняет линейное отображение данных в пространство меньшей размерности таким образом, чтобы дисперсия данных в представлении низкой размерности была максимальной. На практике строится ковариационная матрица данных и вычисляются собственные векторы этой матрицы. Собственные векторы, соответствующие наибольшим собственным значениям (главные компоненты), теперь можно использовать для восстановления значительной части дисперсии исходных данных. Исходное пространство функций теперь уменьшено (с некоторой потерей данных, но, надеюсь, с сохранением наиболее важной вариации) до пространства, охватываемого несколькими собственными векторами.
Обнаружение многомерной аномалии
Как мы отметили выше, для выявления аномалий при работе с одной или двумя переменными визуализация данных часто может быть хорошей отправной точкой. Однако при масштабировании этого до данных большой размерности (что часто имеет место в практических приложениях) этот подход становится все более трудным. К счастью, здесь на помощь приходит многомерная статистика.
При работе с набором точек данных они обычно имеют определенное распределение (например, распределение Гаусса). Чтобы обнаружить аномалии более количественно, мы сначала вычисляем распределение вероятностей p (x) по точкам данных. Затем, когда появляется новый пример, x,, мы сравниваем p (x) с пороговым значением r. Если p (x) ‹r, это считается аномалией. Это связано с тем, что нормальные примеры обычно имеют большой p (x), а аномальные - маленькие p (x).
В контексте мониторинга состояния это интересно, потому что аномалии могут сказать нам кое-что о «состоянии работоспособности» контролируемого оборудования: данные, генерируемые, когда оборудование приближается к отказу или неоптимальной работе, обычно имеют другое распределение, чем данные из «Здоровое» оборудование.
Расстояние Махаланобиса
Рассмотрим проблему оценки вероятности того, что точка данных принадлежит распределению, как описано выше. Нашим первым шагом было бы найти центроид или центр масс точек выборки. Интуитивно понятно, что чем ближе рассматриваемая точка к этому центру масс, тем больше вероятность, что она принадлежит множеству. Однако нам также необходимо знать, распространяется ли набор на большой или малый диапазон, чтобы мы могли решить, заслуживает внимания данное расстояние от центра или нет. Упрощенный подход заключается в оценке стандартного отклонения расстояний между точками выборки от центра масс. Подключив это к нормальному распределению, мы можем получить вероятность того, что точка данных принадлежит одному и тому же распределению.
Недостатком описанного выше подхода было то, что мы предположили, что точки выборки распределены вокруг центра масс сферически. Если бы распределение было явно несферическим, например эллипсоидальным, то можно было бы ожидать, что вероятность того, что контрольная точка принадлежит набору, будет зависеть не только от расстояния от центра масс, но и от направления. В тех направлениях, где эллипсоид имеет короткую ось, контрольная точка должна быть ближе, а в тех, где ось длинная, контрольная точка может быть дальше от центра. Рассматривая это на математической основе, эллипсоид, который лучше всего представляет распределение вероятностей набора, можно оценить, вычислив ковариационную матрицу выборок. Расстояние Махаланобиса (MD) - это расстояние от тестовой точки до центра масс, деленное на ширину эллипсоида в направлении тестовой точки.
Чтобы использовать MD для классификации контрольной точки как принадлежащей к одному из N классов, сначала оценивается ковариационная матрица каждого класса, обычно на основе выборок, принадлежащих каждому классу. В нашем случае, поскольку нас интересует только классификация «нормального» и «аномального», мы используем обучающие данные, которые содержат только нормальные рабочие условия, для вычисления ковариационной матрицы. Затем, учитывая тестовый образец, мы вычисляем MD до «нормального» класса и классифицируем тестовую точку как «аномалию», если расстояние превышает определенный порог.
Предупреждение: использование MD подразумевает, что вывод может быть сделан с помощью матрицы среднего и ковариации, а это свойство только нормального распределения. В нашем случае этот критерий не обязательно выполняется, так как входные переменные могут не иметь нормального распределения. Однако мы все равно попробуем и посмотрим, насколько хорошо это работает!
Подход 2: искусственная нейронная сеть
Сети автоэнкодеров
Второй подход основан на использовании нейронных сетей автокодировщика. Он основан на тех же принципах, что и приведенный выше статистический анализ, но с некоторыми небольшими отличиями.
