Полное руководство по системам Google, Azure, IBM, Amazon, SpeechMatics, Kaldi и HTK ASR

Системы автоматического распознавания речи (ASR) становятся все более важной частью взаимодействия человека с машиной. В то же время они все еще слишком дороги, чтобы разрабатывать их с нуля. Компаниям нужно выбирать между использованием облачного API для системы ASR, разработанной техническими гигантами, или игрой с решениями с открытым исходным кодом.
В этом посте мы сравниваем восемь самых популярных систем ASR, чтобы облегчить выбор в соответствии с потребностями вашего проекта и навыками команды. Мы провели наши тесты, чтобы определить коэффициент ошибок по словам (WER) для некоторых перечисленных систем ASR. Мы обещаем обновлять и добавлять любую новую информацию, когда это возможно. Давайте прямо сейчас погрузимся в это.
Коммерческие и открытые системы автоматического распознавания речи (ASR)
Автоматическое распознавание речи (ASR) - это технология идентификации и обработки человеческого голоса с помощью компьютерного оборудования и программных средств. Вы можете использовать его для определения произнесенных слов или подтверждения личности человека. В последние годы ASR стал популярным во многих отраслях в отделах обслуживания клиентов.
Базовые системы ASR распознают отдельные записи, такие как ответы «да» или «нет» и произносимые цифры. Однако более сложные системы ASR поддерживают непрерывную речь и позволяют вводить прямые запросы или ответы, такие как запрос направления проезда или номер телефона конкретного контакта. Современные системы ASR распознают полностью спонтанную речь, которая является естественной, неотрепетированной и содержит незначительные ошибки или маркеры нерешительности.
Однако коммерческие системы предлагают ограниченный доступ к подробным выходным данным модели, включая матрицы внимания, вероятности отдельных слов или символов или выходы промежуточных уровней, а также ограниченную интегрируемость в другое программное обеспечение.
Следовательно, системы ASR, такие как AT&T Watson, Microsoft Azure Speech Service, Google Speech API и Nuance Recognizer (купленные Microsoft в апреле 2021 года), не так уж гибки.
В ответ на эти ограничения появляется больше систем и фреймворков ASR с открытым исходным кодом. Однако растущее число таких систем затрудняет понимание того, какая из них лучше всего соответствует потребностям проекта, которая предлагает полный контроль над процессом, который можно использовать без особых усилий и глубоких знаний в области машинного и глубокого обучения. Итак, давайте раскроем все гайки и болты.
Коммерческие системы ASR
Конечно, коммерческие системы ASR, разработанные такими технологическими гигантами, как Google или Microsoft, обеспечивают наилучшую точность распознавания речи. С другой стороны, они редко предоставляют разработчикам большой контроль над системой, обычно позволяя им расширять словарный запас или произношение, но оставляя алгоритмы нетронутыми.

Google Cloud Speech-to-Text - это сервис, основанный на нейронных сетях с глубоким обучением и предназначенный для приложений голосового поиска или транскрипции речи. В настоящее время это явный лидер среди других сервисов ASR с точки зрения точности и используемых языков.

Языковая поддержка
В настоящее время система распознает 137 языков и варианты с обширным словарным запасом в моделях распознавания по умолчанию, распространенных и поисковых. Вы можете использовать модель по умолчанию для расшифровки любого типа аудио, используя поисковые и командные только для коротких аудиоклипов.
Ввод
Можно напрямую передавать звуковые файлы продолжительностью менее минуты для выполнения так называемого синхронного распознавания речи, когда вы разговариваете с телефоном и получаете ответный текст. Правильный способ сделать это - загрузить его в Google Storage и использовать асинхронный API для более длинных файлов.
Поддерживаемые кодировки аудио: MP3, FLAC, LINEAR16, MULAW, AMR, AMR_WB, OGG_OPUS, SPEEX_WITH_HEADER_BYTE, WEBM_OPUS.
Стоимость
Google предоставляет один бесплатный час обработки звука и 1,44 доллара за час звука.

Модели
Google предлагает четыре готовые модели: по умолчанию, голосовые команды и поиск, телефонные звонки и транскрипция видео. Стандартная модель лучше всего подходит для общего использования, например, для длинного аудио с одним динамиком, а модель Video лучше подходит для транскрибирования нескольких динамиков (и видео). На самом деле новейшая и более дорогая модель Video работает лучше во всех настройках.

