
Мотивация
Как вы думаете, можно ли предсказать цену продукта, используя некоторые метаданные о продукте?
Давайте разберемся!!!

product_name: Kylie Birthday Edition
Категория: Beauty / Makeup / Makeup Sets
brand_name: Kylie Cosmetics
цена: 20 $
доставка: оплачивает продавец
item_description: матовая мини-губная помада Kylie Happy Birthday, набор для губ Kylie Jenner Lip Kit Мини-набор для губной помады Birthday Matte Lipstick, 6 шт. Все 6 включены в цену. СОВЕРШЕННО НОВАЯ НИКОГДА НЕ ОТКРЫВАЛАСЬ 6 мини-помад Leo Kristen Dolce Expos ЦЕНА ТОВАРНАЯ! НЕ БУДЕТ РАЗОЧАРОВАТЬСЯ Доставка через USPS обычно занимает 1-3 дня. Я отправляю в течение 24 часов. 48 часов в неделю

jarvis_say_the_price () - это функция, которая принимает ['name', 'category', 'brand_name', 'shipping', 'item_description']. и спрогнозировал цену с ошибкой или 0,1846
СОДЕРЖАНИЕ
- Бизнес-проблема
- Использование ML / DL
- Метрики
- Существующие подходы
- Улучшения
- EDA
- Описание модели
- Код
- Сравнение моделей
- Скриншот Kaggle
- Будущая работа
- Linkedin, исходный код Git
- использованная литература
1. Бизнес-проблема:
Mercari, крупнейшее приложение для покупок в Японии. Они хотели бы предлагать продавцам предложения по ценам, но это сложно, потому что их продавцы могут размещать что угодно или любой набор товаров на торговой площадке Mercari.
При масштабировании ценообразование на продукты становится еще сложнее, учитывая, сколько продуктов продается в Интернете. Одежда имеет сильные сезонные тенденции ценообразования и в значительной степени зависит от торговых марок, в то время как цены на электронику колеблются в зависимости от характеристик продукта.
Эта формулировка проблемы была загружена на соревнованиях Kaggle. В этом соревновании Mercari предлагает участникам разработать алгоритм, который автоматически предлагает правильные цены на товары.
Предоставляемые данные состоят из введенных пользователем текстовых описаний своих продуктов, включая такие детали, как название категории продукта, название бренда, состояние товара.
2. Использование ML / DL:
Прежде чем использовать модели машинного обучения и глубокого обучения, мы рассмотрим сами данные. Что это за входные данные и что нам нужно предсказать?
Формат входных данных