Автоэнкодер - это разновидность искусственной нейронной сети, используемой для обучения эффективному кодированию данных неконтролируемым способом. Задача автоэнкодера - изучить представление (кодировку) набора данных, как правило, для уменьшения размерности. Наряду со стороной сокращения изучается сторона восстановления, когда автоэнкодер пытается сгенерировать из сокращенного кодирования представление, максимально близкое к его исходному вводу.
Архитектурно простейшая форма автокодировщика - это нерекуррентная нейронная сеть с прямой связью, очень похожая на множество однослойных перцептронов, образующих многослойный перцептрон (MLP) - имеющий входной слой, выходной слой и один или несколько скрытых слоев, соединяющих их, но с таким же количеством узлов выходного слоя, что и входной, и с целью реконструкции собственных входных данных.
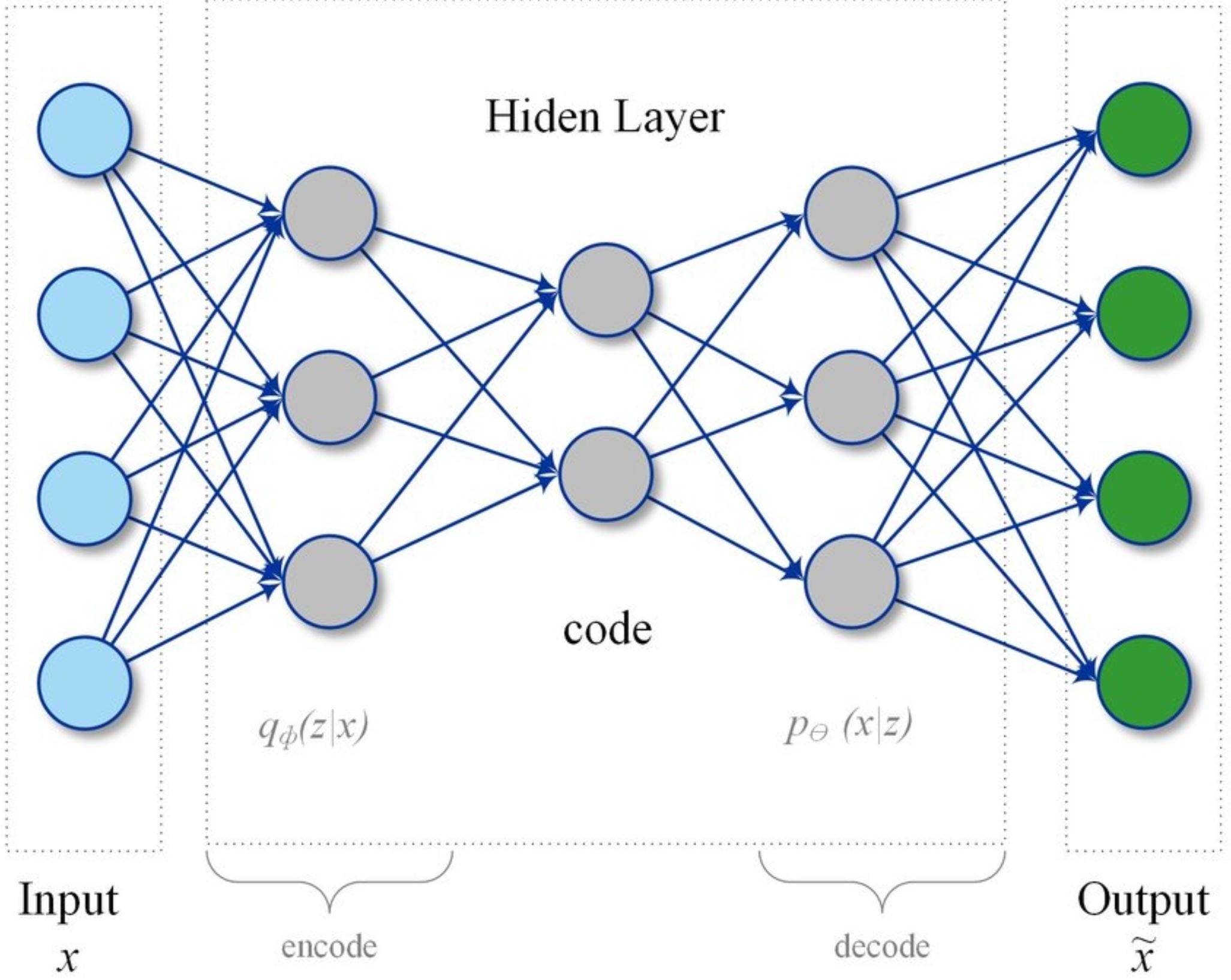
В контексте обнаружения аномалий и мониторинга состояния основная идея состоит в том, чтобы использовать сеть автокодировщика для сжатия показаний датчика до представления более низкого измерения, которое фиксирует корреляции и взаимодействия между различными переменными. (По сути тот же принцип, что и модель PCA, но здесь мы также допускаем нелинейные взаимодействия между переменными).