Настройка
Пользователь может настроить количество гипотез, возвращаемых ASR, указать язык аудиофайла и включить фильтр для удаления ненормативной лексики из выходного текста. Более того, распознавание речи можно настроить в соответствии с конкретным контекстом, добавив так называемые подсказки - набор слов и фраз, которые могут быть произнесены, например, пользовательские слова и имена, в словарь и в случаях использования голосового управления.
Точность
Франк Дернонкур сообщил, что WER Google составляет 12,1% (чистый набор данных LibriSpeech). Мы также протестировали Google Cloud Speech на образце набора данных LibriSpeech и получили WER для мужского и женского чистого голоса 17,8% и 18,8% соответственно и 32,5% и 25,3% для шумной среды соответственно.

Облачный API Microsoft Azure Speech Services помогает создавать в приложениях функции с поддержкой речи, такие как управление голосовыми командами, диалог пользователя с использованием естественной речи, а также транскрипция и диктовка речи. Speech API является частью Cognitive Services (ранее Project Oxford). В своей базовой модели REST API он не поддерживает промежуточные результаты во время распознавания.

Языковая поддержка
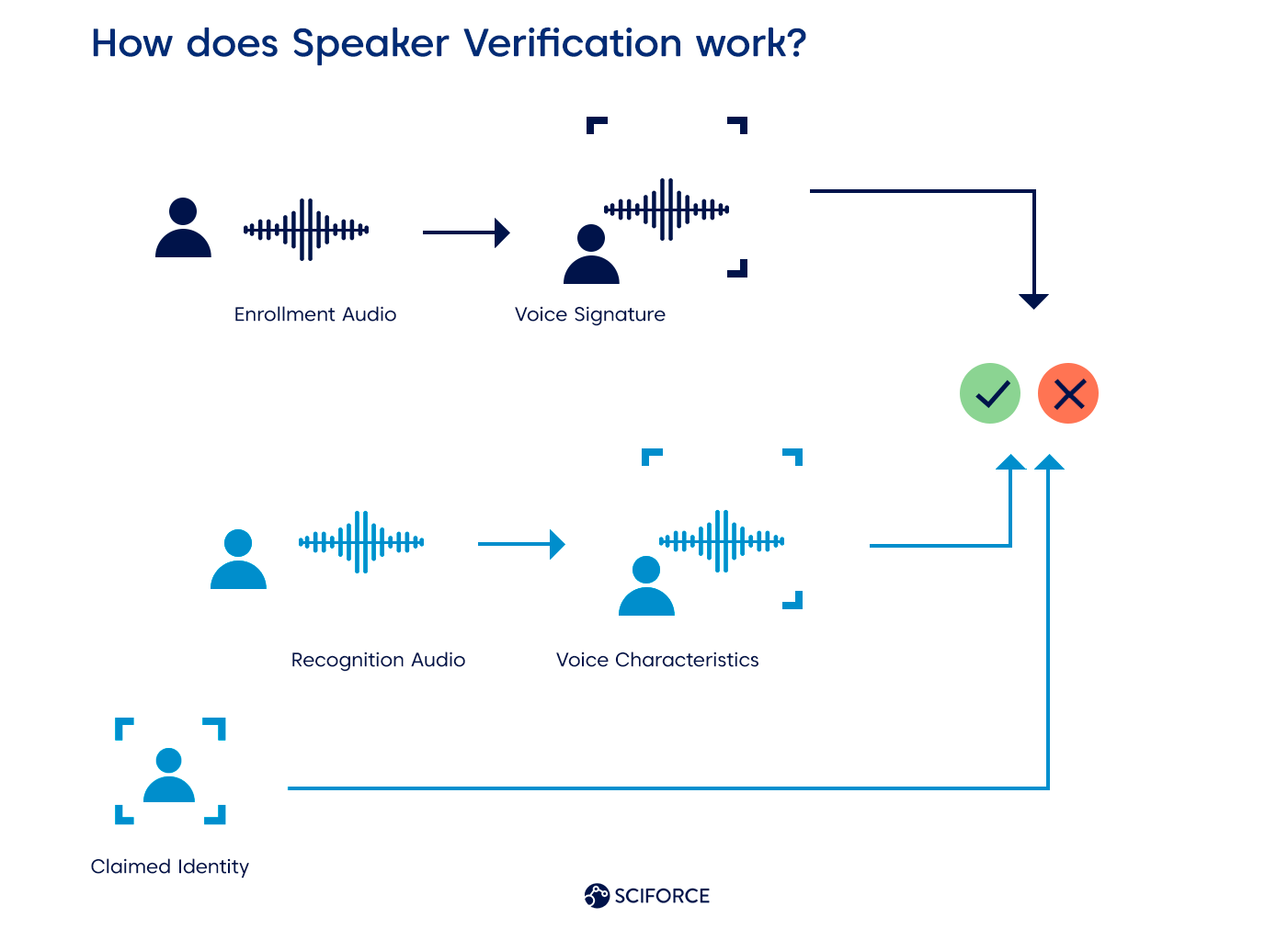
Служба преобразования речи в текст от Microsoft поддерживает 95 языков и региональных вариантов, служба преобразования текста в речь поддерживает 137 языков. Службы преобразования речи и речи в текст поддерживают 71 язык. Распознавание говорящего, сервис, который проверяет и идентифицирует говорящего по его голосовым характеристикам, доступен на 13 языках.
Ввод
REST API поддерживает аудиопотоки продолжительностью до 60 секунд, и вы можете использовать его для онлайн-транскрипции в качестве замены Speech SDK. Для более длинных аудиофайлов следует использовать Speech SDK или преобразование речи в текст REST API v3.0.
Используя Speech SDK, учтите, что формат потокового аудио по умолчанию - WAV (16 кГц или 8 кГц, 16 бит), другие форматы также поддерживаются GStreamer: MP3, OPUS / OGG, FLAC, ALAW в контейнере wav, MULAW в wav контейнер, ЛЮБОЙ (используется для сценария с неизвестным медиаформатом).
Стоимость
Речь в текст - 1 доллар в час.
Преобразование речи в текст с настраиваемой моделью речи - 1,40 доллара в час.
