
Эта статья изначально была написана Камилем Качмареком и размещена в блоге Neptune.
На прошлой неделе я имел удовольствие принять участие в Международной конференции по представлениям обучения (ICLR), мероприятии, посвященном исследованиям всех аспектов глубокого обучения. Изначально конференция должна была пройти в Аддис-Абебе, Эфиопия, однако из-за пандемии нового коронавируса она стала виртуальной. Я уверен, что организаторам было непросто перенести мероприятие в онлайн, но я думаю, что эффект был более чем удовлетворительным, так как вы можете читать здесь!
Более 1300 спикеров и 5600 участников доказали, что виртуальный формат был более доступным для публики, но при этом конференция оставалась интерактивной и увлекательной. Из множества интересных презентаций я решил выбрать 16 влиятельных и наводящих на размышления. Вот лучшие документы по глубокому обучению от ICLR.
Лучшие работы по глубокому обучению
1. О робастности нейронных обыкновенных дифференциальных уравнений.
Углубленное изучение надежности нейронных обыкновенных дифференциальных уравнений или NeuralODE. Используйте его в качестве строительного блока для более надежных сетей.
"Бумага"

Архитектура ODENet. Нейронный блок ODE служит сохраняющим размерность нелинейным отображением.

Первый автор: Ханьшу ЯН
ЛинкедИн | "Веб-сайт"
2. Почему отсечение градиента ускоряет обучение: теоретическое обоснование адаптивности
Отсечение градиента доказуемо ускоряет градиентный спуск для негладких невыпуклых функций.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Норма градиента по сравнению с константой Липшица локального градиента в логарифмической шкале вдоль траектории обучения для AWD-LSTM (Merity et al., 2018) в наборе данных PTB. Цветная полоса указывает количество итераций во время обучения.
Первый автор: Цзинчжао Чжан
ЛинкедИн | "Веб-сайт"
3. Целевое встраивание автоэнкодеров для контролируемого обучения представлению
Новая общая структура автокодировщиков с целевым встраиванием или TEA для прогнозирования с учителем. Авторы приводят как теоретические, так и эмпирические соображения.
"Бумага"

(a) автокодировщики с встраиванием признаков и (b) с целевым встраиванием. Сплошные линии соответствуют (основной) задаче прогнозирования; пунктирные линии к (вспомогательной) задаче реконструкции. В обоих участвуют общие компоненты.

Первый автор: Дэниел Джарретт
4. Понимание и надежность поиска дифференцируемой архитектуры
Мы изучаем режимы отказа DARTS (поиск дифференциальной архитектуры), просматривая собственные значения гессиана потерь при проверке относительно. архитектуру и предложить робастификации на основе нашего анализа.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Плохие ячейки стандарта DARTS находит на ячейках S1-S4. Для всех пробелов DARTS выбирает в основном операции без параметров (пропустить соединение) или даже опасную операцию Noise. Показаны нормальные клетки на CIFAR-10.

Первый автор: Арбер Зела
5. Сравнение перемотки и тонкой настройки в сокращении нейронной сети
Вместо точной настройки после обрезки перемотайте веса или график скорости обучения к их значениям, которые были ранее в процессе обучения, и переобучите их, чтобы добиться более высокой точности при обрезке нейронных сетей.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Наилучшая достижимая точность во время переобучения за счет однократного сокращения.

Первый автор: Алекс Ренда
Твиттер| ЛинкедИн | Гитхаб| "Веб-сайт"
6. Нейронные арифметические устройства
Нейронные сети, хотя и способны аппроксимировать сложные функции, довольно бедны в точных арифметических операциях. Эта задача была давней проблемой для исследователей глубокого обучения. Здесь представлены новые нейронные блоки сложения (NAU) и нейронные блоки умножения (NMU), способные выполнять точное сложение/вычитание (NAU) и умножать подмножества вектора (MNU). Известный первый автор - независимый исследователь.
Бумага | "Код"

Визуализация NMU, где веса (Wi,j) управляют гейтированием между 1 (идентичностью) или xi, каждый промежуточный результат затем явно умножается для формирования zj.

Первый автор: Андреас Мэдсен
7. Точка безубыточности траекторий оптимизации глубоких нейронных сетей
На ранней стадии обучения глубоких нейронных сетей существует «точка безубыточности», которая определяет свойства всей траектории оптимизации.
(TL;DR, из OpenReview.net)
"Бумага"

Визуализация ранней части траекторий обучения на CIFAR-10 (до достижения 65% точности обучения) простой модели CNN, оптимизированной с использованием SGD, со скоростями обучения η = 0,01 (красный) и η = 0,001 (синий). Каждая модель на траектории обучения, показанная в виде точки, представлена своими тестовыми прогнозами, встроенными в двумерное пространство с помощью UMAP. Цвет фона указывает спектральную норму ковариации градиентов K (λ1K, слева) и точность обучения (справа). Для более низкого η после достижения того, что мы называем точкой безубыточности, траектория направляется в сторону области, характеризующейся большим λ1K (слева) при той же точности обучения (справа).