Вывод
В этом конкурсе мы будем прогнозировать продажную цену листинга на основе информации, которую пользователь предоставляет для этого листинга.
Поскольку это проблема регрессии, у нас есть возможность реализовать широкий спектр моделей от машинного обучения до глубокого обучения.
Модели машинного обучения
- Ридж-Регрессор
- Регрессор SGD
- Регрессор опорных векторов (SVR)
- Регрессор дерева решений
- Ансамбли (штабелирование, голосование)
- СВР
Модели глубокого обучения
- Долговременная краткосрочная память (LSTM)
- Сверточная нейронная сеть (CNN)
- Закрытый рекуррентный блок (ГРУ)
3. Показатели
Метрика оценки для этого соревнования - среднеквадратическая логарифмическая ошибка.
Среднеквадратичная ошибка (RMSE) и среднеквадратичная логарифмическая ошибка (RMSLE) - это методы, позволяющие найти разницу между прогнозируемыми значениями и фактическими значениями.
Важно знать, что означает среднеквадратичная ошибка (MSE). MSE включает в себя как дисперсию, так и систематическую ошибку предсказателя. RMSE - это квадратный корень из MSE. В случае несмещенной оценки RMSE - это просто квадратный корень из дисперсии, который на самом деле является стандартным отклонением.
Но в случае RMSLE мы берем журнал прогнозов и фактических значений. Итак, в основном, что меняется, так это дисперсия, которую мы измеряем. RMSLE используется, когда мы не хотим штрафовать за огромные различия в прогнозируемых и фактических значениях, когда оба эти значения являются огромными.
Устойчивость RMSLE к выбросам, свойство вычисления относительной ошибки между прогнозируемыми и фактическими значениями, наиболее уникальное свойство RMLSE, заключающееся в том, что он более сурово наказывает недооценку фактического значения, чем при завышении.
Среднеквадратичная ошибка УРАВНЕНИЕ
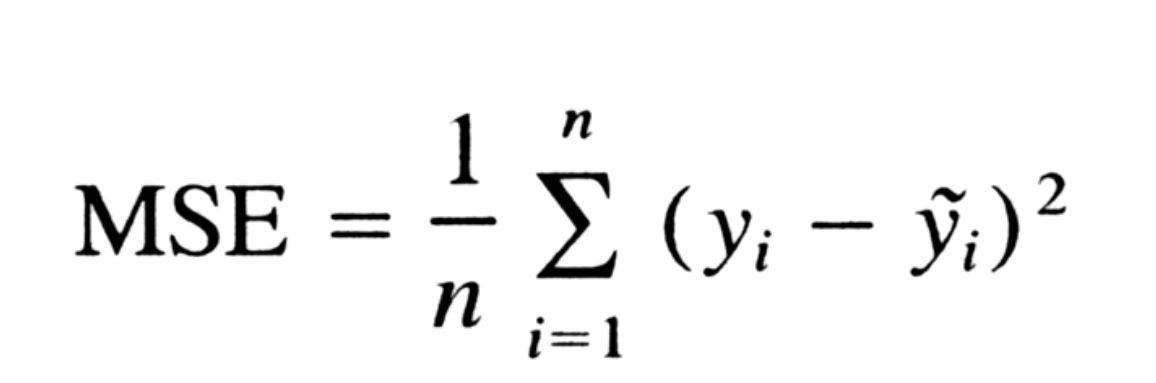
Среднеквадратичная ошибка УРАВНЕНИЕ