Существует бесплатная версия для одного одновременного запроса с порогом 5 часов в месяц. Более подробную информацию о тарифах можно найти на странице цен здесь.
Интерфейсы
Microsoft предоставляет разработчикам два способа добавить API речевых служб в свои приложения:
- REST APIs: разработчики используют HTTP-вызовы из приложений непосредственно к сервису для распознавания речи.
- Клиентские библиотеки: в качестве опции разработчики могут загрузить клиентские библиотеки Microsoft Speech и связать их со своими приложениями, чтобы получить доступ к расширенным функциям. Клиентские библиотеки используют протокол на основе Websocket и доступны на различных платформах (Windows, Android, iOS) с использованием разных языков (C #, Java, JavaScript, Objective-C).
Настройка
Речевой сервис позволяет пользователям адаптировать базовые модели на основе их акустических и языковых данных, настраивая свой словарный запас, акустические модели и произношение.
На схеме представлены функции Custom Speech by Azure. Источник
Точность
Франк Дернонкур сообщил, что WER Azure составляет 18,8% (чистый набор данных LibriSpeech). Мы также протестировали службу преобразования речи в текст Microsoft на примере набора данных LibriSpeech и получили WER для мужского и женского чистого голоса 11,7% и 13,5% соответственно, а также 26% и 21,3% для шумной среды соответственно.

Amazon Transcribe - это система автоматического распознавания речи, которая, прежде всего, по умолчанию добавляет знаки препинания и форматирование, чтобы вывод был более понятным, и вы могли использовать его без дальнейшего редактирования.

Языковая поддержка
В настоящее время Amazon Transcribe поддерживает 31 язык, включая региональные варианты английского и французского языков.
Ввод
Amazon Transcribe поддерживает аудиопотоки как 16 кГц, так и 8 кГц, а также несколько кодирований звука, включая WAV, MP3, MP4 и FLAC с отметками времени для каждого слова, так что можно, как утверждает Amazon на своем веб-сайте, «легко найти аудио в исходный источник, выполнив поиск по тексту ". Вызов службы ограничен двумя часами на вызов API.
Стоимость
Цены Amazon основаны на ежемесячной оплате транскрибера аудио, начиная с 0 0004 доллара в секунду в течение первых 250 000 минут.
Уровень бесплатного пользования доступен в течение 12 месяцев с ограничением 60 минут в месяц.