Первый автор: Станислав Ястшембский
8. Hoppity: изучение преобразований графов для обнаружения и исправления ошибок в программах
Основанный на обучении подход к обнаружению и исправлению ошибок в Javascript.
(TL;DR, из OpenReview.net)
"Бумага"

Примеры программ, которые иллюстрируют ограничения существующих подходов, включая статические анализаторы на основе правил и предикторы ошибок на основе нейронных сетей.

Первый автор: Элизабет Динелла
9. Выбор через прокси: эффективный выбор данных для глубокого обучения
Мы можем значительно повысить вычислительную эффективность выбора данных в глубоком обучении, используя гораздо меньшую прокси-модель для выполнения выбора данных.
(TL;DR, из OpenReview.net)
Бумага | "Код"

SVP применяется к активному обучению (слева) и выбору основного набора (справа). При активном обучении мы использовали ту же итеративную процедуру обучения и выбора точек для маркировки, что и традиционные подходы, но заменили целевую модель более дешевой прокси-моделью. Для выбора основного набора мы изучили представление признаков данных с помощью прокси-модели и использовали ее для выбора точек для обучения более крупной и точной модели. В обоих случаях мы обнаружили, что прокси-модель и целевая модель имеют высокую ранговую корреляцию, что приводит к схожим выборам и последующим результатам.

Первый автор: Коди Коулман
Твиттер| ЛинкедИн| Гитхаб| "Веб-сайт"
10. И бит идет вниз: пересмотр квантования нейронных сетей
Использование метода структурированного квантования, направленного на лучшую реконструкцию в домене для сжатия сверточных нейронных сетей.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Иллюстрация нашего метода. Мы аппроксимируем бинарный классификатор ϕ, который помечает изображения как собак или кошек, путем квантования его весов. Стандартный метод: квантование ϕ со стандартной целевой функцией (1) продвигает классификатор ϕbstandard, который пытается аппроксимировать ϕ по всему входному пространству и, таким образом, может плохо работать для входных данных в предметной области. Наш метод: квантование ϕ с нашей целевой функцией (2) продвигает классификатор ϕbactivations, который хорошо работает для входных данных в предметной области. Изображения, лежащие в заштрихованной области входного пространства, правильно классифицируются по ϕактивациям, но неправильно по ϕстандарту.

Первый автор: Пьер Сток
11. Перспектива распространения сигнала для обрезки нейронных сетей при инициализации
Мы формально характеризуем условия инициализации для эффективного сокращения при инициализации и анализируем свойства распространения сигнала полученных сокращенных сетей, что приводит к методу повышения их обучаемости и результатов сокращения.
(TL;DR, из OpenReview.net)
"Бумага"

(слева) послойные шаблоны разреженности c ∈ {0, 1} 100×100, полученные в результате обрезки для уровня разреженности κ¯ = {10, .., 90}%. Здесь черные (0)/белые (1) пиксели относятся к сокращенным/сохраненным параметрам; (справа) чувствительность соединения (CS), измеренная для параметров в каждом слое. Все сети инициализируются с γ = 1,0. В отличие от линейного случая, картина разреженности для сети tanh неравномерна по разным слоям. При сокращении для высокого уровня разреженности (например, κ¯ = 90%) это становится критическим и приводит к плохой способности к обучению, поскольку в более поздних слоях остается лишь несколько параметров. Это объясняется графиком чувствительности соединения, который показывает, что параметры нелинейной сети в более поздних слоях имеют насыщающую более низкую чувствительность соединения, чем в более ранних слоях.

Первый автор: Намхун Ли
Твиттер| ЛинкедИн| Гитхаб| "Веб-сайт"
12. Глубокое полуконтролируемое обнаружение аномалий
Мы представляем Deep SAD, глубокий метод для общего полуконтролируемого обнаружения аномалий, который особенно использует преимущества помеченных аномалий.
(TL;DR, из OpenReview.net)
Бумага | "Код"
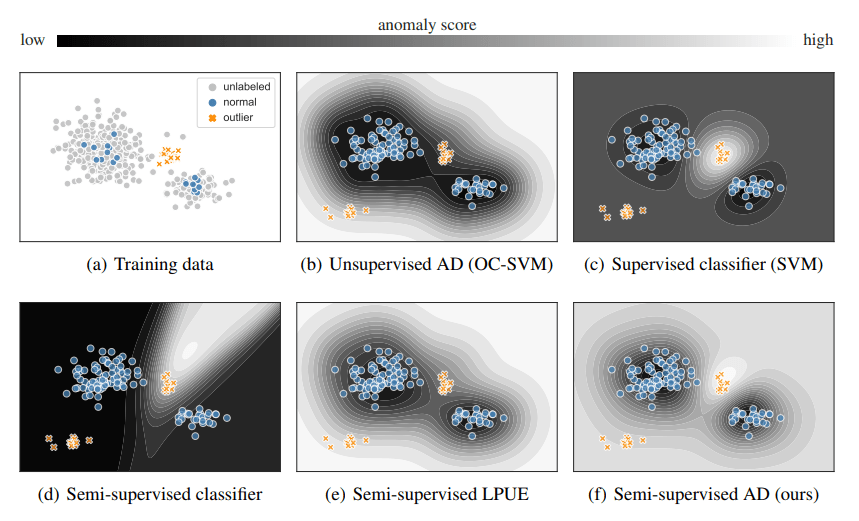
Необходимость полуконтролируемого обнаружения аномалий: обучающие данные (показаны в (а)) состоят из (в основном нормальных) немаркированных данных (серые), а также нескольких помеченных нормальных выборок (синие) и помеченных аномалий (оранжевые). На рисунках (b)–(f) показаны границы принятия решений различных парадигм обучения во время тестирования, а также возникающие новые аномалии (внизу слева на каждом графике). В нашем полуконтролируемом подходе AD используются все обучающие данные: немаркированные образцы, помеченные нормальные образцы, а также помеченные аномалии. Это обеспечивает баланс между одноклассным обучением и классификацией.