Среднеквадратичная логарифмическая ошибка УРАВНЕНИЕ

4. Существующие подходы
a.
Основное внимание уделяется тому, как делать прогнозы для интернет-магазина. Это похоже на стратегию динамического ценообразования. Динамическое ценообразование - это термин, относящийся к поиску оптимальной цены на товары, особенно онлайн-товары. Цель состоит в том, чтобы согласовать цену с характеристиками продукта, такими как спрос и предложение, а также с брендом и качеством. Основная идея - определить лучшую цену, проанализировав характеристики товара. Очевидно, что постановка задачи относится к проблеме регрессии. Среди всех моделей машинного обучения XGBoost - популярная методология машинного обучения, которая добилась успеха в этой области и часто используется в аналитике данных и статистических исследованиях. XGBoost основан на сквозной системе повышения дерева. Он предлагает более быстрый и точный способ решения задач классификации и регрессионного типа. Ключевой особенностью XGBoost является то, что он взвешивает предикторы и пытается уберечь новое дерево решений от ошибок, допущенных предыдущими деревьями решений. Таким образом повышается его точность.
b.
Прежде чем передавать данные в модели, необходимы разработка и предварительная обработка функций. После выполнения функции проектирования и предварительной обработки в данных были обнаружены определенные значимые закономерности. Например, длина описания может содержать некоторую закономерность, влияющую на цену, доставку или данные. Кроме того, после экспериментов с оценкой тональности описания предмета. Было замечено, что положительные настроения будут иметь более высокую цену, чем предмет с отрицательными настроениями.
c.
Объекты ценообразования появляются на большинстве торговых площадок, поэтому интересно узнать, как различные нейронные сети могут сравниваться со статус-кво на таких сайтах, как ebay, craigslist, amazon, и потенциально снижать неэффективность. После передачи данных в разные модели было обнаружено, что уровень lstm, подключенный к трехуровневой полностью подключенной сети, работал хорошо. Архитектура модели представлена на рисунке ниже. Представление Word2vec было выполнено для описания элемента столбца, которое позже было передано на уровень lstm. Выходные данные слоя lstm подавались через три полностью связанных слоя, и выходные данные этого подавались вместе с векторизованными формами состояния элемента, названия категории и названия бренда через еще три полностью связанных слоя, которые выводят либо функцию soft max. или линейная функция.
Было обнаружено три элемента, которые были полезны из литературы. Первый элемент - вложение слов. В литературе приводятся доводы в пользу тренировки векторов word2vec на перчатке, а не в режиме пропуска грамма. Однако, вопреки предыдущему утверждению, были доказательства, подтверждающие пропуск грамма над перчаткой. Поскольку перчатка кажется более распространенной, она широко использовалась. Вторым элементом была разработка архитектуры модели. Поскольку мы решаем более простую задачу анализа текста с короткими описаниями продуктов, LSTM был запущен.
5. Улучшения
Мы пытаемся реализовать некоторые технические приемы, чтобы уменьшить ошибку RMSLE.
а. Функциональная инженерия
Мы индивидуально разбиваем категорию на main_category, sub_category, sub_sub_category.
Получаем длину признаков item_description и name.
В торговых марках отсутствуют значения более 600 000. Мы заполним некоторые из торговых марок. Некоторые из торговых марок на самом деле не являются торговыми марками, а вместо этого являются названиями категорий. Мы стараемся устранить эту проблему.
Мы конвертируем каждую функцию в строковый формат и преобразуем все функции в нижний регистр.
Мы векторизуем функции с помощью sklearn.pipeline.FeatureUnion ()
Векторизация item_description с использованием TFIDFVectorizer (ngram_range = (1,3), max_features = 100000)
б. Настройка гиперпараметров
Форма наших обучающих и тестовых данных после преобразования в векторы:
Поезд: (1432350, 222408) Тест: (14469, 222408)
Поскольку форма как обучающих, так и тестовых данных велика, реализация GridSearchCV требует больших вычислительных ресурсов. Вместо этого мы реализуем простой цикл for для перебора и настройки параметров.
c. Экспериментируйте с ансамблями.
Мы выполняем ансамблевые методы на моделях, которые обеспечивают оптимальную RMSLE. Для реализации ансамблей мы используем Регрессор голосования и Регрессор стекирования.
d. Внедрение различных сетей глубокого обучения
Мы реализуем Lstm’s, Cnn’s, Gru индивидуально, а также вместе. Поскольку текстового описания очень мало, идеально использовать Lstm’s или Gru. Мы также можем поэкспериментировать с 1D Cnn’s.
6. Исследовательский анализ данных
а. Проверка значений NULL в данных.


category_name, brand_name, item_description имеет значения NaN.
Мы заполним недостающие значения, запустив следующий фрагмент кода.
- ›project_data.category_name.fillna (значение =« другие », inplace = True)
- ›project_data.brand_name.fillna (value =« Неизвестный бренд », inplace = True)
- ›project_data.item_description.fillna (значение =« другие », inplace = True)
б. Название категории
Сначала мы разделяем имя_категории на основную категорию, подкатегорию и подкатегорию.
Пример: Женщины → Спортивная одежда → Штаны для йоги Night Run.
Основная категория = «Женщины», подкатегория = «Спортивная одежда», подкатегория = «Штаны для йоги для ночного бега».



Наблюдение: мы видим, что большинство категорий принадлежат женщинам, за которыми следуют подкатегории и подкатегории.
И мужчины, и женщины носят спортивную одежду, но, поскольку рекордов женщин становится все больше, спортивная одежда занимает первое место в графике подкатегорий. Макияж занимает второе место после спортивной одежды, которая также относится к женской категории.
Штаны, леггинсы, колготки тоже относятся к женской категории.
Вывод из приведенного выше графика показывает, что большинство товаров относятся к категории женщин.
c. Название бренда

Наблюдение: набор данных содержит большое количество неизвестных брендов.
Продукция таких брендов, как Pink, Nike, Victoria’s secret, принадлежит к брендам Women’s Bran.
d. Цена


Наблюдение: большинство товаров находится в диапазоне от 10 до 30 долларов.
е. Перевозки