Настройка
Amazon Transcribe позволяет создавать индивидуальные словари в принятом формате с использованием символов из разрешенного набора символов для каждого поддерживаемого языка.
Точность
Amazon Transcribe, обладая ограниченным набором языков и доступной только одной базовой моделью, показывает WER 22%.

Служба Watson Speech to Text - это система ASR, которая предоставляет услуги автоматической транскрипции. Система использует машинный интеллект для объединения информации о грамматике и структуре языка со знаниями о составе аудиосигнала для точной расшифровки человеческого голоса. По мере того, как слышно больше речи, система задним числом обновляет транскрипцию.

Языковая поддержка
Служба преобразования текста в текст IBM Watson поддерживает 19 языков и вариантов.
Ввод
Система поддерживает аудиопотоки 16 кГц и 8 кГц в MP3, MPEG, WAV, FLAC, OUPS и других форматах.
Стоимость
IBM предоставляет вам бесплатный тарифный план до 500 минут в месяц (настройка недоступна). Пользователи могут проводить до 100 одновременных транскрипций за 0,02 доллара США за минуту в течение 1–999 999 минут в месяц в рамках плана Plus. Детали для других тарифных планов доступны по запросу.
Интерфейсы
Сервис Watson Speech to Text предлагает три интерфейса:
- Интерфейс WebSocket для постоянного полнодуплексного соединения с сервисом с малой задержкой.
- Синхронный HTTP-интерфейс для базовых HTTP-вызовов службы.
- Асинхронный HTTP-интерфейс для неблокирующего обращения к сервису.
Настройка
Для ограниченного набора языков служба IBM Watson Speech to Text предлагает интерфейс настройки, который позволяет разработчикам расширять свои возможности распознавания речи. Вы можете повысить точность запросов на распознавание речи, настроив базовую модель для таких областей, как медицина, право, информационные технологии и другие. Система позволяет настраивать язык и акустические модели.
Точность
Франк Дернонкур сообщил, что WER Azure составляет 9,8% (чистый набор данных LibriSpeech). Мы также протестировали службу преобразования речи в текст Microsoft на примере набора данных LibriSpeech и получили WER для мужского и женского чистого голоса 17,4% и 19,6% соответственно, а 37,5% и 27,4% для шумной среды. соответственно.

SpeechMatics, как облачная, так и локальная служба HQ-ed в Великобритании, использует повторяющиеся нейронные сети и статистическое языковое моделирование. Сервис, ориентированный на предприятия, предлагает бесплатные и премиальные функции, такие как транскрипция в реальном времени и загрузка аудиофайлов.

Языковая поддержка
Они охватывают 31 язык. SpeechMatics обещает справиться с такими проблемами, как шумная среда, разные акценты и диалекты.
Ввод
Эта система ASR поддерживает следующие аудио- и видеоформаты: WAV, MP3, AAC, OGG, FLAC, WMA, MPEG, AMR, CAF, MP4, MOV, WMV, MPEG, M4V, FLV, MKV. Компания заявляет, что другие форматы также могут поддерживаться, но после дополнительного тестирования пользователя.
Стоимость
Как и большинство компаний, ориентированных на предприятия, SpeechMatics предоставляет подробные планы и цены по запросу. Компания использует стратегию на основе объемов и предоставляет 14-дневную бесплатную пробную версию.
Настройка
Эта система обладает широкими возможностями настройки - вы можете создать свой пользовательский интерфейс в соответствии с вашими потребностями. Пользовательского интерфейса по умолчанию не предусмотрено, но вы можете получить его через одного партнера, когда это необходимо. Вы можете добавить свои слова в словарь и научить движок их распознавать. Вы также можете настроить систему, чтобы исключить конфиденциальную информацию или профанацию. SpeechMatics также поддерживает субтитры в реальном времени.
Точность
Франк Дернонкур протестировал SpeechMatics на чистом наборе данных теста LibriSpeech (английский) - WER 7,3%, что довольно хорошо по сравнению с другими коммерческими системами ASR.
Системы ASR с открытым исходным кодом
Разнообразие систем ASR с открытым исходным кодом затрудняет поиск систем, сочетающих гибкость с приемлемой частотой ошибок по словам. В этом посте мы выбрали Kaldi и HTK как популярные на платформах сообщества.