Первый автор: Лукас Рафф
13. Обучение многомасштабному представлению пространственных распределений объектов с использованием ячеек сетки.
Мы предлагаем модель обучения представлению под названием Space2vec для кодирования абсолютных положений и пространственных отношений мест.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Задача совместного моделирования распределений с очень разными характеристиками. (a) (b) Места POI (красные точки) в Лас-Вегасе и Space2Vec предсказывали условную вероятность женской одежды (с групповым распределением) и образования (с равномерным распределением). Темная область на (b) указывает на то, что в центре города больше POI других типов, чем образовательные. © Кривые Ripley K для типов POI, для которых Space2Vec имеет наибольшее и наименьшее улучшение по сравнению с wrap (Mac Aodha et al., 2019). Каждая кривая представляет количество POI определенного типа внутри определенных радиостанций с центром в каждой POI этого типа; (d) K-кривые Рипли, перенормированные плотностью POI и показанные в логарифмическом масштабе. Для эффективного достижения многомасштабного представления Space2Vec объединяет кодирование ячеек сетки 64 масштабов (с длинами волн от 50 до 40 000 метров) в качестве первого слоя глубокой модели и тренируется с данными POI без присмотра.

Первый автор: Гэнчен Май
Твиттер | ЛинкедИн | Гитхаб | "Веб-сайт"
14. Федеративное обучение с согласованным усреднением
Эффективное федеративное обучение с послойным сопоставлением.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Сравнение различных методов федеративного обучения с ограниченным количеством сообщений в LeNet, обученных на MNIST; VGG-9 обучен набору данных CIFAR-10; LSTM обучался на наборе данных Шекспира по: (а) однородному разделу данных (б) разнородному разделу данных.

Первый автор: Хонги Ван
15. Chameleon: адаптивная оптимизация кода для ускоренной компиляции глубокой нейронной сети
Обучение с подкреплением и адаптивная выборка для оптимизированной компиляции глубоких нейронных сетей.
(TL;DR, из OpenReview.net)
"Бумага"

Обзор нашего рабочего процесса компиляции модели, и выделен объем этой работы.

Первый автор: Бён Хун Ан
Твиттер | ЛинкедИн | Гитхаб | "Веб-сайт"
16. Деконволюция сети
Мы предлагаем метод, называемый сетевой деконволюцией, который напоминает систему зрения животных, чтобы лучше обучать сверточные сети.
(TL;DR, из OpenReview.net)
Бумага | "Код"

Выполнение свертки на этом изображении реального мира с использованием корреляционного фильтра, такого как ядро Гаусса, добавляет корреляции к результирующему изображению, что затрудняет распознавание объектов. Процесс удаления этого размытия называется деконволюцией. Однако что, если то, что мы видели как изображение реального мира, само по себе было результатом действия какого-то неизвестного корреляционного фильтра, который затруднил распознавание? Предлагаемая нами операция сетевой деконволюции может декоррелировать базовые функции изображения, что позволяет нейронным сетям работать лучше.

Первый автор: Чэнси Е.
Резюме
Глубина и широта публикаций ICLR весьма вдохновляют. Здесь я только что представил верхушку айсберга, сосредоточившись на теме глубокого обучения. Однако данный анализ предполагает, что популярных направлений было немного, а именно:
- Глубокое обучение (описано в этом посте)
- Обучение с подкреплением (здесь)
- Генеративные модели (здесь)
- Обработка/понимание естественного языка (здесь)
Чтобы создать более полный обзор основных статей ICLR, мы создаем серию сообщений, каждое из которых посвящено одной теме, упомянутой выше. Вы можете проверить их для более полного обзора.
Приятного чтения!
Эта статья изначально была написана Камилем Качмареком и размещена в блоге Neptune. Там вы можете найти более подробные статьи для специалистов по машинному обучению.