Распределение цен в зависимости от доставки

Наблюдение: большую часть стоимости доставки оплачивают Продавцы.
Стоимость доставки недорогой продукции оплачивается покупателем. Дорогие товары взимаются продавцом.
Понятно, что большинство веб-сайтов электронной коммерции выставляют определенную сумму в качестве порогового значения, чтобы решить, будет ли стоимость доставки оплачена продавцом или покупателем. Обычно товары, которые стоят меньше, заставляют покупателей платить за доставку.
f. описание предмета


Наблюдение: из Wordcloud мы видим, что в большинстве описаний продуктов используются такие ключевые слова, как Бесплатная доставка, Совершенно новый, Никогда не носили, Никогда не использовали, Отличное состояние.
7. Описание модели
а. RidgeCv против Ridge
Перекрестная проверка - это рандомизированная процедура. Вы случайным образом назначаете выборки одной из kk кратностей, а затем оцениваете статистику ошибок обычным способом перекрестной проверки kk кратностей. В зависимости от того, какие образцы находятся в какой складке, вы получите разные оценки параметров и, следовательно, разные прогнозы. Результаты в RidgeCv могут различаться при каждом подборе.


б. Ансамбль
Ансамблевое обучение использует несколько моделей машинного обучения, чтобы попытаться сделать более точные прогнозы для набора данных. Модель ансамбля работает путем обучения различных моделей на наборе данных, и каждая модель делает прогнозы индивидуально. Прогнозы этих моделей затем объединяются в ансамблевую модель, чтобы сделать окончательный прогноз. У каждой модели есть свои сильные и слабые стороны. Ансамблевые модели могут быть полезны, если комбинировать отдельные модели, чтобы скрыть слабые места отдельной модели.

c. Модели DL
Перед тем, как перейти к моделям, нам нужно выполнить кодирование меток для текстовых объектов. У тестовых данных могут быть ярлыки, которых нет в данных поезда. Чтобы решить эту проблему, мы определяем наш собственный LabelEncoder ().
Самый большой вопрос: следует ли использовать RNN, CNN или гибридные модели для задачи регрессии, зависит от типа данных и проблемы. Поскольку у нас есть короткие текстовые данные, LSTM и ГРУ будут эффективны.
Я экспериментировал с LSTM и CNN, а также с ГРУ. Ошибка RMSLE показала уменьшение 0,02, т.е. уменьшилась с 0,44 до 0,42. Но когда я объединил 2x LSTM с 4x CNN, RMSLE уменьшился еще на 0,01, то есть RMSLE ERROR = 0,41.
8. Код
Некоторые фрагменты кода для служебных функций показаны ниже.
RMSLE

Торговые марки начинки

Feature Union

Кодировщик специальных меток

9. Сравнение моделей.
Баллы для всех моделей оценивались на основе данных теста 1 этапа.
Красивая таблица для моделей машинного обучения

Красивая таблица для моделей глубокого обучения

10. Скриншот Kaggle:
Окончательная оценка подачи была оценена на тестовых данных этапа 2, которые состоят из 3,5 M строк.

11. Будущая работа
Мы можем использовать несколько методов проектирования функций, чтобы еще больше снизить оценку.
Например, мы можем реализовать Расстояние Дамерау Левенштейна для наших текстовых данных и посмотреть, уменьшится ли ошибка.
Мы также можем уменьшить ошибку, заполнив недостающие значения соответствующими данными. И вместо использования императивного объявления для векторизации мы можем построить пипллайн. Мы можем сделать ствол, лук с (1,2 грамма с TFIDF и без).
Мы также можем реализовать более глубокую нейронную сеть с лучшей архитектурой и настройкой гиперпараметров.
Мы также можем реализовать многослойный перцептрон, поскольку он хорошо обрабатывает короткие текстовые данные и категориальные функции.
Чтобы получить полный код, ознакомьтесь с моей ссылкой на github
Профиль в Linkedin
12. Ссылки
Https://www.appliedaicourse.com/
Https://towardsdatascience.com/hacking-scikit-learns-vectorizers-9ef26a7170af
Https://stackoverflow.com/a/56876351