Затем сеть автокодировщика обучается на данных, представляющих нормальное рабочее состояние, с целью сначала сжатия, а затем восстановления входных переменных. Во время уменьшения размерности сеть изучает взаимодействия между различными переменными и должна иметь возможность восстанавливать их обратно к исходным переменным на выходе. Основная идея заключается в том, что по мере того, как контролируемое оборудование ухудшается, это должно влиять на взаимодействие между переменными (например, изменения температуры, давления, вибрации и т. Д.). Когда это произойдет, вы начнете видеть увеличивающуюся ошибку в восстановлении сети входных переменных. Отслеживая ошибку реконструкции, можно, таким образом, получить индикацию работоспособности контролируемого оборудования, поскольку эта ошибка будет увеличиваться по мере того, как оборудование деградирует. Подобно первому подходу с использованием расстояния Махаланобиса, здесь мы используем распределение вероятностей ошибки реконструкции, чтобы определить, является ли точка данных нормальной или аномальной.
Сценарий использования мониторинга состояния: отказ подшипника зубчатой передачи
В этом разделе я рассмотрю практический пример использования мониторинга состояния с использованием двух разных подходов, описанных выше. Поскольку большая часть данных, над которыми мы работаем с нашими клиентами, не являются общедоступными, я решил скорее продемонстрировать два подхода к данным, предоставленным НАСА, которые можно скачать ЗДЕСЬ.
Для этого варианта использования цель состоит в том, чтобы обнаружить деградацию подшипника зубчатой передачи на двигателе и выдать предупреждение, которое позволяет принять прогнозные меры, чтобы избежать отказа шестерни (что может быть, например, плановым обслуживанием / ремонтом оборудование).
Детали эксперимента и подготовка данных:
Три набора данных, каждый из которых состоит из четырех подшипников, были доведены до отказа при постоянной нагрузке и рабочих условиях. Сигналы измерения вибрации предоставляются для наборов данных на протяжении всего срока службы подшипников до отказа. Отказ произошел после 100 миллионов циклов с трещиной во внешней обойме (см. Документ readme на странице загрузки для получения дополнительной информации об экспериментах). Поскольку оборудование работало до отказа, данные за первые два дня работы использовались в качестве обучающих данных для представления нормального и «исправного» оборудования. Оставшаяся часть наборов данных за время, приведшее к отказу подшипника, была затем использована в качестве данных испытаний, чтобы оценить, могут ли различные методы обнаружить ухудшение характеристик подшипника до отказа.
Подход 1: PCA + расстояние Махаланобиса
Как более подробно объясняется в Техническом разделе этой статьи, первый подход заключался в том, чтобы сначала выполнить анализ главных компонентов, а затем вычислить расстояние Махаланобиса (MD) для определения точек данных как нормальных или аномальных (знак деградации оборудования). Распределение MD для тренировочных данных, представляющих здоровое оборудование, показано на рисунке ниже.

Используя распределение MD для «здорового» оборудования, мы можем определить пороговое значение, которое следует рассматривать как аномалию. Из приведенного выше распределения мы можем, например, определить MD ›3 как аномалию. Оценка этого метода для обнаружения деградации оборудования теперь состоит из расчета MD для всех точек данных в тестовом наборе и сравнения его с определенным пороговым значением для обозначения его как аномалии.
Оценка модели на тестовых данных:
Используя описанный выше подход, мы рассчитали MD для данных испытаний за период времени, приведший к отказу подшипника, как показано на рисунке ниже.

На приведенном выше рисунке зеленые точки соответствуют вычисленным MD, а красная линия представляет определенное пороговое значение для отметки аномалии. Выход из строя подшипника происходит в конце набора данных, он обозначен черной пунктирной линией. Это показывает, что первый подход к моделированию позволил обнаружить предстоящий отказ оборудования примерно за 3 дня до фактического отказа (когда MD пересекает пороговое значение).
Теперь мы можем выполнить аналогичное упражнение, используя второй подход к моделированию, чтобы оценить, какой из методов работает лучше, чем другой.