Kaldi изначально создавался для исследователей, но быстро сделал себе имя. Kaldi - это набор инструментов Университета Джонса Хопкинса для распознавания речи, написанный на C ++ и лицензированный под лицензией Apache License v2.0. Kaldi, известная своими результатами, которые действительно могут конкурировать с Google и даже превосходить их, сложно освоить и настроить для правильной работы, требуя обширной настройки и обучения на вашем корпусе.

Поддержка языков
Kaldi не предоставляет лингвистических ресурсов, необходимых для создания распознавателя на языке, но у него есть рецепт, как создать его самостоятельно. Когда вы предоставите достаточно данных, вы можете обучить свою модель с помощью Kaldi. Вы также можете использовать некоторые готовые модели на странице Kaldi.
Ввод
Аудиофайлы принимаются в формате WAV.
Настройка
Kaldi - это набор инструментов для создания языковых и акустических моделей для самостоятельного создания систем ASR. Он поддерживает линейные преобразования, дискриминантное обучение пространству признаков, глубокие нейронные сети, MMI, усиленное MMI и дискриминативное обучение MCE.
Точность
Мы протестировали Kaldi на выборке набора данных LibriSpeech и получили WER для мужского и женского чистого голоса около 28 %% и 28,1% соответственно, и около 46,7% и 40,2% для шумной среды соответственно.

HTK, или Hidden Markov Model Toolkit, написанный на языке программирования C, был разработан на инженерном факультете Кембриджского университета для работы с HMM. HTK специализируется на распознавании речи, но вы также можете использовать его для задач преобразования текста в речь и даже для секвенирования ДНК.
Сегодня Microsoft получила авторские права на исходный код HTK, но по-прежнему поощряет внесение изменений в исходный код. Интересно, что, будучи одним из старейших проектов, он до сих пор широко используется и выпускает новые версии. Более того, у HTK есть проницательная и подробная книга под названием «HTKBook», в которой описаны как математические основы распознавания речи, так и способы выполнения определенных действий в HTK.

Языковая поддержка
Подобно Kaldi, HTK не зависит от языка, с возможностью создания модели для каждого языка.
Ввод
По умолчанию формат речевого файла - HTK, но инструментарий также поддерживает различные форматы. Вы можете установить параметр конфигурации SOURCEFORMAT для других форматов.
Настройка
Полностью настраиваемый HTK предлагает обучающие инструменты для оценки параметров набора HMM с использованием обучающих высказываний и связанных с ними транскрипций и инструментов распознавания для расшифровки неизвестных высказываний.
Точность
Набор инструментов был оценен с использованием хорошо известной базы данных WSJ Nov ’92. Результат был впечатляющим: 3,2% WER при использовании языковой модели триграмм на корпусе из 5000 слов. Однако в реальной жизни WER достигает 25–30%.
Используя любой набор инструментов ASR с открытым исходным кодом, оптимальным способом быстрой разработки распознавателя ASR было бы использование открытого кода для статей, которые имеют наивысшие результаты на хорошо известных корпусах (Набор инструментов автоматического распознавания речи Facebook AI Research , Реализация модели LAS Tensorflow или библиотека моделей глубокого обучения и наборов данных Tensorflow, и это лишь некоторые из них).
Выводы
Технология автоматического распознавания речи существует уже некоторое время. Хотя системы улучшаются, проблемы все еще существуют. Например, система ASR не всегда может правильно распознать ввод от человека, который говорит с сильным акцентом или диалектом или говорит на нескольких языках.
Существуют различные инструменты, как коммерческие, так и с открытым исходным кодом, для интеграции ASR в приложения компании. При выборе между ними решающим моментом является поиск правильного баланса между обычно более высоким качеством проприетарных систем и гибкостью наборов инструментов с открытым исходным кодом.
Компаниям необходимо понимать свои ресурсы, а также потребности своего бизнеса. Если ASR используется в обычных и хорошо изученных условиях и не требует слишком большого количества дополнительной информации, готовая к использованию система является наиболее оптимальным решением. Напротив, если ASR является ядром проекта, более гибкий набор инструментов с открытым исходным кодом становится лучшим вариантом.