Подход 2: искусственная нейронная сеть
Как более подробно объясняется в Техническом разделе статьи, второй подход заключался в использовании нейронной сети автокодировщика для поиска аномалий (выявленных по увеличению потерь восстановления в сети). Подобно первому подходу, здесь мы также используем распределение выходных данных модели для обучающих данных, представляющих исправное оборудование, для обнаружения аномалий. Распределение потерь восстановления (средняя абсолютная ошибка) для обучающих данных показано на рисунке ниже:

Используя распределение потерь при реконструкции для «здорового» оборудования, теперь мы можем определить пороговое значение, которое следует рассматривать как аномалию. Из приведенного выше распределения мы можем, например, определить потерю ›0,25 как аномалию. Оценка метода обнаружения деградации оборудования теперь состоит из расчета потерь при реконструкции для всех точек данных в тестовом наборе и сравнения потерь с определенным пороговым значением для обозначения этого как аномалии.
Оценка модели на тестовых данных:
Используя описанный выше подход, мы рассчитываем потери при реконструкции для тестовых данных за период времени, приведший к отказу подшипника, как показано на рисунке ниже.

На приведенном выше рисунке синие точки соответствуют потерям при реконструкции, а красная линия представляет определенное пороговое значение для отметки аномалии. Выход из строя подшипника происходит в конце набора данных, он обозначен черной пунктирной линией. Это показывает, что этот подход к моделированию также позволил обнаружить предстоящий отказ оборудования примерно за 3 дня до фактического отказа (когда потери при реконструкции пересекают пороговое значение).
Сводка результатов:
Как видно из приведенных выше разделов, посвященных двум различным подходам к обнаружению аномалий, оба метода позволяют успешно обнаруживать предстоящий отказ оборудования за несколько дней до фактического отказа. В реальном сценарии это позволит принять меры прогнозирования (техническое обслуживание / ремонт) до отказа, что означает как экономию затрат, так и потенциальную важность аспектов отказа оборудования HSE.
Перспективы:
Благодаря снижению стоимости сбора данных с помощью датчиков, а также расширению возможностей подключения между устройствами, возможность извлекать ценную информацию из данных становится все более важной. Поиск закономерностей в больших объемах данных - это область машинного обучения и статистики, и, на мой взгляд, есть огромные возможности использовать информацию, скрытую в этих данных, для повышения производительности в нескольких различных областях. Обнаружение аномалий и мониторинг состояния, о которых говорится в этой статье, - лишь одна из многих возможностей. (Статья также доступна ЗДЕСЬ)
Я считаю, что в будущем машинное обучение будет использоваться гораздо больше, чем мы даже можем себе представить сегодня. Как вы думаете, какое влияние это окажет на различные отрасли? Я хотел бы услышать ваши мысли в комментариях ниже.
Изменить: Эта статья об обнаружении аномалий и мониторинге состояния получила много отзывов. Многие из вопросов, которые я получаю, касаются технических аспектов и того, как настроить модели и т. Д. В связи с этим я решил написать последующую статью, в которой подробно описаны все необходимые шаги, от предварительной обработки данных до построения моделей. и визуализация результатов .
Если вам интересно узнать больше о темах, связанных с искусственным интеллектом / машинным обучением и наукой о данных, вы также можете ознакомиться с некоторыми другими статьями, которые я написал. Все они перечислены в моем среднем профиле автора, который вы можете найти здесь.
И, если вы хотите стать средним участником для свободного доступа ко всем материалам на платформе, вы также можете сделать это, используя мою реферальную ссылку ниже. (Примечание: если вы зарегистрируетесь по этой ссылке, я также получу часть членского взноса)
Другие работы Вегарда Фловика на Medium:
- Переход от физики к науке о данных
- Что такое теория графов и почему вам это нужно?
- Глубокое трансферное обучение для классификации изображений
- Создание ИИ, который может читать ваши мысли
- Машинное обучение: от шумихи до реальных приложений
- Скрытый риск ИИ и больших данных
- AI для управления цепочками поставок: предиктивная аналитика и прогнозирование спроса
- Как (не) использовать машинное обучение для прогнозирования временных рядов: как избежать ловушек
- Как использовать машинное обучение для оптимизации производства: использование данных для повышения производительности
- Как научить физику системам искусственного интеллекта?
- Можем ли мы построить сети искусственного мозга, используя наномасштабные магниты?